爬取银行网页数据的项目实战总结
2017-12-23 19:42
393 查看
近期被老师分配了一个任务:按照某一统一规定的格式爬取与银行行业相关的数据,整体来说算是一个工程型的爬虫项目。虽然所需爬取的网页均属于静态网页,没有动态网页这种更折腾的爬虫要求,但是对于我这种之前只写过简单的爬取谷歌图片程序的菜鸡而言,本次项目可以说是基本把静态网页爬取的常用方法都用个遍,我前后也花了近五天去解决这个项目问题,算是投入了一定精力去研究,自己也有些小见解,所以想和大家分享一下。
首先简述一下我本次的爬虫项目最终的数据结果:网页中数据一共有一万条左右,要求分成三张针对不同类型数据的表存储,实际上爬取的数据有九千多条,漏爬了近三百条,此三百条数据中有文本格式、PDF格式、图片格式,最后按照对应的数据格式将漏爬的网页数据分别存储为txt格式、PDF格式、GIF格式。下面我将按着我编写爬虫程序时的思路分块去讲解我的整个爬虫项目的构思:
一、 爬取所需的网页网址
首先附上要爬取网址链接的网页的形式:
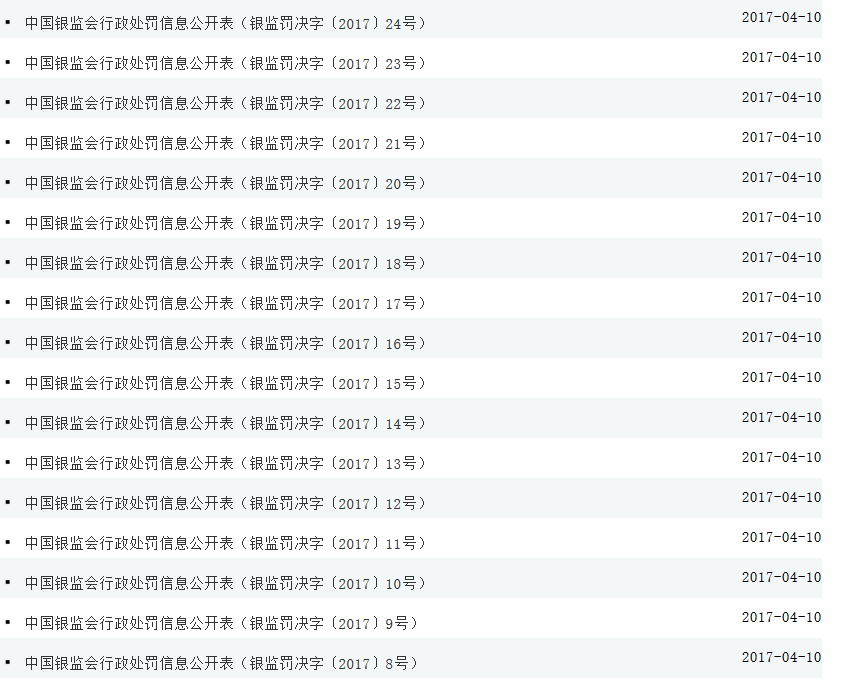
值得一提的是,大多数大型网站尤其用于存储数据的一些网页都是这种方式呈现,左边每行都对应着一个网页的链接,我们可以分析网页源码中关于这些需要爬取的网页链接是否有特殊的形式能够用正则表达式匹配。在此处分析源码时我使用的是FireFox,顺带安利一波Firefox,它用于分析网页源码十分方便,也节省了我许多用于分析源码的时间。只需按下F12,便可以在查看器中查看网页源代码:
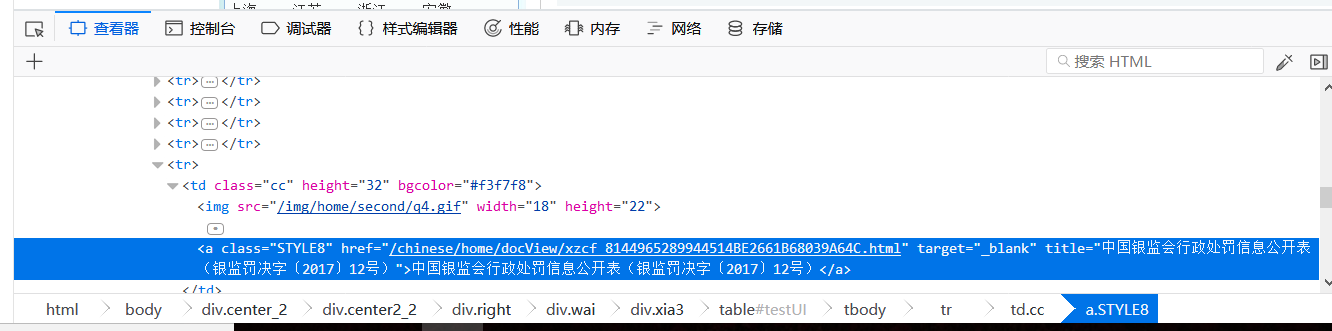
注意此处标蓝的网页源码便是找到的跳转至下一网页的href:其中比较常用的用于匹配网页网址的正则表达式是:href="(.*?.html)",但是在实际爬取中,经常会出现网页中有许多其他额外的网页链接,这时就需要细心分析,一般待爬取的网页链接它都会有额外的属性等用来辅助标识,在本项目中,我很“幸运”地发现我需要爬取的网页链接有一些辅助属性与其他链接不同:target="_blank"
、class="STYLE8,于是我写了用于提取本项目网址的正则匹配式:href="(.*?)"\s*target="_blank".*?class="STYLE8",同时需要提及的是,正则匹配式如果在编写时不确定是否正确,网上有许多在线监测正则匹配的网站用于测试(不然的话正则匹配全部在
4000
程序中验证恐怕要累死了。。。)。本项目中我使用的在线监测正则匹配的网页主要是:https://regex101.com/,当然除了这个在线检测正则匹配的网页,我还辅以使用其他正则检测的网站,主要是该网站的正则检测貌似更新比较慢,有些正确的正则匹配不一定可以被识别,不过online
regex tester这个在线网站算是我尝试的几个在线正则匹配网站中用得最舒服的了~,下面附上检测网址时的匹配情况:
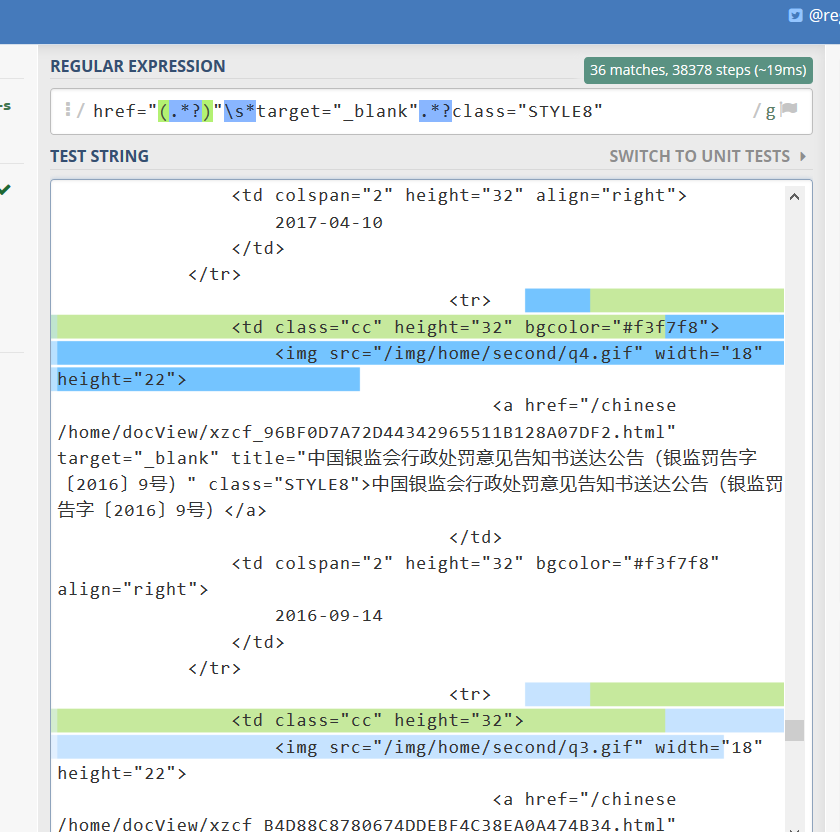
现在,如何从一个网页爬取网页链接的准备工作已经准备好了,我们还需要做的是,程序如何能够做到爬取当前页的数据之后跳转至下一页继续运行爬虫程序:这个地方一般比较容易解决,因为一般网页的跳转都会有个附加的属性,如本项目中的跳转页面网址的页面信息已经被我标识出来,毕竟这种计数页面的方式利于网站管理,当然也利于爬取(暗笑中。。。):

在本项目中,只需要在每页爬取结束后,自动将current+1,就可以进入下一页去爬取网页链接。
最后,需要提及的时,网页一般有防爬机制,但是这种都可以通过构造假的请求头信息骗过网站服务器,详情见下面附上的爬取网页的代码:
二、 提取网页表格中的数据
我们已经获取了每个网页的地址链接,接下来需要做的就是如何提取出网页链接对应的网页内容,这也是本项目中最重要的部分,因为在数据抽取时需要编写许多正则匹配式抽取数据,而正则匹配式一般都不一定是最优的,需要耐心地调试程序,直至找到最合适的正则匹配式。
当然本教程目的是分享大家一些方法,以上提及到不断修改正则匹配式是在工程中需要注意的,但是那些都只是额外花费时间,并没有实质上的技术改变,所以我就精要地阐述下在提取本项目中的网页数据时我所用的方法。
首先附上一张所需爬取的网页的截图:
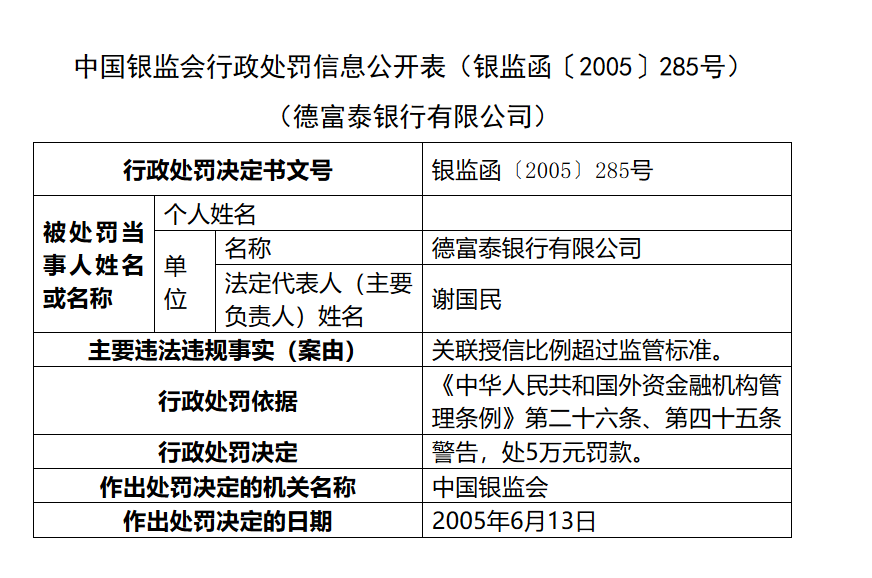
在此项目中我需要提取几个特定的表格单元内的属性值,同时在处罚决定处需要判别为何种处罚类型,如果有罚款,需要注明罚款数额;如此例中,警告就为‘1’,代表处罚属性中有警告,另外罚款就为‘5’,代表罚款为5万元。
当碰到需要爬取的数据为网页表格数据时,我不知道是该庆幸还是悲伤,因为表格数据一般是特定的行与列,就像是我们大家在纸上打格子记录数据时,我们都是习惯特定的表格形式去记录,毕竟这样看着舒服,也方便写入数据,从这个角度来看,爬取表格数据就很轻松,只需要在源码中分析出需要爬取的数据在哪行哪列,专门抽取特定的数据即可。但从另一角度来看,当需要爬取的数据的网站经历了几任网站编程人员维护时,就可能会出现让人崩溃的问题:也许这一任人员喜欢把表格编写成8行8列,另一任人员则喜欢把表格编写成9行10列这种类型,此时就需要编写爬虫程序时不断添加不同格式的处理程序,如此带来的劳动力就比较大了。不过如果爬取的数据不是用于商用这些,即对于爬取的数据的精确度没有特别高的要求时,这些都不是大的问题,但是商用的话,就需要考虑很多问题了,这些我也会在接下来的讲解中穿插着提及到。
当然由于数表格特定的行与列去提取单元格内的数据是比较简单无脑的方法,所以我屈服了,毕竟这样最适合我这种懒得思考的人,所以我傻傻地选择了这种方式提取单元格的数据,主要采用的是Beautiful soup去提取“<tr> <td>”标签,但后来才发现爬取的网页中表格不同行、不同列的组合形式高达六七种,还全是我在不断调试程序时才发现的,期间消耗的人力可想而知。。。
当提取出了特定的表格单元的内容后,如果觉得到现在就结束了,那就太naïve了,因为你需要细心地预处理这些数据,比如去除一些干扰的网页空白字符、去除html中的注释符号、去除网页中出现的特殊字符等这些都需要剔除掉,不然爬出的数据由于编码问题会看着很难受甚至会因为编码问题无法写入文件中。此处先附上我的数据预处理段的代码:
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_list_1 = pre.sub('',soup_list_1)
soup_list_2 = pre.sub('',soup_list_2)
soup_list_3 = pre.sub('',soup_list_3)
soup_list_4 = pre.sub('',soup_list_4)
soup_list_5 = pre.sub('',soup_list_5)
soup_list_6 = pre.sub('',soup_list_6)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_list_1 =delete.sub('',soup_list_1)
soup_list_2 =delete.sub('',soup_list_2)
soup_list_3 =delete.sub('',soup_list_3)
soup_list_4 = delete.sub('',soup_list_4)
soup_list_5 =delete.sub('',soup_list_5)
soup_list_6 =delete.sub('',soup_list_6)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_list_1 = pre_1.sub(',',soup_list_1)
soup_list_2 = pre_1.sub(',',soup_list_2)
soup_list_3 = pre_1.sub(',',soup_list_3)
soup_list_4 = pre_1.sub(',',soup_list_4)
soup_list_5 = pre_1.sub(',',soup_list_5)
soup_list_6 = pre_1.sub(',',soup_list_6)
string_list_1 = re.findall(PATTERN,soup_list_1)
string_list_2 = re.findall(PATTERN,soup_list_2)
string_list_3 = re.findall(PATTERN,soup_list_3)
string_list_4 = re.findall(PATTERN,soup_list_4)
string_list_5 = re.findall(PATTERN,soup_list_5)
string_list_6 = re.findall(PATTERN,soup_list_6)
content_1 = ''.join(string_list_1)#转化为字符串
content_2 = ''.join(string_list_2)
content_3 = ''.join(string_list_3)
content_4 = ''.join(string_list_4)
content_5 = ''.join(string_list_5)
content_6 = ''.join(string_list_6)
strinfo = re.compile('\xa0')#去除特定的字符
content_1 = strinfo.sub(' ',content_1)
content_2 = strinfo.sub(' ',content_2)
content_3 = strinfo.sub(' ',content_3)
content_4 = strinfo.sub(' ',content_4)
content_5 = strinfo.sub(' ',content_5)
content_6 = strinfo.sub(' ',content_6)
最后附上爬取网页表格数据的代码(其中含有许多匹配网页数据的正则匹配式,针对我这个项目,可以选择性地看):
#*************************************#
#*** python 爬取网页表格数据 ****#
#*** Author wobeatit ****#
#*** Python 版本:3.6.2 **************#
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
import re
import time
from bs4 import BeautifulSoup as bs
import os #os模块与文本操作直接相关的模块
#*********下面三句代码作用为了防止出现编码问题*********
import importlib
import sys
importlib.reload(sys)
#****************************************************
BASE_URL = 'http://www.cbrc.gov.cn/chinese/home/docView/560CFEC039224796BFC85F6072F16173.html'
#为爬虫添加一个伪装的头部
FAKE_HEADER={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER'}
PATTERN = '>(.*?)<'#将提取的标签内容中的标签均去除
PATTERN_1 = '(取消)' #统计是否取消高管任职资格
PATTERN_2 = '(罚款|罚没|处罚)'#统计是否属于罚款
PATTERN_3 = '(警告)'#统计行政处罚是否属于警告
