机器学习实战第二节 决策树
2017-12-28 14:54
274 查看
度量数据集无序程度的方法:
香农熵 (shannon entropy)
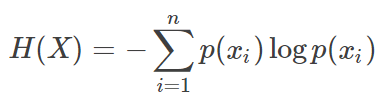
变量的不确定性越大,熵越大
基尼不纯度 (Gini impurity)
从一个数据集中随机选择子项,度量其被错误分类到其他分组里的概率。
递归构造决策树:
得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。采用递归原则处理数据。
递归的结束条件:遍历完所有划分数据集的属性,或者每个分支下的所有实例都有相同的分类。
python实现:
输出:

使用matplotlib注解(annotations)绘制树形图:
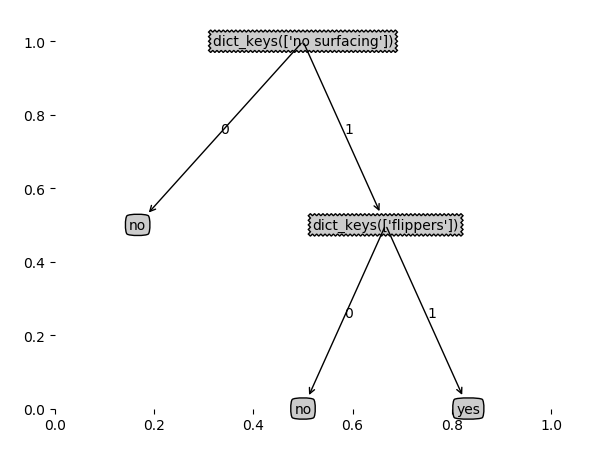
matplotlibannotations
boxstyle参数取值:
arrowstyle参数取值:
应用决策树分类:
______________________________________________________________
python序列化:pickle和jason
pickle
将变量转化为bytes进行存储
pickle是python独有的序列化模块
功能:序列化函数:dump/dumps
反序列化函数:load/loads
dump(var,file)
load(file)
jason
序列化后格式为字符串str
决策树的存储:
香农熵 (shannon entropy)
变量的不确定性越大,熵越大
基尼不纯度 (Gini impurity)
从一个数据集中随机选择子项,度量其被错误分类到其他分组里的概率。
递归构造决策树:
得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。采用递归原则处理数据。
递归的结束条件:遍历完所有划分数据集的属性,或者每个分支下的所有实例都有相同的分类。
python实现:
from math import log
import operator
def create_trees(dataset, labels):
class_list = [example[-1] for example in dataset]
feat_num = len(dataset[0])
# 递归的第二个结束条件:如果所有分支都属于一个类
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
# 递归的第一个结束条件,如果遍历完了特征,返回类别最多的那类
if feat_num == 1:
return majority_count(class_list)
best_feat = choose_best_feature(dataset)
best_feat_label = labels[best_feat]
del(labels[best_feat])
# 返回的best_feat是tuple型,所以取列值只能用这种方式
feat_values = [example[best_feat] for example in dataset]
uniq_feat_values = set(feat_values)
my_tree = {best_feat_label:{}}
for value in uniq_feat_values:
sub_labels = labels[:]
sub_dataset = split_dataset(dataset, best_feat, value)
my_tree[best_feat_label][value] = create_trees(sub_dataset, sub_labels)
return my_tree
def majority_count(class_list):
'''
:param class_list:
:return: 出现次数最多的分类的名称
'''
class_count = {}
for cla in class_list:
if cla not in class_count.keys():
class_count[cla] = 0
class_count[cla] += 1
sorted_list = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_list[0][0]
def choose_best_feature(dataset):
best_entropy = cal_shannon_entropy(da
4000
taset)
best_infogain = 0.0
feature_num = len(dataset[0])
best_feat = -1
for i in range(feature_num):
new_entropy = 0.0
# 获取数据集第i列的值
feat_list = [example[i] for example in dataset]
uniq_feat_list = set(feat_list)
for value in uniq_feat_list:
sub_dataset = split_dataset(dataset, i, value)
prob = len(sub_dataset)/len(dataset)
new_entropy += prob * cal_shannon_entropy(sub_dataset)
info_gain = best_entropy - new_entropy
if info_gain > best_infogain:
best_infogain = info_gain
best_feat = i
return best_feat
def split_dataset(dataset, axis, value):
'''
:param dataset: 需要划分的数据集
:param axis: 划分的特征
:param value: 特征的值
:return:
'''
ret_dataset = []
for vec in dataset:
if vec[axis] == value:
reduced_vec = vec[:axis]
reduced_vec.extend(vec[axis + 1:])
ret_dataset.append(reduced_vec)
return ret_dataset
def cal_shannon_entropy(dataset):
'''
:param dataset: 需要计算香农熵的数据集
:return: 香农熵
'''
shannon_entropy = 0.0
label_count = {}
for vec in dataset:
current_label = vec[-1]
if current_label not in label_count.keys():
label_count[current_label] = 0
label_count[current_label] += 1
for key in label_count:
prob = float(label_count[key])/len(dataset)
shannon_entropy -= prob * log(prob, 2)
return shannon_entropy
def create_dataset():
dataset = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing', 'flippers']
return dataset, labels
dataset, labels = create_dataset()
print(dataset)
my_tree = create_trees(dataset,labels)
print(my_tree)输出:
使用matplotlib注解(annotations)绘制树形图:
import matplotlib.pyplot as plt
decision_node = dict(boxstyle="sawtooth", fc="0.8")
leaf_node = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def create_plot(in_tree):
fig = plt.figure(1, facecolor='white')
fig.clf()
# axprops = dict(plt.xticks[], plt.yticks[])
create_plot.ax1 = plt.subplot(111, frameon=False)
plot_tree.totalW = float(get_leaf_num(in_tree))
plot_tree.totalD = float(get_tree_depth(in_tree))
plot_tree.x_off = -0.5/plot_tree.totalW
plot_tree.y_off = 1.0
plot_tree(in_tree, (0.5, 1.0), '')
plt.show()
def plot_node(node_text, center_pt, parent_pt, node_type):
create_plot.ax1.annotate(node_text, xy=parent_pt, xycoords='axes fraction', xytext=center_pt, \
textcoords='axes fraction', va="center", ha="center",\
bbox=node_type, arrowprops=arrow_args)
def plot_mid_text(cntr_pt, parent_pt, txt_string):
x_mid = (parent_pt[0] - cntr_pt[0])/2.0 + cntr_pt[0]
y_mid = (parent_pt[1] - cntr_pt[1])/2.0 + cntr_pt[1]
create_plot.ax1.text(x_mid, y_mid, txt_string)
def plot_tree(my_tree, parent_pt, node_txt):
leaf_num = get_leaf_num(my_tree)
depth = get_tree_depth(my_tree)
first_str = my_tree.keys()
cntr_pt =(plot_tree.x_off + (1.0 + float(leaf_num))/2.0/plot_tree.totalW,\
plot_tree.y_off)
plot_mid_text(cntr_pt, parent_pt, node_txt)
plot_node(first_str, cntr_pt, parent_pt, decision_node)
second_dict = my_tree[''.join(first_str)]
plot_tree.y_off = plot_tree.y_off - 1.0/plot_tree.totalD
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
plot_tree(second_dict[key], cntr_pt, str(key))
else:
plot_tree.x_off = plot_tree.x_off + 1.0/plot_tree.totalW
plot_node(second_dict[key], (plot_tree.x_off, plot_tree.y_off), cntr_pt, leaf_node)
plot_mid_text((plot_tree.x_off, plot_tree.y_off), cntr_pt, str(key))
plot_tree.y_off = plot_tree.y_off + 1.0/plot_tree.totalD
def retrieve_tree(i):
list_of_tree = [{'no surfacing': {0:'no', 1:{'flippers':{0:'no', 1:'yes'}}}},
