solr7.1.0学习笔记(6)---配置文件managed-schema(schema.xml)-如何定义字段field
2017-12-29 18:21
375 查看
字段field定义与属性
1、示例-字段定义
以下示例定义了一个类型名为 float 并且默认值为 0.0 的名为 price 的字段;indexed 和 stored 特性明确地设置为 true,而在 float 字段类型上指定的任何其他属性都将被继承。
<field name="price" type="float" default="0.0" indexed="true" stored="true"/>
2、字段属性
字段定义可以具有以下属性:
2.1、name:该字段的名称。字段名称只能由字母数字或下划线字符组成,不能以数字开头。目前这并不是严格执行的,但其他字段名称将不具备所有组件的第一类支持,并且不保证向后的兼容性。带有前导和后缀下划线的名称(例如,_version_)被保留。每个字段都必须有一个name。
2.2、type:该fieldType字段的名称。这将name在fieldType定义的name属性中找到。每个字段都必须有一个type。
2.3、default:将自动添加到在索引时该字段中没有值的任何文档的默认值。如果这个属性没有指定,那么没有默认值。
3、可选的字段类型重写属性
字段可以具有许多与字段类型相同的属性。下表中的属性在单个字段中指定,将重写在字段的 fieldType 上指定的该属性的任何显式值,或者由基础 fieldType 实现所提供的任何隐式默认属性值。下表从字段类型定义和属性转载,其中有更多详细信息:
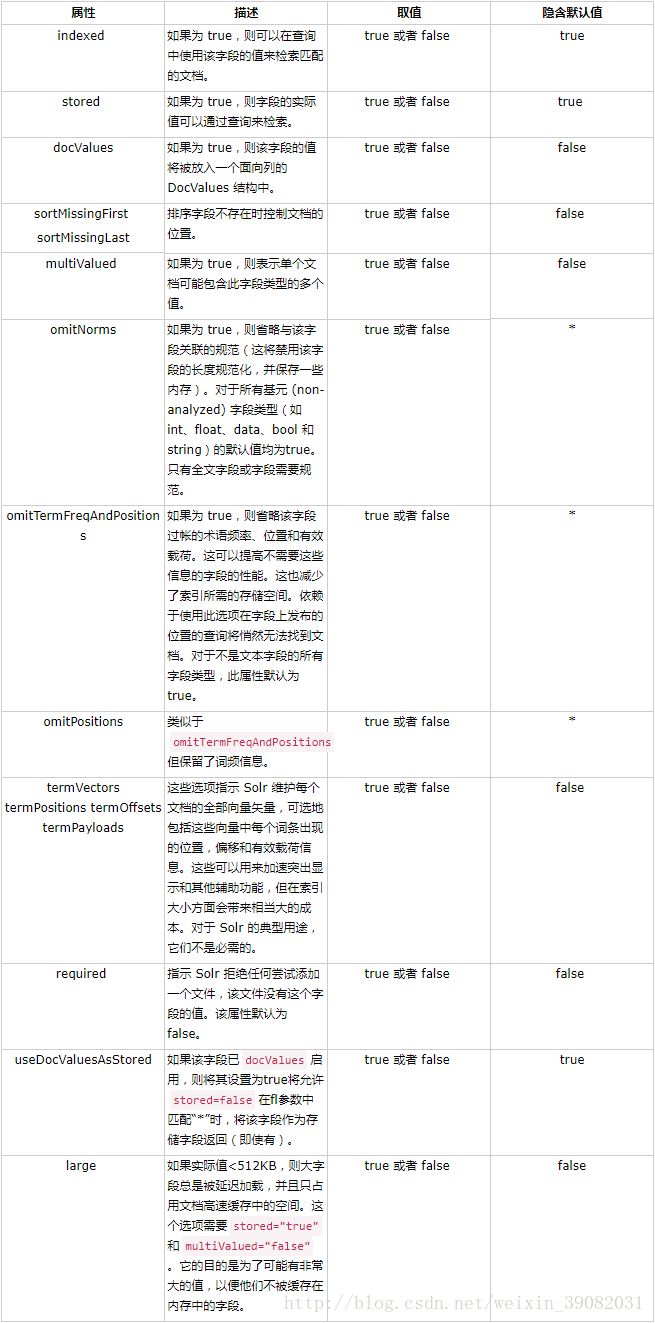
对一些属性的详细点的说明:
omitNorms:
norm是基于document length norm,document boost和field boost计算出的浮点(float)值。这里的boost可以理解为权重。document length norm用于为较小的document增加权重(权重较大的话,计算搜索结果的score值会更高一点)。也就是说如果有一个比较小的document和一个比较长的document都符合搜索条件,Lucene会认为那个较小的document相对于较长的document更新符合搜索条件。omitNorms是指忽略norm,所以设为false时,较小的document和较长的document有相同的权重。因此如果我们需要为某个字段在索引时进行加权(boost),则应该设置为false。当字段类型为基本类型(比如:int,
float,date,bool. string)时此默认值是true。
termVectors, termPositions, termOffsets 和 termPayloads :
此四个属性通常用于 hl.useFastVectorHighlighter为true时的情况,会较大地增加索引大小。
omitTermFreqAndPositions:
如果为TRUE,索引时将忽略频率、位置、负载等信息,这有助于提升不需要这些信息的字段的性能,也会减少索引大小。但是查询如果依赖于字段的位置信息,则会导致查询不到相关document。
上一节:solr7.1.0学习笔记(5)---配置文件managed-schema(schema.xml)-字段类型fieldType的定义和属性
下一节:solr7.1.0学习笔记(7)---配置文件managed-schema(schema.xml)-如何定义动态字段dynamicField和复制字段
1、示例-字段定义
以下示例定义了一个类型名为 float 并且默认值为 0.0 的名为 price 的字段;indexed 和 stored 特性明确地设置为 true,而在 float 字段类型上指定的任何其他属性都将被继承。
<field name="price" type="float" default="0.0" indexed="true" stored="true"/>
2、字段属性
字段定义可以具有以下属性:
2.1、name:该字段的名称。字段名称只能由字母数字或下划线字符组成,不能以数字开头。目前这并不是严格执行的,但其他字段名称将不具备所有组件的第一类支持,并且不保证向后的兼容性。带有前导和后缀下划线的名称(例如,_version_)被保留。每个字段都必须有一个name。