PATTERN_4 = '(\d*\.*\d*)万'#统计罚款的数额,是否为万元单位
PATTERN_4_Chinese='[给予|罚款|处].*?([一;二;三;四;五;六;七;八;九;十;壹;贰;叁;伍;拾;百;两;肆;捌].*)万元' #对于中文的数字进行匹配
PATTERN_5 = '(\d*,*\d*\.*\d*)元'#统计罚款的数额,是否为元单位
PATTERN_6 = '(\d*\.*\d*)美元'#统计罚款的数额,是否为美元单位
PATTERN_7 = '(禁止)' #统计是否被禁止从业
PATTERN_8= '(纪律处分)' #统计是否违纪
PATTERN_9= '(吊销)' #统计是否被吊销营业证
class Crawler:
#初始化
def __init__(self, base_url=BASE_URL, header=FAKE_HEADER):
self.base_url = base_url
self.headers = header
def grab_page_content(self):
response = requests.get(url=self.base_url,headers=self.headers) #将网址修改指向下一个页面
doc = response.text
soup = bs(doc,"html.parser")
#print(soup)
if(soup.find('table',{'class':'MsoNormalTable'})):
soup_all=soup.find('table',{'class':'MsoNormalTable'})
elif(soup.find('table',{'class':'MsoTableGrid'})):
soup_all=soup.find('table',{'class':'MsoTableGrid'})
elif(soup.find('div',{'Section0'})):
soup_all=soup.find('div',{'Section0'})
else:
soup_all=''
soup_list=soup_all.find_all('tr')
length_tr=len(soup_list)
print(length_tr)
url_1=self.base_url
self.solve_diff_lentgh(soup_list,url_1,length_tr)
def Chinese_conv_to_math(self,money_1):#利用正则表达式将中文字符转化为数字
one = re.compile('一')
one_1=re.compile('壹')
two = re.compile('二')
two_1=re.compile('贰')
two_2=re.compile('两')
three = re.compile('三')
three_1=re.compile('叁')
four = re.compile('四')
four_1 = re.compile('肆')
five = re.compile('五')
five_1 = re.compile('伍')
six = re.compile('六')
seven = re.compile('七')
eight = re.compile('八')
eight_1 = re.compile('捌')
nine = re.compile('九')
ten = re.compile('十')
ten_1=re.compile('拾')
hundred=re.compile('百')
money = one.sub('1',money_1)
money = one_1.sub('1',money)
money = two.sub('2',money)
money = two_1.sub('2',money)
money = two_2.sub('2',money)
money = three.sub('3',money)
money = three_1.sub('3',money)
money = four.sub('4',money)
money = four_1.sub('4',money)
money = five.sub('5',money)
money = five_1.sub('5',money)
money = six.sub('6',money)
money = seven.sub('7',money)
money = eight.sub('8',money)
money = eight_1.sub('8',money)
money = nine.sub('9',money)
money = ten.sub('0',money)
money = ten_1.sub('0',money)
money=hundred.sub('000',money)
money=str(money)
#print(money)
if(len(money)==7):
money=money=int(money[0:3])+int(money[4:6])+int(money[len(money)-1])
money=str(money)
elif(len(money)==6):
money=int(money[0:3])+int(money[4:6])
money=str(money)
elif(len(money)==4):
money=int(money[0:3])
money=str(money)
elif(len(money)==3):
money=int(money[0:2])+int(money[len(money)-1])
money=str(money)
elif((len(money)==2)&(money[0]=='0')):
money=10+int(money[1])
money=str(money)
elif(money[0]=='0'):
money='10'
return money
def solve_diff_lentgh(self,soup_list,url_1,length_tr):
if length_tr==8:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[1].find_all('td')[1])
soup_list_3=str(soup_list[3].find_all('td')[1])
soup_list_4=str(soup_list[4].find_all('td')[1])
soup_list_5=str(soup_list[5].find_all('td')[1])
soup_list_6=str(soup_list[7].find_all('td')[1])
elif length_tr==9:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[2].find_all('td')[2])
soup_list_3=str(soup_list[4].find_all('td')[1])
soup_list_4=str(soup_list[5].find_all('td')[1])
soup_list_5=str(soup_list[6].find_all('td')[1])
soup_list_6=str(soup_list[8].find_all('td')[1])
elif length_tr==10:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[3].find_all('td')[1])
soup_list_3=str(soup_list[5].find_all('td')[1])
soup_list_4=str(soup_list[6].find_all('td')[1])
soup_list_5=str(soup_list[7].find_all('td')[1])
soup_list_6=str(soup_list[9].find_all('td')[1])
elif length_tr==11:
soup_list_1=str(soup_list[1].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[3].find_all('td')[2])
soup_list_3=str(soup_list[5].find_all('td')[1])
soup_list_4=str(soup_list[6].find_all('td')[1])
soup_list_5=str(soup_list[7].find_all('td')[1])
soup_list_6=str(soup_list[9].find_all('td')[1])
elif length_tr==12:
soup_list_1=str(soup_list[3].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[5].find_all('td')[2])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str
10f34
(soup_list[11].find_all('td')[1])
elif length_tr==13:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[4].find_all('td')[1])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str(soup_list[11].find_all('td')[1])
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_list_1 = pre.sub('',soup_list_1)
soup_list_2 = pre.sub('',soup_list_2)
soup_list_3 = pre.sub('',soup_list_3)
soup_list_4 = pre.sub('',soup_list_4)
soup_list_5 = pre.sub('',soup_list_5)
soup_list_6 = pre.sub('',soup_list_6)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_list_1 = delete.sub('',soup_list_1)
soup_list_2 = delete.sub('',soup_list_2)
soup_list_3 = delete.sub('',soup_list_3)
soup_list_4 = delete.sub('',soup_list_4)
soup_list_5 = delete.sub('',soup_list_5)
soup_list_6 = delete.sub('',soup_list_6)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_list_1 = pre_1.sub(',',soup_list_1)
soup_list_2 = pre_1.sub(',',soup_list_2)
soup_list_3 = pre_1.sub(',',soup_list_3)
soup_list_4 = pre_1.sub(',',soup_list_4)
soup_list_5 = pre_1.sub(',',soup_list_5)
soup_list_6 = pre_1.sub(',',soup_list_6)
string_list_1 = re.findall(PATTERN, soup_list_1)
