windows下python spark环境搭建
2017-12-28 15:52
381 查看
本环境搭建只是在windows下使用python编写spark程序有提示1、安装python2.7 (省略)下载安装包一直下一步安装即可2、配置spark下载spark-2.2.0-bin-hadoop2.7.tgz 解压到C:\BigData(路径随意)3、配置spark与python环境变量SPARK_HOME:C:\BigData\spark-2.2.0-bin-hadoop2.7PYTHONPATH:%SPARK_HOME%\python\lib\py4j-0.10.4-src.zip;%SPARK_HOME%\python\lib\pyspark.zip4、下载开发工具IntelliJ IDEA在官网下载即可,我下载的解压版,打开IntelliJ IDEA随便创建工程打开FIle-->Settings-->Plugins在搜索框输入 python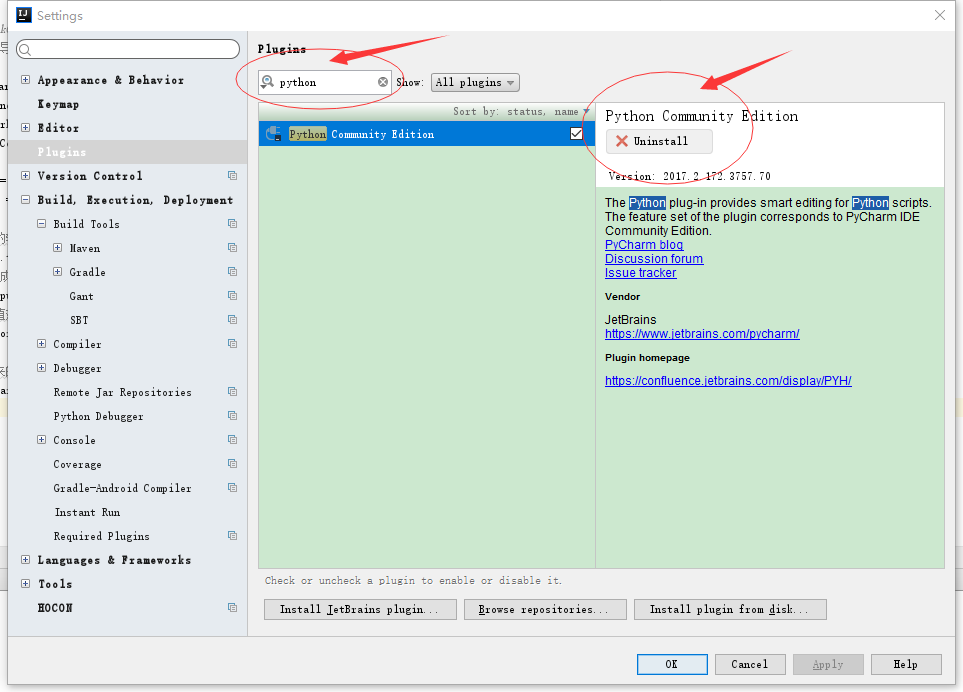 安装后重启软件FIle-->New-->project就可以创建python工程了
安装后重启软件FIle-->New-->project就可以创建python工程了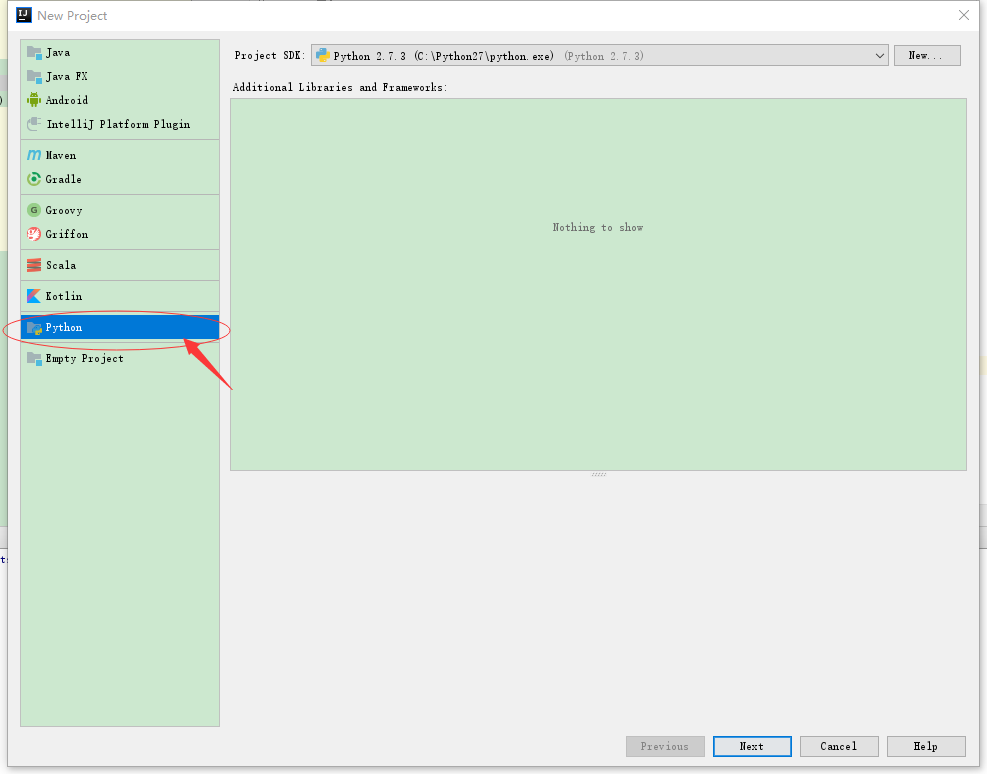 创建工程后新建Python File 名为wordcount.py 内容为
创建工程后新建Python File 名为wordcount.py 内容为
安装后重启软件FIle-->New-->project就可以创建python工程了创建工程后新建Python File 名为wordcount.py 内容为#!/usr/bin/python
# -*- coding: UTF-8 -*-
'''
初始化SparkConf, SparkContext
从pyspark 导入SparkConf, SparkContext
'''
from pyspark import SparkConf, SparkContext
import random
#伪分布模式setMaster直接写local即可,setAppName随便写
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
#HDFS的输入路径
inputFile = "hdfs://192.168.10.101:9000/input/test.txt"
#HDFS的输出目录为防止目录已存在添加了随机数为名
outputFile = "hdfs://192.168.10.101:9000/output" + str(random.randint(10000,1000000))
#读取我们的输入数据
input = sc.textFile(inputFile)
