自然语言期末复习笔记—神经网络语言模型NPLM
2017-12-26 12:16
661 查看
这次我们来讲讲神经网络语言模型,我们主要来谈谈为什么要使用神经网络。以及一些关键的点,更详细的内容,比如关于神经网络的结构之类的,就不在这细细讨论了,这方面网上的讨论很多。
用n元语法,我们都知道如何表示一一个词的概率。
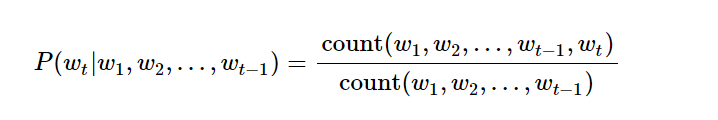
但是用这种方法有他的麻烦,我们都知道理论上,如果我们的n元数越大,结果应该是越精确的,但是实际中这种方法难以实行,原因在于随着我们的n元数增多,我们对数据数量的需求就越高。也就是说我们会面面临数据稀疏问题,举例来说吧。我们想知道 你 中国 后面接着 银行的概率,那我们的样本里面可能出现过很多次中国银行。这样的概率就很好统计,但是如果我们想预测 在北京的中国人民银行很 后面跟着好 的概率,那我们可能就会遇到概率为零的结果。因为我们训练语料里面没有出现这个词。我们训练数据应该尽可能地覆盖样本空间,才能得到一个满意得学习模型,但是随着我们参数维度升高,我们得样本空间指数级升高,而现实中得训练样本就那么多(一般训练样本获得得成本很大),所以在n元语法中,我们有时候会看到,随着n得数量升高,模型得性能反而下降。
以上是基于频率得概率统计得模型,但是如果我们在神经网络中使用n元模型,就可以解决这样得问题,这首先得益于我们对词得向量化表示,同时我们又通过词向量得训练使得意义相近得词他们得向量分布也相似。

这个结构我不打算仔细讲,我在这里只提两点。一个是词向量得训练,一个是基于词性困惑度得训练方法。
首先我们来说受词向量得训练。就如上面所讲,我们希望意义相近的词他们的在空间向量表示上也能够相似。我们开始是对词向量随机表示,而后在随后的训练过程不断地更新词向量,经过训练的词向量,我们会发现,他们的空间向量表示上也较为相似。
比如 我们可能发现 woman 和 female 他们的空间向量结构较为相似,这个也是可以直观解释的,因为woman和female 他们可能经常出现在上下文中有相同的用法,那么我们神经网路就会把这两个词的向量调整到相似,这样以后再出现这样的相近词,我们的概率不会剧烈波动。
词向量单是用用文字描述比较抽象,上代码
以下是pytorch 做word embedding 的介绍


