基于神经网络语言模型的中文新闻文本聚类算法
2017-04-06 21:26
771 查看
一、新闻文本集
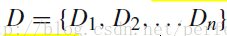
其中
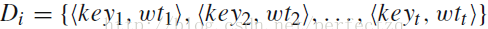
通过TF-IDF排序
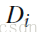
中的词(由大到小),选择其中的
t 个词作为关键字,
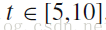
,
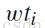
是对应关键字的TF-IDF值。
二、神经网络语言模型
输入:该词的上下文中相邻的几个词向量(词袋模型)
输出:p(wi | context) ,该词的词向量。
通过神经网络语言模型,可以得到新闻词集合 W 中每个词
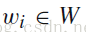
的词向量
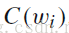
;也就是得到了关键字集合
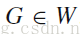
中的每个关键字
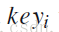
的词向量
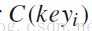
。
三、用模糊的K-means聚类关键字集合
说明:因为每个词可能对应多个文本,所以模糊的K-means是比较合适的算法。初始类别的选择是提高精确度的关键因素。我们能够从关键字集合 G 中选择一个标记的词集 B,每个标记的词代表一个关键字的类别,标记词集B的大小就是聚类的类别数,初始值,就是这些标记的词,用
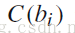
表示,标记词
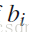
的词向量。(其中的K值,是认为设定的,实验中需要设定不同的值,分析比较,选择最合理的一个K值)
模糊的K-means算法过程如下:
1. 对初始的类别 C1,C2,……CK,用上面的标记的词去表示类别中心,每个标记的词表示一个类别
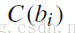
,同时设置一个迭代的次数。
2. 更新
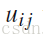
的值,其中
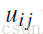
表示词 i 属于类别 j 的概率,在每次迭代中,计算每个关键字属于每个类别的概率,根据下面的公式:
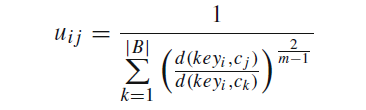
其中的距离的计算公式,用的是余弦距离:
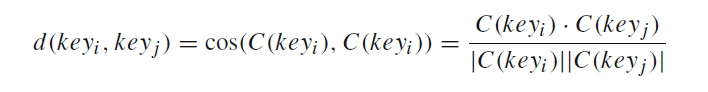
3. 根据每个关键字属于类别
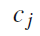
的概率和关键字的词向量,计算该类别的中心。并作为该类别的代表向量:
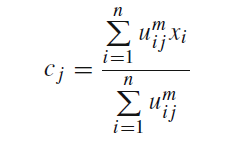
其中的
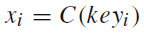
。
4. 如果迭代的次数没有超过第一步设置的值,跳到第2 步,重新执行2-4,否则,停止。
当迭代停止后,得到聚类的结果,其表示形式,每个类别表示一个集合
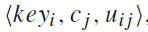
,用语言表示就是关键字
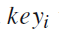
,属于类别
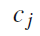
的概率是
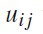
。(文档集的每个关键字都以一定的概率属于每个类别。可能有的概率值为0)
四、基于关键字集的聚类结果的文本聚类
文档集的关键字聚类结果,是文本聚类的基础,根据下面的公式计算每个文档属于每个类别的概率,选择概率最大的类别作为,该文档所属的类别:
4000
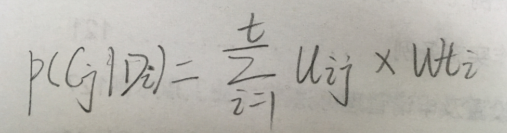
其中的
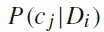
表示文本
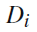
属于类别
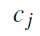
的概率,最后我们得到
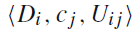
,其中
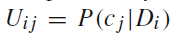
。
五、模型的评估方法
使用准去率和召回率,以及F-measure值,来评价模型
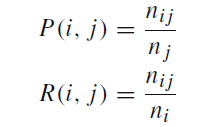
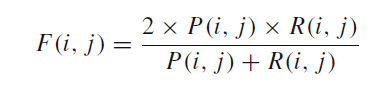
其中的