2.2、type:该fieldType字段的名称。这将name在fieldType定义的name属性中找到。每个字段都必须有一个type。
2.3、default:将自动添加到在索引时该字段中没有值的任何文档的默认值。如果这个属性没有指定,那么没有默认值。
3、可选的字段类型重写属性
字段可以具有许多与字段类型相同的属性。下表中的属性在单个字段中指定,将重写在字段的 fieldType 上指定的该属性的任何显式值,或者由基础 fieldType 实现所提供的任何隐式默认属性值。下表从字段类型定义和属性转载,其中有更多详细信息:
对一些属性的详细点的说明:
omitNorms:
norm是基于document length norm,document boost和field boost计算出的浮点(float)值。这里的boost可以理解为权重。document length norm用于为较小的document增加权重(权重较大的话,计算搜索结果的score值会更高一点)。也就是说如果有一个比较小的document和一个比较长的document都符合搜索条件,Lucene会认为那个较小的document相对于较长的document更新符合搜索条件。omitNorms是指忽略norm,所以设为false时,较小的document和较长的document有相同的权重。因此如果我们需要为某个字段在索引时进行加权(boost),则应该设置为false。当字段类型为基本类型(比如:int,
float,date,bool. string)时此默认值是true。
termVectors, termPositions, termOffsets 和 termPayloads :
此四个属性通常用于 hl.useFastVectorHighlighter为true时的情况,会较大地增加索引大小。
omitTermFreqAndPositions:
如果为TRUE,索引时将忽略频率、位置、负载等信息,这有助于提升不需要这些信息的字段的性能,也会减少索引大小。但是查询如果依赖于字段的位置信息,则会导致查询不到相关document。
上一节:solr7.1.0学习笔记(5)---配置文件managed-schema(schema.xml)-字段类型fieldType的定义和属性
下一节:solr7.1.0学习笔记(7)---配置文件managed-schema(schema.xml)-如何定义动态字段dynamicField和复制字段

相关文章推荐
- solr7.1.0学习笔记(7)---配置文件managed-schema(schema.xml)-如何定义动态字段dynamicField和复制字段
- solr7.1.0学习笔记(9)---配置文件managed-schema(schema.xml)-样例
- solr7.1.0学习笔记(8)---配置文件managed-schema(schema.xml)-analyzer,tokenizer
- Solr的学习使用之(二)schema.xml等配置文件的解析
- Solr6.7配置文件 managed-schema (schema.xml) -- 样例(6)
- solr学习(3.2)-Solr配置文件schema.xml和solrconfig.xml分析
- 【学习笔记】Struts2之配置文件struts.xml
- (搜索引擎之solr) schema.xml 配置文件说明
- AndroidManifest.xml 文件配置学习笔记
- solr4.5 schema.xml配置文件
- solr4.5 schema.xml配置文件
- 【solr专题之二】配置文件:solr.xml solrConfig.xml schema.xml
- Struts2 学习笔记——struts.xml文件之拦截器的配置
- Java 学习笔记04:Spring XML配置文件Bean
- hibernate3 学习笔记(二) hibernate 的配置文件 hibernate.cfg.xml
- 【solr专题之二】配置文件:solr.xml solrConfig.xml schema.xml
- 【solr专题之二】配置文件:solr.xml solrConfig.xml schema.xml
- Solr快速回顾3---配置文件schema.xml和solrconfig.xml分析
- Android Google Maps开发笔记:【2】如何配置AndroidManifest.xml文件
- solr schema.xml配置文件的理解