string_list_2 = re.findall(PATTERN, soup_list_2)
string_list_3 = re.findall(PATTERN, soup_list_3)
string_list_4 = re.findall(PATTERN, soup_list_4)
string_list_5 = re.findall(PATTERN, soup_list_5)
string_list_6 = re.findall(PATTERN, soup_list_6)
#print(doc)
content_1 = ''.join(string_list_1)#转化为字符串
content_2 = ''.join(string_list_2)
content_3 = ''.join(string_list_3)
content_4 = ''.join(string_list_4)
content_5 = ''.join(string_list_5)
content_6 = ''.join(string_list_6)
strinfo = re.compile('\xa0')
content_1 = strinfo.sub(' ',content_1)
content_2 = strinfo.sub(' ',content_2)
content_3 = strinfo.sub(' ',content_3)
content_4 = strinfo.sub(' ',content_4)
content_5 = strinfo.sub(' ',content_5)
content_6 = strinfo.sub(' ',content_6)
print(content_5)
line=[]
content_1=content_1+','
line.append(content_1)
content_2=content_2+','
line.append(content_2)
content_3=content_3+','
line.append(content_3)
content_4=content_4+','
line.append(content_4)
content_6=content_6+','
content_5_raw=content_5+','
line.append(content_5_raw)
if re.findall(PATTERN_2,content_5):
if re.findall(PATTERN_4_Chinese,content_5):
money_list=re.findall(PATTERN_4_Chinese,content_5)
#print(money_list)
money_1=money_list[len(money_list)-1]
money=self.Chinese_conv_to_math(money_1)
#yuan=float(money)
#yuan=yuan/10
content_5_1=money+','
line.append(content_5_1)
elif re.findall(PATTERN_4,content_5):
money_list=re.findall(PATTERN_4,content_5)
int_list=[]
for i in money_list:
int_list.append(float(i))
content_5_1=str(max(int_list))+','
line.append(content_5_1)
#print('罚款:万元')
elif re.findall(PATTERN_6,content_5):
money_list=re.findall(PATTERN_6,content_5)
dollar=float(money_list[len(money_list)-1])
dollar=dollar*6.6/10000
content_5_1=str(dollar)+','
line.append(content_5_1)
#print('罚款:美元')
elif re.findall(PATTERN_5,content_5):
money_list=re.findall(PATTERN_5,content_5)
delete = re.compile(',')
money = delete.sub('',str(money_list[len(money_list)-1]))
yuan=float(money)
yuan=yuan/10000
content_5_1=str(yuan)+','
line.append(content_5_1)
#print('罚款:元')
else:
content_5_1=' ,'
line.append(content_5_1)
else:
content_5_1=' ,'
line.append(content_5_1)
if re.findall(PATTERN_3,content_5):
content_5_2='1,'
line.append(content_5_2)
else:
content_5_2=' ,'
line.append(content_5_2)
if re.findall(PATTERN_8,content_5):
content_5_2_1='1,'
line.append(content_5_2_1)
else:
content_5_2_1 = ' ,'
line.append(content_5_2_1)
if re.findall(PATTERN_1,content_5):
content_5_3='1,'
line.append(content_5_3)
else:
content_5_3=' ,'
line.append(content_5_3)
if re.findall(PATTERN_7,content_5):
content_5_4=' ,1,'
line.append(content_5_4)
else:
content_5_4=' , ,'
line.append(content_5_4)
if re.findall(PATTERN_9,content_5):
content_5_5='1,'
line.append(content_5_5)
else:
content_5_5=' ,'
line.append(content_5_5)
content_5_after=' ,'
line.append(content_5_after)
line.append(content_6)
content_7=url_1+','
line.append(content_7)
print(line)
self.write_to_ducument(line) #将爬取的数据都写入txt文件中,以逗号隔开,最后可以转成csv格式
def write_to_ducument(self,line):
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
path='1.txt'
f=open(path,'a')
line_1=''.join(line)
f.write('\n'+line_1)
def run(self):
self.grab_page_content() #运行抓取网址的程序
if __name__ == '__main__':
craw = Crawler()
craw.run()
三、 完整爬虫的程序
至此爬虫的基本流程已经叙述完毕了,现在来看,em,还蛮简单的,当然简单归简单,最重要的是亲手实践,因为有些坑只有自己亲自踩过才会知道问题所在。
现在大致梳理一下整个流程:首先爬取网页的地址,然后通过获取的网页链接爬取其中的网页数据,按照要求的格式利用正则匹配式去处理网页数据,最后将这两大块合在一起编写总程序,当然需要注意的是,在主程序中应有异常处理,用于存储漏爬的页码、网页链接,用于接下来的漏爬数据处理程序的编写,首先附上主程序代码:
#*************************************#
#*** python 爬取网页数据主程序 ****#
#*** Author wobeatit ****#
#*** Python 版本:3.6.2 **************#
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
import re
from bs4 import BeautifulSoup as bs
import os #os模块与文本操作直接相关的模块
#*********下面三句代码作用不详,就是为了防止出现编码问题*********
import importlib
import sys
importlib.reload(sys)
#****************************************************
BASE_URL = 'http://www.cbrc.gov.cn/zhuanti/xzcf/get2and3LevelXZCFDocListDividePage//2.html'
FAKE_HEADER={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER'}
PATTERN_MAIN = 'href="(.*?)"\s*target="_blank".*?class="STYLE8"' #\s是对空白字符的正则匹配
PATTERN = '>(.*?)<'#将提取的标签内容中的标签均去除
PATTERN_1 = '(取消)' #统计是否取消高管任职资格
PATTERN_2 = '(罚款|罚没|处罚)'#统计是否属于罚款
PATTERN_3 = '(警告)'#统计行政处罚是否属于警告
PATTERN_4 = '(\d*\.*\d*)万'#统计罚款的数额,是否为万元单位
PATTERN_4_Chinese='[给予|罚款|处].*?([一;二;三;四;五;六;七;八;九;十;壹;贰;两;叁;肆;伍;柒;捌;拾;百].*)万元' #对于中文的数字进行匹配
PATTERN_5 = '(\d*,*\d*\.*\d*)元'#统计罚款的数额,是否为元单位
PATTERN_6 = '(\d*\.*\d*)美元'#统计罚款的数额,是否为美元单位
PATTERN_7 = '(禁止)' #统计是否被禁止从业
PATTERN_8= '(纪律处分)' #统计是否违纪
PATTERN_9= '(吊销)' #统计是否被吊销营业证
class Crawler:
#初始化
def __init__(self, base_url=BASE_URL, header=FAKE_HEADER, start_page=136):
self.base_url = base_url
self.start_page = start_page
self.headers = header
def fetch_url(self):
while (self.start_page<222): #设置总页面数的大小
response = requests.get(url=self.base_url + '?current={}'.format(self.start_page),headers=self.headers) #将网址修改指向下一个页面
doc = response.text
url_list = re.findall(PATTERN_MAIN, doc)
print('Now working on page {}'.format(self.start_page)) #打印当前爬取所在页面的页面数
print(len(url_list))
self.grab_page_content(url_list)
self.start_page += 1
print("over!")