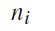
是类别 i 的文本数量;
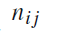
是应该属于类别 j 但是被分到类别 i 的文本数量。
基于神经网络语言模型的中文新闻文本聚类算法的优点:
1.该算法比其他算法(基于LDA)的运行时间快两倍多。
2.每个类别的关键字,能够很好的表示类比的一些属性。
3.适合于处理大规模的中文语料库。
文献:
A Text Clustering Approach of Chinese News Based on Neural Network Language Model
https://link.springer.com/article/10.1007%2Fs10766-014-0329-2
其中
通过TF-IDF排序
中的词(由大到小),选择其中的
t 个词作为关键字,
,
是对应关键字的TF-IDF值。
二、神经网络语言模型
输入:该词的上下文中相邻的几个词向量(词袋模型)
输出:p(wi | context) ,该词的词向量。
通过神经网络语言模型,可以得到新闻词集合 W 中每个词
的词向量
;也就是得到了关键字集合
中的每个关键字
的词向量
。
三、用模糊的K-means聚类关键字集合
说明:因为每个词可能对应多个文本,所以模糊的K-means是比较合适的算法。初始类别的选择是提高精确度的关键因素。我们能够从关键字集合 G 中选择一个标记的词集 B,每个标记的词代表一个关键字的类别,标记词集B的大小就是聚类的类别数,初始值,就是这些标记的词,用
表示,标记词
的词向量。(其中的K值,是认为设定的,实验中需要设定不同的值,分析比较,选择最合理的一个K值)
模糊的K-means算法过程如下:
1. 对初始的类别 C1,C2,……CK,用上面的标记的词去表示类别中心,每个标记的词表示一个类别
,同时设置一个迭代的次数。
2. 更新
的值,其中
表示词 i 属于类别 j 的概率,在每次迭代中,计算每个关键字属于每个类别的概率,根据下面的公式:
其中的距离的计算公式,用的是余弦距离:
3. 根据每个关键字属于类别
的概率和关键字的词向量,计算该类别的中心。并作为该类别的代表向量:
其中的
。
4. 如果迭代的次数没有超过第一步设置的值,跳到第2 步,重新执行2-4,否则,停止。
当迭代停止后,得到聚类的结果,其表示形式,每个类别表示一个集合
,用语言表示就是关键字
,属于类别
的概率是
。(文档集的每个关键字都以一定的概率属于每个类别。可能有的概率值为0)
四、基于关键字集的聚类结果的文本聚类
文档集的关键字聚类结果,是文本聚类的基础,根据下面的公式计算每个文档属于每个类别的概率,选择概率最大的类别作为,该文档所属的类别:
4000
其中的
表示文本
属于类别
的概率,最后我们得到
,其中
。
五、模型的评估方法
使用准去率和召回率,以及F-measure值,来评价模型
其中的
是类别 i 的文本数量;
是应该属于类别 j 但是被分到类别 i 的文本数量。
基于神经网络语言模型的中文新闻文本聚类算法的优点:
1.该算法比其他算法(基于LDA)的运行时间快两倍多。
2.每个类别的关键字,能够很好的表示类比的一些属性。
3.适合于处理大规模的中文语料库。
文献:
A Text Clustering Approach of Chinese News Based on Neural Network Language Model
https://link.springer.com/article/10.1007%2Fs10766-014-0329-2

相关文章推荐
- 基于回归神经网络的中文语句模型实践(Python+Tensorflow+阿里云)
- 基于回归神经网络的中文语句模型实践(Python+Tensorflow+阿里云)
- 基于回归神经网络的中文语句模型实践(Python+Tensorflow+阿里云)
- 基于循环神经网络实现基于字符的语言模型(char-level RNN Language Model)-tensorflow实现
- 基于神经网络的统计语言模型-----第一章 引言
- 基于回归神经网络的中文语句模型实践(Python+Tensorflow+阿里云)
- 基于神经网络的统计语言模型-----第一章 引言
- 基于神经网络的文本意图(intent)识别
- tensorflow17《TensorFlow实战Google深度学习框架》笔记-08-02 使用循环神经网络实现语言模型 code
- 牛津大学神经网络语言模型 OxLM 安装及使用
- Self Organizing Maps (SOM): 一种基于神经网络的聚类算法
- GRNN/PNN:基于GRNN、PNN两神经网络实现并比较鸢尾花种类识别正确率、各个模型运行时间对比—Jason niu
- 一、【word2vec学习路线】神经网络语言模型
- 基于循环神经网络的主题模型
- Keras —— 基于Mnist数据集建立神经网络模型
- 基于JavaScript实现快速转换文本语言(繁体中文和简体中文)
- 几篇神经网络训练语言模型文章的阅读
- 记intel杯比赛中各种bug与debug【其四】:基于长短时记忆神经网络的中文分词的实现
- 《基于语义域语言模型的中文话题关联检测》笔记
- 84、循环神经网络实现语言模型