{'no surfacing':{0:'no', 1:{'flippers':{0:{'head':{0:'no', 1: 'yes'}}, 1:'no'}}}}]
return list_of_tree[i]
def get_leaf_num(my_tree):
leaf_num = 0
# 因为树只有一个根节点,所以返回只有一个key,但是类型为dict_keys
first_keys = my_tree.keys()
# 转成字符串类型
first_str = ''.join(first_keys)
# 得到第二层树
second_dict = my_tree[first_str]
# 遍历第二层树的key
for key in second_dict.keys():
# 如果值是字典类型,就递归
if type(second_dict[key]).__name__ == 'dict':
leaf_num += get_leaf_num(second_dict[key])
else:
leaf_num += 1
return leaf_num
def get_tree_depth(my_tree):
max_depth = 0
# 因为树只有一个根节点,所以返回只有一个key,但是类型为dict_keys
first_keys = my_tree.keys()
# 转成字符串类型
first_str = ''.join(first_keys)
second_dict = my_tree[first_str]
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
this_depth = 1 + get_tree_depth(second_dict[key])
else:
this_depth = 1
if this_depth > max_depth:
max_depth = this_depth
return max_depth
my_tree = retrieve_tree(0)
print(my_tree)
create_plot(my_tree)matplotlibannotations
boxstyle参数取值:
arrowstyle参数取值:
应用决策树分类:
def classify(input_tree, feat_labels, test_vec):
'''
使用决策树的分类函数
:param input_tree: 输入的决策树
:param feat_labels: 变量标签
:param test_vec: 要测试的变量
:return: 类别
'''
first_str = input_tree.keys()
second_dict = input_tree[''.join(first_str)]
feat_index = feat_labels.index(''.join(first_str))
for key in second_dict.keys():
if test_vec[feat_index] == key:
if type(second_dict[key]).__name__ == 'dict':
class_label = classify(second_dict[key], feat_labels, test_vec)
else:
class_label = second_dict[key]
return class_label
def retrieve_tree(i):
list_of_tree = [{'no surfacing': {0:'no', 1:{'flippers':{0:'no', 1:'yes'}}}},
{'no surfacing':{0:'no', 1:{'flippers':{0:{'head':{0:'no', 1: 'yes'}}, 1:'no'}}}}]
return list_of_tree[i]
dataset, labels = create_dataset()
print(dataset)
my_tree = retrieve_tree(0)
c = classify(my_tree, labels, [1,0])
print(c) # 输出no______________________________________________________________
python序列化:pickle和jason
pickle
将变量转化为bytes进行存储
pickle是python独有的序列化模块
功能:序列化函数:dump/dumps
反序列化函数:load/loads
dump(var,file)
load(file)
jason
序列化后格式为字符串str
决策树的存储:
def store_tree(input_tree, filename): import pickle fw = open(filename, 'w') pickle.dump(input_tree, fw) fw.close() def grab_tree(filename): import pickle fr = open(filename) return pickle.load(fr)

相关文章推荐
- 机器学习实战(二)决策树
- 【10月31日】机器学习实战(二)决策树:隐形眼镜数据集
- 机器学习实战第三章-决策树
- 机器学习实战-3决策树
- [机器学习实战] 决策树ID3算法
- 机器学习实战第三章(决策树)
- 机器学习实战第三章——决策树(源码解析)
- 机器学习实战之一---简单讲解决策树
- 机器学习实战 决策树代码 计算香农熵 Error return arrays must be of ArrayType
- 【机器学习实战】决策树-Python3文件读写错误小结
- 机器学习理论与实战(二)决策树
- 机器学习实战第三章——决策树,读书笔记
- 机器学习实战-决策树
- 机器学习实战——决策树
- 机器学习实战之决策树(1)---ID3算法与信息熵,基尼不纯度
- 机器学习实战第三章,决策树的实现
- 【机器学习实战】决策树预测Titanic遇难者生还情况
- Python机器学习实战-决策树
- 机器学习实战第三章——决策树程序
- 【机器学习实战-python3】决策树ID3