以下是词向量训练的网络结构
CONTEXT_SIZE = 2
EMBEDDING_DIM = 10
We will use Shakespeare Sonnet 2
test_sentence = “”“When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty’s field,
Thy youth’s proud livery so gazed on now,
Will be a totter’d weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv’d thy beauty’s use,
If thou couldst answer ‘This fair child of mine
Shall sum my count, and make my old excuse,’
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel’st it cold.”“”.split()
we should tokenize the input, but we will ignore that for now
build a list of tuples. Each tuple is ([ word_i-2, word_i-1 ], target word)
trigrams = [([test_sentence[i], test_sentence[i + 1]], test_sentence[i + 2])
for i in range(len(test_sentence) - 2)]
print the first 3, just so you can see what they look like
print(trigrams[:3])
vocab = set(test_sentence)
word_to_ix = {word: i for i, word in enumerate(vocab)}
class NGramLanguageModeler(nn.Module):
losses = []
loss_function = nn.NLLLoss()
model = NGramLanguageModeler(len(vocab), EMBEDDING_DIM, CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.001)
for epoch in range(10):
total_loss = torch.Tensor([0])
for context, target in trigrams:
print(losses) # The loss decreased every iteration over the training data!
接下来我们来介绍以下基于词性困惑度的训练方法。
首先我们来了解以下什么是词性困惑度
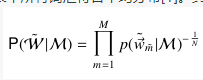
他的公式表示是这样,词性困惑度越小越好,对应的就是概率越大越好。
关于实现部分我看了一些博客和代码,看到都是基于概率最大来计算的。使用的都是 cross entropy loss 的方法。
关于交叉商的介绍,我觉得这篇外国人写得非常赞,真地挺佩服这种非常朴素地传道解惑地人。
Why You Should Use Cross-Entropy Error Instead Of Classification Error Or Mean Squared Error For Neural Network Classifier Training
以上就是关于词向量训练和概率表示地大概内容,写得比较粗糙,有必要得时候再详细更新
用n元语法,我们都知道如何表示一一个词的概率。
但是用这种方法有他的麻烦,我们都知道理论上,如果我们的n元数越大,结果应该是越精确的,但是实际中这种方法难以实行,原因在于随着我们的n元数增多,我们对数据数量的需求就越高。也就是说我们会面面临数据稀疏问题,举例来说吧。我们想知道 你 中国 后面接着 银行的概率,那我们的样本里面可能出现过很多次中国银行。这样的概率就很好统计,但是如果我们想预测 在北京的中国人民银行很 后面跟着好 的概率,那我们可能就会遇到概率为零的结果。因为我们训练语料里面没有出现这个词。我们训练数据应该尽可能地覆盖样本空间,才能得到一个满意得学习模型,但是随着我们参数维度升高,我们得样本空间指数级升高,而现实中得训练样本就那么多(一般训练样本获得得成本很大),所以在n元语法中,我们有时候会看到,随着n得数量升高,模型得性能反而下降。
以上是基于频率得概率统计得模型,但是如果我们在神经网络中使用n元模型,就可以解决这样得问题,这首先得益于我们对词得向量化表示,同时我们又通过词向量得训练使得意义相近得词他们得向量分布也相似。
这个结构我不打算仔细讲,我在这里只提两点。一个是词向量得训练,一个是基于词性困惑度得训练方法。
首先我们来说受词向量得训练。就如上面所讲,我们希望意义相近的词他们的在空间向量表示上也能够相似。我们开始是对词向量随机表示,而后在随后的训练过程不断地更新词向量,经过训练的词向量,我们会发现,他们的空间向量表示上也较为相似。
比如 我们可能发现 woman 和 female 他们的空间向量结构较为相似,这个也是可以直观解释的,因为woman和female 他们可能经常出现在上下文中有相同的用法,那么我们神经网路就会把这两个词的向量调整到相似,这样以后再出现这样的相近词,我们的概率不会剧烈波动。
词向量单是用用文字描述比较抽象,上代码
以下是pytorch 做word embedding 的介绍
以下是词向量训练的网络结构
CONTEXT_SIZE = 2
EMBEDDING_DIM = 10
We will use Shakespeare Sonnet 2
test_sentence = “”“When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty’s field,
Thy youth’s proud livery so gazed on now,
Will be a totter’d weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv’d thy beauty’s use,
If thou couldst answer ‘This fair child of mine
Shall sum my count, and make my old excuse,’
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel’st it cold.”“”.split()
we should tokenize the input, but we will ignore that for now
build a list of tuples. Each tuple is ([ word_i-2, word_i-1 ], target word)
trigrams = [([test_sentence[i], test_sentence[i + 1]], test_sentence[i + 2])
for i in range(len(test_sentence) - 2)]
print the first 3, just so you can see what they look like
print(trigrams[:3])
vocab = set(test_sentence)
word_to_ix = {word: i for i, word in enumerate(vocab)}
class NGramLanguageModeler(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size): super(NGramLanguageModeler, self).__init__() self.embeddings = nn.Embedding(vocab_size, embedding_dim) self.linear1 = nn.Linear(context_size * embedding_dim, 128) self.linear2 = nn.Linear(128, vocab_size) def forward(self, inputs): embeds = self.embeddings(inputs).view((1, -1)) out = F.relu(self.linear1(embeds)) out = self.linear2(out) log_probs = F.log_softmax(out) return log_probs
losses = []
loss_function = nn.NLLLoss()
model = NGramLanguageModeler(len(vocab), EMBEDDING_DIM, CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.001)
for epoch in range(10):
total_loss = torch.Tensor([0])
for context, target in trigrams:
# Step 1. Prepare the inputs to be passed to the model (i.e, turn the words # into integer indices and wrap them in variables) context_idxs = [word_to_ix[w] for w in context] context_var = autograd.Variable(torch.LongTensor(context_idxs)) # Step 2. Recall that torch *accumulates* gradients. Before passing in a # new instance, you need to zero out the gradients from the old # instance model.zero_grad() # Step 3. Run the forward pass, getting log probabilities over next # words log_probs = model(context_var) # Step 4. Compute your loss function. (Again, Torch wants the target # word wrapped in a variable) loss = loss_function(log_probs, autograd.Variable( torch.LongTensor([word_to_ix[target]]))) # Step 5. Do the backward pass and update the gradient loss.backward() optimizer.step() total_loss += loss.data losses.append(total_loss)
print(losses) # The loss decreased every iteration over the training data!
接下来我们来介绍以下基于词性困惑度的训练方法。
首先我们来了解以下什么是词性困惑度
他的公式表示是这样,词性困惑度越小越好,对应的就是概率越大越好。
关于实现部分我看了一些博客和代码,看到都是基于概率最大来计算的。使用的都是 cross entropy loss 的方法。
关于交叉商的介绍,我觉得这篇外国人写得非常赞,真地挺佩服这种非常朴素地传道解惑地人。
Why You Should Use Cross-Entropy Error Instead Of Classification Error Or Mean Squared Error For Neural Network Classifier Training
以上就是关于词向量训练和概率表示地大概内容,写得比较粗糙,有必要得时候再详细更新

相关文章推荐
- 自然语言期末复习笔记—最大熵模型
- tensorflow17《TensorFlow实战Google深度学习框架》笔记-08-02 使用循环神经网络实现语言模型 code
- 自然语言期末复习笔记—Morphological Analysis
- 神经网络自然语言模型的一般化结构形式
- 自然语言期末复习笔记-Formal Grammars Of English
- 自然语言期末复习笔记—最大熵马尔科夫模型MEMM
- 84、循环神经网络实现语言模型
- 84、循环神经网络实现语言模型
- 基于神经网络语言模型的中文新闻文本聚类算法
- 【懒懒的Tensorflow学习笔记三之搭建简单的神经网络模型】
- 牛津大学神经网络语言模型 OxLM 安装及使用
- Hinton神经网络公开课编程题2--神经概率语言模型(NNLM)
- Andrew NG机器学习课程笔记系列之——机器学习之神经网络模型-上(Neural Networks: Representation)
- 神经网络语言模型
- LSTM入门必读:从入门基础到工作方式详解 By 机器之心2017年7月24日 12:57 长短期记忆(LSTM)是一种非常重要的神经网络技术,其在语音识别和自然语言处理等许多领域都得到了广泛的应用
- 神经网络语言模型NNLM模型
- Andrew NG机器学习课程笔记系列之——机器学习之神经网络模型-下(Neural Networks: Representation)
- 斯坦福大学Andrew Ng - 机器学习笔记(3) -- 神经网络模型
- 阅读笔记:深度神经网络模型压缩与加速
- 学习笔记DL003:神经网络第二、三次浪潮,数据量、模型规模,精度、复杂度,对现实世界冲击