# 把它切分成一个个单词
words = input.flatMap(lambda line: line.split(" "))
#转换为键值对并计数
counts = words.map(lambda
9b62
word: (word, 1)).reduceByKey(lambda a, b: a + b)
#将统计出来的单词总数存入一个文本文件,引发求值
counts.repartition(1).saveAsTextFile(outputFile)wordcount程序就编写好了,传到服务器上进入到spark安装目录的bin下使用./spark-submit /路径/wordcount.py即可运行
运行完成后使用hadoop fs -ls / 或者 hadoop dfs -ls / 查看就能看到output加随机数目录,说明执行成功了(1)fs是文件系统, dfs是分布式文件系统(2)fs > dfs(3)分布式环境情况下,fs与dfs无区别 (4)本地环境中,fs就是本地文件,dfs就不能用了andFS涉及到一个通用的文件系统,可以指向任何的文件系统如local,HDFS等。但是DFS仅是针对HDFS的。那么什么时候用FS呢?可以在本地与hadoop分布式文件系统的交互操作中使用。特定的DFS指令与HDFS有关

相关文章推荐
- windows 7 python spark环境搭建笔记(待续)
- windows 基于docker下的 spark 开发环境搭建
- 【Windows】【Scala + Spark】【Eclipse】单机开发环境搭建 - 及示例程序
- (大数据)转载:Windows下基于eclipse的Spark应用开发环境搭建
- windows和linux下面 搭建python的环境
- Windows平台下Eclipse+Pydev搭建Python环境
- windows 搭建 selenium + python2.7 自动化测试环境
- Selenium+Python windows下环境搭建
- 地铁译:Spark for python developers --- 搭建Spark虚拟环境2
- SPARK--Windows下利用scala for eclipse搭建简易的spark开发环境
- windows环境下编译spark源码和搭建源码调试环境
- Python环境搭建-windows
- windows下python开发环境搭建
- Spark在Windows下的环境搭建
- Python pycharm(windows版本)部署spark环境
- python开发环境搭建——windows
- windows系统下Python环境的搭建
- Eclipse中Python开发环境搭建详细图文教程(Windows环境)
- Windows下怎么搭建Python+Selenium的自动化环境
- pycharm+python+Django之web开发环境的搭建(windows)