def grab_page_content(self,url_list):
i=0
for item in url_list:
i=i+1
url_1='http://www.cbrc.gov.cn'+item
try:
response=requests.get(url=url_1,headers=self.headers) #读出列表中存储的网址
doc = response.text
soup = bs(doc,"html.parser")
#print(soup)
if(soup.find('table',{'class':'MsoNormalTable'})):
soup_all=soup.find('table',{'class':'MsoNormalTable'})
elif(soup.find('table',{'class':'MsoTableGrid'})):
soup_all=soup.find('table',{'class':'MsoTableGrid'})
elif(soup.find('div',{'Section0'})):
soup_all=soup.find('div',{'Section0'})
else:
soup_all=''
soup_list=soup_all.find_all('tr')
length_tr=len(soup_list)
#print(length_tr)
self.solve_diff_lentgh(soup_list,url_1,length_tr)
except:
error_1='第'+str(self.start_page)+'页 '+'第'+str(i)+'条 '+url_1
self.write_to_ducument_error(error_1)
continue
def Chinese_conv_to_math(self,money_1):#利用正则表达式将中文字符转化为数字
one = re.compile('一')
one_1=re.compile('壹')
two = re.compile('二')
two_1=re.compile('贰')
two_2=re.compile('两')
three = re.compile('三')
three_1=re.compile('叁')
four = re.compile('四')
four_1 = re.compile('肆')
five = re.compile('五')
five_1 = re.compile('伍')
six = re.compile('六')
seven = re.compile('七')
seven_1 = re.compile('柒')
eight = re.compile('八')
eight_1 = re.compile('捌')
nine = re.compile('九')
ten = re.compile('十')
ten_1=re.compile('拾')
hundred=re.compile('百')
money = one.sub('1',money_1)
money = one_1.sub('1',money)
money = two.sub('2',money)
money = two_1.sub('2',money)
money = two_2.sub('2',money)
money = three.sub('3',money)
money = three_1.sub('3',money)
money = four.sub('4',money)
money = four_1.sub('4',money)
money = five.sub('5',money)
money = five_1.sub('5',money)
money = six.sub('6',money)
money = seven.sub('7',money)
money = seven_1.sub('7',money)
money = eight.sub('8',money)
money = eight_1.sub('8',money)
money = nine.sub('9',money)
money = ten.sub('0',money)
money = ten_1.sub('0',money)
money=hundred.sub('000',money)
money=str(money)
#print(money)
if(len(money)==7):
money=money=int(money[0:3])+int(money[4:6])+int(money[len(money)-1])
money=str(money)
elif(len(money)==6):
money=int(money[0:3])+int(money[4:6])
money=str(money)
elif(len(money)==4):
money=int(money[0:3])
money=str(money)
elif(len(money)==3):
money=int(money[0:2])+int(money[len(money)-1])
money=str(money)
elif((len(money)==2)&(money[0]=='0')):
money=10+int(money[1])
money=str(money)
elif(money[0]=='0'):
money='10'
return money
def solve_diff_lentgh(self,soup_list,url_1,length_tr):
if length_tr==8:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[1].find_all('td')[2])
soup_list_3=str(soup_list[3].find_all('td')[1])
soup_list_4=str(soup_list[4].find_all('td')[1])
soup_list_5=str(soup_list[5].find_all('td')[1])
soup_list_6=str(soup_list[7].find_all('td')[1])
elif length_tr==9:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[2].find_all('td')[2])
soup_list_3=str(soup_list[4].find_all('td')[1])
soup_list_4=str(soup_list[5].find_all('td')[1])
soup_list_5=str(soup_list[6].find_all('td')[1])
soup_list_6=str(soup_list[8].find_all('td')[1])
elif length_tr==10:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[3].find_all('td')[1])
soup_list_3=str(soup_list[5].find_all('td')[1])
soup_list_4=str(soup_list[6].find_all('td')[1])
soup_list_5=str(soup_list[7].find_all('td')[1])
soup_list_6=str(soup_list[9].find_all('td')[1])
elif length_tr==11:
soup_list_1=str(soup_list[2].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[4].find_all('td')[2])
soup_list_3=str(soup_list[6].find_all('td')[1])
soup_list_4=str(soup_list[7].find_all('td')[1])
soup_list_5=str(soup_list[8].find_all('td')[1])
soup_list_6=str(soup_list[10].find_all('td')[1])
elif length_tr==12:
soup_list_1=str(soup_list[3].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[5].find_all('td')[2])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str(soup_list[11].find_all('td')[1])
elif length_tr==13:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[4].find_all('td')[1])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str(soup_list[11].find_all('td')[1])
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_list_1 = pre.sub('',soup_list_1)
soup_list_2 = pre.sub('',soup_list_2)
soup_list_3 = pre.sub('',soup_list_3)
soup_list_4 = pre.sub('',soup_list_4)
soup_list_5 = pre.sub('',soup_list_5)
soup_list_6 = pre.sub('',soup_list_6)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_list_1 = delete.sub('',soup_list_1)
soup_list_2 = delete.sub('',soup_list_2)
soup_list_3 = delete.sub('',soup_list_3)
soup_list_4 = delete.sub('',soup_list_4)
soup_list_5 = delete.sub('',soup_list_5)
soup_list_6 = delete.sub('',soup_list_6)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_list_1 = pre_1.sub(',',soup_list_1)
soup_list_2 = pre_1.sub(',',soup_list_2)
soup_list_3 = pre_1.sub(',',soup_list_3)
soup_list_4 = pre_1.sub(',',soup_list_4)
soup_list_5 = pre_1.sub(',',soup_list_5)
soup_list_6 = pre_1.sub(',',soup_list_6)
string_list_1 = re.findall(PATTERN, soup_list_1)
string_list_2 = re.findall(PATTERN, soup_list_2)
string_list_3 = re.findall(PATTERN, soup_list_3)
string_list_4 = re.findall(PATTERN, soup_list_4)
string_list_5 = re.findall(PATTERN, soup_list_5)
string_list_6 = re.findall(PATTERN, soup_list_6)
#print(doc)
content_1 = ''.join(string_list_1)#转化为字符串
content_2 = ''.join(string_list_2)
content_3 = ''.join(string_list_3)
content_4 = ''.join(string_list_4)
content_5 = ''.join(string_list_5)
content_6 = ''.join(string_list_6)
strinfo = re.compile('\xa0')
content_1 = strinfo.sub(' ',content_1)
content_2 = strinfo.sub(' ',content_2)
content_3 = strinfo.sub(' ',content_3)
content_4 = strinfo.sub(' ',content_4)
content_5 = strinfo.sub(' ',content_5)
content_6 = strinfo.sub(' ',content_6)
#print(content_1)
#print(content_2)
#print(content_3)
print(content_5)
line=[]
content_1=content_1+','
line.append(content_1)
content_2=content_2+','
line.append(content_2)
content_3=content_3+','
line.append(content_3)
content_4=content_4+','
line.append(content_4)
content_6=content_6+','
content_5_raw=content_5+','
line.append(content_5_raw)
if re.findall(PATTERN_2,content_5):
if re.findall(PATTERN_4_Chinese,content_5):
money_list=re.findall(PATTERN_4_Chinese,content_5)
#print(money_list)
money_1=money_list[len(money_list)-1]
money=self.Chinese_conv_to_math(money_1)
content_5_1=money+','
line.append(content_5_1)
elif re.findall(PATTERN_4,content_5):
money_list=re.findall(PATTERN_4,content_5)
int_list=[]
for i in money_list:
int_list.append(float(i))
content_5_1=str(max(int_list))+','
line.append(content_5_1)
#print('罚款:万元')
elif re.findall(PATTERN_6,content_5):
money_list=re.findall(PATTERN_6,content_5)
dollar=float(money_list[len(money_list)-1])
dollar=dollar*6.6/10000
content_5_1=str(dollar)+','
line.append(content_5_1)
#print('罚款:美元')
elif re.findall(PATTERN_5,content_5):
money_list=re.findall(PATTERN_5,content_5)
delete = re.compile(',')
money = delete.sub('',str(money_list[len(money_list)-1]))
yuan=float(money)
yuan=yuan/10000
content_5_1=str(yuan)+','
line.append(content_5_1)
#print('罚款:元')
else:
content_5_1=' ,'
line.append(content_5_1)
else:
content_5_1=' ,'
line.append(content_5_1)
if re.findall(PATTERN_3,content_5):
content_5_2='1,'
line.append(content_5_2)
else:
content_5_2=' ,'
line.append(content_5_2)
if re.findall(PATTERN_8,content_5):
content_5_2_1='1,'
line.append(content_5_2_1)
else:
content_5_2_1 = ' ,'
line.append(content_5_2_1)
if re.findall(PATTERN_1,content_5):
content_5_3='1,'
line.append(content_5_3)
else:
content_5_3=' ,'
line.append(content_5_3)
if re.findall(PATTERN_7,content_5):
content_5_4=' ,1,'
line.append(content_5_4)
else:
content_5_4=' , ,'
line.append(content_5_4)
if re.findall(PATTERN_9,content_5):
content_5_5='1,'
line.append(content_5_5)
else:
content_5_5=' ,'
line.append(content_5_5)
content_5_after=' ,'
line.append(content_5_after)
line.append(content_6)
content_7=url_1+','
line.append(content_7)
self.write_to_ducument(line)
def write_to_ducument(self,line):
#print('正在写入文件...')
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
path='grab_3.txt'
f=open(path,'a')
line_1=''.join(line)
f.write('\n'+line_1)
def write_to_ducument_error(self,error):
#print('正在写入文件...')
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
path='error_3.txt'
f=open(path,'a')
f.write('\n'+error)
def run(self):
self.fetch_url() #运行抓取网址的程序
if __name__ == '__main__':
craw = Crawler()
craw.run()
四、 漏爬数据的处理
至此,网页数据爬取基本已经完成了,还是之前所说,如果这个项目不是商业性项目,那么做到现在这一步为止已经很好了,因为已经可以爬取98%的数据,无论用于什么性质的数据分析都完全可以了。但是倘若用于商用,数据应该一条不漏才是最优,所以现在还要分析漏爬的页码的问题所在:
1、 原页码给的是PDF链接地址
2、 原页码是纯粹的文本格式
3、 原页码给出的是图片格式
分析出了以上三种漏爬的情况,不得不吐槽一下网页编程人员的闲心,PDF链接地址、图片格式,文本格式,这些并不比单纯地编写表格轻松,但是他们却不知道出于何种原因写了几百个这样奇葩的网页!(做到此处时,表示我的内心已经很疲惫。。)幸而我在编写主程序时,专门编写了用于处理漏爬网页的代码,将它们的网址链接均存储在了一个txt文本中,这样还算让我省去了一些分析时间。于是接下来就是读取txt文本的网页链接,并判别打开的网页为何种类型,并按照对应类型爬取网页并存储为相应的格式:
附上处理以上三种格式的子程序:
1、 PDF格式:
def Get_Pdf_url(self,pdf_url): #处理PDF格式的数据
pdf_url='http://www.cbrc.gov.cn'+pdf_url[0]
request = urllib.request.Request(url=pdf_url,headers=FAKE_HEADER)
doc = urllib.request.urlopen(request)
#doc = response.text
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
file_name = 'PDF_page_'+str(self.page_1)+'.pdf'
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = doc.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name)
2、 文本格式:
def Txt(self,soup_all): #处理文本格式的程序
soup_all=str(soup_all)
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_1 = pre.sub('',soup_all)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_1 = delete.sub('',soup_all)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_1 = pre_1.sub('',soup_all)
#************数据预处理,去除html源码中的特殊字符,
strinfo = re.compile('\xa0')
soup_1 = strinfo.sub(' ',soup_1)
soup_1 = re.findall(PATTERN, soup_1)
txt = ''.join(soup_1)#转化为字符串
self.Write_to_txt(txt)
def Write_to_txt(self,txt):
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
file_name='Doc_page_'+str(self.page_2)+'.txt'
f=open(file_name,'a')
f.write(txt)
print ("Sucessful to download" + " " + file_name)
3、 图片格式:
def Get_Img_url(self,img_url):
img_url='http://www.cbrc.gov.cn'+img_url[0]
#response = requests.get(url=pdf_url,headers=self.headers) #将网址修改指向下一个页面
request = urllib.request.Request(url=img_url,headers=FAKE_HEADER)
doc = urllib.request.urlopen(request)
#doc = response.text
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到桌面文件目录
file_name = 'Image_page_'+str(self.page_1)+'.gif'
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = doc.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name)
由于错误处理的程序不大重要,所以源程序就不附上了,在上面仅附上了各个小部分的错误处理子程序代码。
总结:
终于,这篇教程写完了,有些累。。。稍微总结一下,首先要说明的是,我没有系统学过爬虫,这些代码都是借鉴网上各种大神的博客所写,可能并没有那么优,但不管怎么说,也算是解决了问题,最后的数据验收也没有什么大问题,我也算是松了一口气~
关于爬虫需要提及的是,大家在编写爬虫时,尤其是新手比如我,一定要划分好流程,一块一块地处理问题,千万不要妄想一下子写出全部的程序,就算是写出来了,也需要许多改动,此时如果子程序写得太乱,过于冗余的话,是不可取的,一定要学会将子程序分块编写,这样才能帮助程序的调试,当然一些错误检查机制也不要忽视,可能在最后阶段,这些错误检查机制能让你省去特别多的额外劳动力!
首先简述一下我本次的爬虫项目最终的数据结果:网页中数据一共有一万条左右,要求分成三张针对不同类型数据的表存储,实际上爬取的数据有九千多条,漏爬了近三百条,此三百条数据中有文本格式、PDF格式、图片格式,最后按照对应的数据格式将漏爬的网页数据分别存储为txt格式、PDF格式、GIF格式。下面我将按着我编写爬虫程序时的思路分块去讲解我的整个爬虫项目的构思:
一、 爬取所需的网页网址
首先附上要爬取网址链接的网页的形式:
值得一提的是,大多数大型网站尤其用于存储数据的一些网页都是这种方式呈现,左边每行都对应着一个网页的链接,我们可以分析网页源码中关于这些需要爬取的网页链接是否有特殊的形式能够用正则表达式匹配。在此处分析源码时我使用的是FireFox,顺带安利一波Firefox,它用于分析网页源码十分方便,也节省了我许多用于分析源码的时间。只需按下F12,便可以在查看器中查看网页源代码:
注意此处标蓝的网页源码便是找到的跳转至下一网页的href:其中比较常用的用于匹配网页网址的正则表达式是:href="(.*?.html)",但是在实际爬取中,经常会出现网页中有许多其他额外的网页链接,这时就需要细心分析,一般待爬取的网页链接它都会有额外的属性等用来辅助标识,在本项目中,我很“幸运”地发现我需要爬取的网页链接有一些辅助属性与其他链接不同:target="_blank"
、class="STYLE8,于是我写了用于提取本项目网址的正则匹配式:href="(.*?)"\s*target="_blank".*?class="STYLE8",同时需要提及的是,正则匹配式如果在编写时不确定是否正确,网上有许多在线监测正则匹配的网站用于测试(不然的话正则匹配全部在
4000
程序中验证恐怕要累死了。。。)。本项目中我使用的在线监测正则匹配的网页主要是:https://regex101.com/,当然除了这个在线检测正则匹配的网页,我还辅以使用其他正则检测的网站,主要是该网站的正则检测貌似更新比较慢,有些正确的正则匹配不一定可以被识别,不过online
regex tester这个在线网站算是我尝试的几个在线正则匹配网站中用得最舒服的了~,下面附上检测网址时的匹配情况:
现在,如何从一个网页爬取网页链接的准备工作已经准备好了,我们还需要做的是,程序如何能够做到爬取当前页的数据之后跳转至下一页继续运行爬虫程序:这个地方一般比较容易解决,因为一般网页的跳转都会有个附加的属性,如本项目中的跳转页面网址的页面信息已经被我标识出来,毕竟这种计数页面的方式利于网站管理,当然也利于爬取(暗笑中。。。):
在本项目中,只需要在每页爬取结束后,自动将current+1,就可以进入下一页去爬取网页链接。
最后,需要提及的时,网页一般有防爬机制,但是这种都可以通过构造假的请求头信息骗过网站服务器,详情见下面附上的爬取网页的代码:
#*************************************#
#*** python爬取网页链接 *****#
#*** Author wobeatit *****#
#**** Python版本:3.6.2 **************#
#!/usr/bin/python
#-*- coding: utf-8 -*-
import requests
import re
from bs4import BeautifulSoup as bs
import os #os模块与文本操作直接相关的模块
#*********下面三句代码作用是为了防止出现编码问题*********
import importlib
import sys
importlib.reload(sys)
#****************************************************
BASE_URL ='http://www.cbrc.gov.cn/zhuanti/xzcf/get2and3LevelXZCFDocListDividePage//2.html'
FAKE_HEADER={'User-Agent':'Mozilla/5.0(Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75Safari/537.36 LBBROWSER'} #用于骗过服务器的防爬机制
PATTERN_MAIN ='href="(.*?)"\s*target="_blank".*?class="STYLE8"'#\s是对空白字符的正则匹配
class Crawler:
#初始化
def __init__(self, base_url=BASE_URL,header=FAKE_HEADER, start_page=1):
self.base_url = base_url
self.start_page = start_page
self.headers = header
def fetch_url(self):
while (self.start_page<20): #设置总页面数的大小
response =requests.get(url=self.base_url +'?current={}'.format(self.start_page),headers=self.headers)#将网址修改指向下一个页面
doc = response.text
#print(doc)
url_list = re.findall(PATTERN_MAIN,doc)
print('Now working on page{}'.format(self.start_page)) #打印当前爬取所在页面的页面数
print(len(url_list))
self.start_page += 1
#print(url_list)
print("over!")
def run(self):
self.fetch_url() #运行抓取网址的程序
if __name__ =='__main__':
craw = Crawler()
craw.run() 二、 提取网页表格中的数据
我们已经获取了每个网页的地址链接,接下来需要做的就是如何提取出网页链接对应的网页内容,这也是本项目中最重要的部分,因为在数据抽取时需要编写许多正则匹配式抽取数据,而正则匹配式一般都不一定是最优的,需要耐心地调试程序,直至找到最合适的正则匹配式。
当然本教程目的是分享大家一些方法,以上提及到不断修改正则匹配式是在工程中需要注意的,但是那些都只是额外花费时间,并没有实质上的技术改变,所以我就精要地阐述下在提取本项目中的网页数据时我所用的方法。
首先附上一张所需爬取的网页的截图:
在此项目中我需要提取几个特定的表格单元内的属性值,同时在处罚决定处需要判别为何种处罚类型,如果有罚款,需要注明罚款数额;如此例中,警告就为‘1’,代表处罚属性中有警告,另外罚款就为‘5’,代表罚款为5万元。
当碰到需要爬取的数据为网页表格数据时,我不知道是该庆幸还是悲伤,因为表格数据一般是特定的行与列,就像是我们大家在纸上打格子记录数据时,我们都是习惯特定的表格形式去记录,毕竟这样看着舒服,也方便写入数据,从这个角度来看,爬取表格数据就很轻松,只需要在源码中分析出需要爬取的数据在哪行哪列,专门抽取特定的数据即可。但从另一角度来看,当需要爬取的数据的网站经历了几任网站编程人员维护时,就可能会出现让人崩溃的问题:也许这一任人员喜欢把表格编写成8行8列,另一任人员则喜欢把表格编写成9行10列这种类型,此时就需要编写爬虫程序时不断添加不同格式的处理程序,如此带来的劳动力就比较大了。不过如果爬取的数据不是用于商用这些,即对于爬取的数据的精确度没有特别高的要求时,这些都不是大的问题,但是商用的话,就需要考虑很多问题了,这些我也会在接下来的讲解中穿插着提及到。
当然由于数表格特定的行与列去提取单元格内的数据是比较简单无脑的方法,所以我屈服了,毕竟这样最适合我这种懒得思考的人,所以我傻傻地选择了这种方式提取单元格的数据,主要采用的是Beautiful soup去提取“<tr> <td>”标签,但后来才发现爬取的网页中表格不同行、不同列的组合形式高达六七种,还全是我在不断调试程序时才发现的,期间消耗的人力可想而知。。。
当提取出了特定的表格单元的内容后,如果觉得到现在就结束了,那就太naïve了,因为你需要细心地预处理这些数据,比如去除一些干扰的网页空白字符、去除html中的注释符号、去除网页中出现的特殊字符等这些都需要剔除掉,不然爬出的数据由于编码问题会看着很难受甚至会因为编码问题无法写入文件中。此处先附上我的数据预处理段的代码:
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_list_1 = pre.sub('',soup_list_1)
soup_list_2 = pre.sub('',soup_list_2)
soup_list_3 = pre.sub('',soup_list_3)
soup_list_4 = pre.sub('',soup_list_4)
soup_list_5 = pre.sub('',soup_list_5)
soup_list_6 = pre.sub('',soup_list_6)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_list_1 =delete.sub('',soup_list_1)
soup_list_2 =delete.sub('',soup_list_2)
soup_list_3 =delete.sub('',soup_list_3)
soup_list_4 = delete.sub('',soup_list_4)
soup_list_5 =delete.sub('',soup_list_5)
soup_list_6 =delete.sub('',soup_list_6)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_list_1 = pre_1.sub(',',soup_list_1)
soup_list_2 = pre_1.sub(',',soup_list_2)
soup_list_3 = pre_1.sub(',',soup_list_3)
soup_list_4 = pre_1.sub(',',soup_list_4)
soup_list_5 = pre_1.sub(',',soup_list_5)
soup_list_6 = pre_1.sub(',',soup_list_6)
string_list_1 = re.findall(PATTERN,soup_list_1)
string_list_2 = re.findall(PATTERN,soup_list_2)
string_list_3 = re.findall(PATTERN,soup_list_3)
string_list_4 = re.findall(PATTERN,soup_list_4)
string_list_5 = re.findall(PATTERN,soup_list_5)
string_list_6 = re.findall(PATTERN,soup_list_6)
content_1 = ''.join(string_list_1)#转化为字符串
content_2 = ''.join(string_list_2)
content_3 = ''.join(string_list_3)
content_4 = ''.join(string_list_4)
content_5 = ''.join(string_list_5)
content_6 = ''.join(string_list_6)
strinfo = re.compile('\xa0')#去除特定的字符
content_1 = strinfo.sub(' ',content_1)
content_2 = strinfo.sub(' ',content_2)
content_3 = strinfo.sub(' ',content_3)
content_4 = strinfo.sub(' ',content_4)
content_5 = strinfo.sub(' ',content_5)
content_6 = strinfo.sub(' ',content_6)
最后附上爬取网页表格数据的代码(其中含有许多匹配网页数据的正则匹配式,针对我这个项目,可以选择性地看):
#*************************************#
#*** python 爬取网页表格数据 ****#
#*** Author wobeatit ****#
#*** Python 版本:3.6.2 **************#
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
import re
import time
from bs4 import BeautifulSoup as bs
import os #os模块与文本操作直接相关的模块
#*********下面三句代码作用为了防止出现编码问题*********
import importlib
import sys
importlib.reload(sys)
#****************************************************
BASE_URL = 'http://www.cbrc.gov.cn/chinese/home/docView/560CFEC039224796BFC85F6072F16173.html'
#为爬虫添加一个伪装的头部
FAKE_HEADER={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER'}
PATTERN = '>(.*?)<'#将提取的标签内容中的标签均去除
PATTERN_1 = '(取消)' #统计是否取消高管任职资格
PATTERN_2 = '(罚款|罚没|处罚)'#统计是否属于罚款
PATTERN_3 = '(警告)'#统计行政处罚是否属于警告
PATTERN_4 = '(\d*\.*\d*)万'#统计罚款的数额,是否为万元单位
PATTERN_4_Chinese='[给予|罚款|处].*?([一;二;三;四;五;六;七;八;九;十;壹;贰;叁;伍;拾;百;两;肆;捌].*)万元' #对于中文的数字进行匹配
PATTERN_5 = '(\d*,*\d*\.*\d*)元'#统计罚款的数额,是否为元单位
PATTERN_6 = '(\d*\.*\d*)美元'#统计罚款的数额,是否为美元单位
PATTERN_7 = '(禁止)' #统计是否被禁止从业
PATTERN_8= '(纪律处分)' #统计是否违纪
PATTERN_9= '(吊销)' #统计是否被吊销营业证
class Crawler:
#初始化
def __init__(self, base_url=BASE_URL, header=FAKE_HEADER):
self.base_url = base_url
self.headers = header
def grab_page_content(self):
response = requests.get(url=self.base_url,headers=self.headers) #将网址修改指向下一个页面
doc = response.text
soup = bs(doc,"html.parser")
#print(soup)
if(soup.find('table',{'class':'MsoNormalTable'})):
soup_all=soup.find('table',{'class':'MsoNormalTable'})
elif(soup.find('table',{'class':'MsoTableGrid'})):
soup_all=soup.find('table',{'class':'MsoTableGrid'})
elif(soup.find('div',{'Section0'})):
soup_all=soup.find('div',{'Section0'})
else:
soup_all=''
soup_list=soup_all.find_all('tr')
length_tr=len(soup_list)
print(length_tr)
url_1=self.base_url
self.solve_diff_lentgh(soup_list,url_1,length_tr)
def Chinese_conv_to_math(self,money_1):#利用正则表达式将中文字符转化为数字
one = re.compile('一')
one_1=re.compile('壹')
two = re.compile('二')
two_1=re.compile('贰')
two_2=re.compile('两')
three = re.compile('三')
three_1=re.compile('叁')
four = re.compile('四')
four_1 = re.compile('肆')
five = re.compile('五')
five_1 = re.compile('伍')
six = re.compile('六')
seven = re.compile('七')
eight = re.compile('八')
eight_1 = re.compile('捌')
nine = re.compile('九')
ten = re.compile('十')
ten_1=re.compile('拾')
hundred=re.compile('百')
money = one.sub('1',money_1)
money = one_1.sub('1',money)
money = two.sub('2',money)
money = two_1.sub('2',money)
money = two_2.sub('2',money)
money = three.sub('3',money)
money = three_1.sub('3',money)
money = four.sub('4',money)
money = four_1.sub('4',money)
money = five.sub('5',money)
money = five_1.sub('5',money)
money = six.sub('6',money)
money = seven.sub('7',money)
money = eight.sub('8',money)
money = eight_1.sub('8',money)
money = nine.sub('9',money)
money = ten.sub('0',money)
money = ten_1.sub('0',money)
money=hundred.sub('000',money)
money=str(money)
#print(money)
if(len(money)==7):
money=money=int(money[0:3])+int(money[4:6])+int(money[len(money)-1])
money=str(money)
elif(len(money)==6):
money=int(money[0:3])+int(money[4:6])
money=str(money)
elif(len(money)==4):
money=int(money[0:3])
money=str(money)
elif(len(money)==3):
money=int(money[0:2])+int(money[len(money)-1])
money=str(money)
elif((len(money)==2)&(money[0]=='0')):
money=10+int(money[1])
money=str(money)
elif(money[0]=='0'):
money='10'
return money
def solve_diff_lentgh(self,soup_list,url_1,length_tr):
if length_tr==8:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[1].find_all('td')[1])
soup_list_3=str(soup_list[3].find_all('td')[1])
soup_list_4=str(soup_list[4].find_all('td')[1])
soup_list_5=str(soup_list[5].find_all('td')[1])
soup_list_6=str(soup_list[7].find_all('td')[1])
elif length_tr==9:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[2].find_all('td')[2])
soup_list_3=str(soup_list[4].find_all('td')[1])
soup_list_4=str(soup_list[5].find_all('td')[1])
soup_list_5=str(soup_list[6].find_all('td')[1])
soup_list_6=str(soup_list[8].find_all('td')[1])
elif length_tr==10:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[3].find_all('td')[1])
soup_list_3=str(soup_list[5].find_all('td')[1])
soup_list_4=str(soup_list[6].find_all('td')[1])
soup_list_5=str(soup_list[7].find_all('td')[1])
soup_list_6=str(soup_list[9].find_all('td')[1])
elif length_tr==11:
soup_list_1=str(soup_list[1].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[3].find_all('td')[2])
soup_list_3=str(soup_list[5].find_all('td')[1])
soup_list_4=str(soup_list[6].find_all('td')[1])
soup_list_5=str(soup_list[7].find_all('td')[1])
soup_list_6=str(soup_list[9].find_all('td')[1])
elif length_tr==12:
soup_list_1=str(soup_list[3].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[5].find_all('td')[2])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str
10f34
(soup_list[11].find_all('td')[1])
elif length_tr==13:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[4].find_all('td')[1])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str(soup_list[11].find_all('td')[1])
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_list_1 = pre.sub('',soup_list_1)
soup_list_2 = pre.sub('',soup_list_2)
soup_list_3 = pre.sub('',soup_list_3)
soup_list_4 = pre.sub('',soup_list_4)
soup_list_5 = pre.sub('',soup_list_5)
soup_list_6 = pre.sub('',soup_list_6)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_list_1 = delete.sub('',soup_list_1)
soup_list_2 = delete.sub('',soup_list_2)
soup_list_3 = delete.sub('',soup_list_3)
soup_list_4 = delete.sub('',soup_list_4)
soup_list_5 = delete.sub('',soup_list_5)
soup_list_6 = delete.sub('',soup_list_6)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_list_1 = pre_1.sub(',',soup_list_1)
soup_list_2 = pre_1.sub(',',soup_list_2)
soup_list_3 = pre_1.sub(',',soup_list_3)
soup_list_4 = pre_1.sub(',',soup_list_4)
soup_list_5 = pre_1.sub(',',soup_list_5)
soup_list_6 = pre_1.sub(',',soup_list_6)
string_list_1 = re.findall(PATTERN, soup_list_1)
string_list_2 = re.findall(PATTERN, soup_list_2)
string_list_3 = re.findall(PATTERN, soup_list_3)
string_list_4 = re.findall(PATTERN, soup_list_4)
string_list_5 = re.findall(PATTERN, soup_list_5)
string_list_6 = re.findall(PATTERN, soup_list_6)
#print(doc)
content_1 = ''.join(string_list_1)#转化为字符串
content_2 = ''.join(string_list_2)
content_3 = ''.join(string_list_3)
content_4 = ''.join(string_list_4)
content_5 = ''.join(string_list_5)
content_6 = ''.join(string_list_6)
strinfo = re.compile('\xa0')
content_1 = strinfo.sub(' ',content_1)
content_2 = strinfo.sub(' ',content_2)
content_3 = strinfo.sub(' ',content_3)
content_4 = strinfo.sub(' ',content_4)
content_5 = strinfo.sub(' ',content_5)
content_6 = strinfo.sub(' ',content_6)
print(content_5)
line=[]
content_1=content_1+','
line.append(content_1)
content_2=content_2+','
line.append(content_2)
content_3=content_3+','
line.append(content_3)
content_4=content_4+','
line.append(content_4)
content_6=content_6+','
content_5_raw=content_5+','
line.append(content_5_raw)
if re.findall(PATTERN_2,content_5):
if re.findall(PATTERN_4_Chinese,content_5):
money_list=re.findall(PATTERN_4_Chinese,content_5)
#print(money_list)
money_1=money_list[len(money_list)-1]
money=self.Chinese_conv_to_math(money_1)
#yuan=float(money)
#yuan=yuan/10
content_5_1=money+','
line.append(content_5_1)
elif re.findall(PATTERN_4,content_5):
money_list=re.findall(PATTERN_4,content_5)
int_list=[]
for i in money_list:
int_list.append(float(i))
content_5_1=str(max(int_list))+','
line.append(content_5_1)
#print('罚款:万元')
elif re.findall(PATTERN_6,content_5):
money_list=re.findall(PATTERN_6,content_5)
dollar=float(money_list[len(money_list)-1])
dollar=dollar*6.6/10000
content_5_1=str(dollar)+','
line.append(content_5_1)
#print('罚款:美元')
elif re.findall(PATTERN_5,content_5):
money_list=re.findall(PATTERN_5,content_5)
delete = re.compile(',')
money = delete.sub('',str(money_list[len(money_list)-1]))
yuan=float(money)
yuan=yuan/10000
content_5_1=str(yuan)+','
line.append(content_5_1)
#print('罚款:元')
else:
content_5_1=' ,'
line.append(content_5_1)
else:
content_5_1=' ,'
line.append(content_5_1)
if re.findall(PATTERN_3,content_5):
content_5_2='1,'
line.append(content_5_2)
else:
content_5_2=' ,'
line.append(content_5_2)
if re.findall(PATTERN_8,content_5):
content_5_2_1='1,'
line.append(content_5_2_1)
else:
content_5_2_1 = ' ,'
line.append(content_5_2_1)
if re.findall(PATTERN_1,content_5):
content_5_3='1,'
line.append(content_5_3)
else:
content_5_3=' ,'
line.append(content_5_3)
if re.findall(PATTERN_7,content_5):
content_5_4=' ,1,'
line.append(content_5_4)
else:
content_5_4=' , ,'
line.append(content_5_4)
if re.findall(PATTERN_9,content_5):
content_5_5='1,'
line.append(content_5_5)
else:
content_5_5=' ,'
line.append(content_5_5)
content_5_after=' ,'
line.append(content_5_after)
line.append(content_6)
content_7=url_1+','
line.append(content_7)
print(line)
self.write_to_ducument(line) #将爬取的数据都写入txt文件中,以逗号隔开,最后可以转成csv格式
def write_to_ducument(self,line):
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
path='1.txt'
f=open(path,'a')
line_1=''.join(line)
f.write('\n'+line_1)
def run(self):
self.grab_page_content() #运行抓取网址的程序
if __name__ == '__main__':
craw = Crawler()
craw.run()
三、 完整爬虫的程序
至此爬虫的基本流程已经叙述完毕了,现在来看,em,还蛮简单的,当然简单归简单,最重要的是亲手实践,因为有些坑只有自己亲自踩过才会知道问题所在。
现在大致梳理一下整个流程:首先爬取网页的地址,然后通过获取的网页链接爬取其中的网页数据,按照要求的格式利用正则匹配式去处理网页数据,最后将这两大块合在一起编写总程序,当然需要注意的是,在主程序中应有异常处理,用于存储漏爬的页码、网页链接,用于接下来的漏爬数据处理程序的编写,首先附上主程序代码:
#*************************************#
#*** python 爬取网页数据主程序 ****#
#*** Author wobeatit ****#
#*** Python 版本:3.6.2 **************#
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
import re
from bs4 import BeautifulSoup as bs
import os #os模块与文本操作直接相关的模块
#*********下面三句代码作用不详,就是为了防止出现编码问题*********
import importlib
import sys
importlib.reload(sys)
#****************************************************
BASE_URL = 'http://www.cbrc.gov.cn/zhuanti/xzcf/get2and3LevelXZCFDocListDividePage//2.html'
FAKE_HEADER={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER'}
PATTERN_MAIN = 'href="(.*?)"\s*target="_blank".*?class="STYLE8"' #\s是对空白字符的正则匹配
PATTERN = '>(.*?)<'#将提取的标签内容中的标签均去除
PATTERN_1 = '(取消)' #统计是否取消高管任职资格
PATTERN_2 = '(罚款|罚没|处罚)'#统计是否属于罚款
PATTERN_3 = '(警告)'#统计行政处罚是否属于警告
PATTERN_4 = '(\d*\.*\d*)万'#统计罚款的数额,是否为万元单位
PATTERN_4_Chinese='[给予|罚款|处].*?([一;二;三;四;五;六;七;八;九;十;壹;贰;两;叁;肆;伍;柒;捌;拾;百].*)万元' #对于中文的数字进行匹配
PATTERN_5 = '(\d*,*\d*\.*\d*)元'#统计罚款的数额,是否为元单位
PATTERN_6 = '(\d*\.*\d*)美元'#统计罚款的数额,是否为美元单位
PATTERN_7 = '(禁止)' #统计是否被禁止从业
PATTERN_8= '(纪律处分)' #统计是否违纪
PATTERN_9= '(吊销)' #统计是否被吊销营业证
class Crawler:
#初始化
def __init__(self, base_url=BASE_URL, header=FAKE_HEADER, start_page=136):
self.base_url = base_url
self.start_page = start_page
self.headers = header
def fetch_url(self):
while (self.start_page<222): #设置总页面数的大小
response = requests.get(url=self.base_url + '?current={}'.format(self.start_page),headers=self.headers) #将网址修改指向下一个页面
doc = response.text
url_list = re.findall(PATTERN_MAIN, doc)
print('Now working on page {}'.format(self.start_page)) #打印当前爬取所在页面的页面数
print(len(url_list))
self.grab_page_content(url_list)
self.start_page += 1
print("over!")
def grab_page_content(self,url_list):
i=0
for item in url_list:
i=i+1
url_1='http://www.cbrc.gov.cn'+item
try:
response=requests.get(url=url_1,headers=self.headers) #读出列表中存储的网址
doc = response.text
soup = bs(doc,"html.parser")
#print(soup)
if(soup.find('table',{'class':'MsoNormalTable'})):
soup_all=soup.find('table',{'class':'MsoNormalTable'})
elif(soup.find('table',{'class':'MsoTableGrid'})):
soup_all=soup.find('table',{'class':'MsoTableGrid'})
elif(soup.find('div',{'Section0'})):
soup_all=soup.find('div',{'Section0'})
else:
soup_all=''
soup_list=soup_all.find_all('tr')
length_tr=len(soup_list)
#print(length_tr)
self.solve_diff_lentgh(soup_list,url_1,length_tr)
except:
error_1='第'+str(self.start_page)+'页 '+'第'+str(i)+'条 '+url_1
self.write_to_ducument_error(error_1)
continue
def Chinese_conv_to_math(self,money_1):#利用正则表达式将中文字符转化为数字
one = re.compile('一')
one_1=re.compile('壹')
two = re.compile('二')
two_1=re.compile('贰')
two_2=re.compile('两')
three = re.compile('三')
three_1=re.compile('叁')
four = re.compile('四')
four_1 = re.compile('肆')
five = re.compile('五')
five_1 = re.compile('伍')
six = re.compile('六')
seven = re.compile('七')
seven_1 = re.compile('柒')
eight = re.compile('八')
eight_1 = re.compile('捌')
nine = re.compile('九')
ten = re.compile('十')
ten_1=re.compile('拾')
hundred=re.compile('百')
money = one.sub('1',money_1)
money = one_1.sub('1',money)
money = two.sub('2',money)
money = two_1.sub('2',money)
money = two_2.sub('2',money)
money = three.sub('3',money)
money = three_1.sub('3',money)
money = four.sub('4',money)
money = four_1.sub('4',money)
money = five.sub('5',money)
money = five_1.sub('5',money)
money = six.sub('6',money)
money = seven.sub('7',money)
money = seven_1.sub('7',money)
money = eight.sub('8',money)
money = eight_1.sub('8',money)
money = nine.sub('9',money)
money = ten.sub('0',money)
money = ten_1.sub('0',money)
money=hundred.sub('000',money)
money=str(money)
#print(money)
if(len(money)==7):
money=money=int(money[0:3])+int(money[4:6])+int(money[len(money)-1])
money=str(money)
elif(len(money)==6):
money=int(money[0:3])+int(money[4:6])
money=str(money)
elif(len(money)==4):
money=int(money[0:3])
money=str(money)
elif(len(money)==3):
money=int(money[0:2])+int(money[len(money)-1])
money=str(money)
elif((len(money)==2)&(money[0]=='0')):
money=10+int(money[1])
money=str(money)
elif(money[0]=='0'):
money='10'
return money
def solve_diff_lentgh(self,soup_list,url_1,length_tr):
if length_tr==8:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[1].find_all('td')[2])
soup_list_3=str(soup_list[3].find_all('td')[1])
soup_list_4=str(soup_list[4].find_all('td')[1])
soup_list_5=str(soup_list[5].find_all('td')[1])
soup_list_6=str(soup_list[7].find_all('td')[1])
elif length_tr==9:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[2].find_all('td')[2])
soup_list_3=str(soup_list[4].find_all('td')[1])
soup_list_4=str(soup_list[5].find_all('td')[1])
soup_list_5=str(soup_list[6].find_all('td')[1])
soup_list_6=str(soup_list[8].find_all('td')[1])
elif length_tr==10:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[3].find_all('td')[1])
soup_list_3=str(soup_list[5].find_all('td')[1])
soup_list_4=str(soup_list[6].find_all('td')[1])
soup_list_5=str(soup_list[7].find_all('td')[1])
soup_list_6=str(soup_list[9].find_all('td')[1])
elif length_tr==11:
soup_list_1=str(soup_list[2].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[4].find_all('td')[2])
soup_list_3=str(soup_list[6].find_all('td')[1])
soup_list_4=str(soup_list[7].find_all('td')[1])
soup_list_5=str(soup_list[8].find_all('td')[1])
soup_list_6=str(soup_list[10].find_all('td')[1])
elif length_tr==12:
soup_list_1=str(soup_list[3].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[5].find_all('td')[2])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str(soup_list[11].find_all('td')[1])
elif length_tr==13:
soup_list_1=str(soup_list[0].find_all('td')[1]) #提取出表格对应块的内容
soup_list_2=str(soup_list[4].find_all('td')[1])
soup_list_3=str(soup_list[7].find_all('td')[1])
soup_list_4=str(soup_list[8].find_all('td')[1])
soup_list_5=str(soup_list[9].find_all('td')[1])
soup_list_6=str(soup_list[11].find_all('td')[1])
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_list_1 = pre.sub('',soup_list_1)
soup_list_2 = pre.sub('',soup_list_2)
soup_list_3 = pre.sub('',soup_list_3)
soup_list_4 = pre.sub('',soup_list_4)
soup_list_5 = pre.sub('',soup_list_5)
soup_list_6 = pre.sub('',soup_list_6)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_list_1 = delete.sub('',soup_list_1)
soup_list_2 = delete.sub('',soup_list_2)
soup_list_3 = delete.sub('',soup_list_3)
soup_list_4 = delete.sub('',soup_list_4)
soup_list_5 = delete.sub('',soup_list_5)
soup_list_6 = delete.sub('',soup_list_6)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_list_1 = pre_1.sub(',',soup_list_1)
soup_list_2 = pre_1.sub(',',soup_list_2)
soup_list_3 = pre_1.sub(',',soup_list_3)
soup_list_4 = pre_1.sub(',',soup_list_4)
soup_list_5 = pre_1.sub(',',soup_list_5)
soup_list_6 = pre_1.sub(',',soup_list_6)
string_list_1 = re.findall(PATTERN, soup_list_1)
string_list_2 = re.findall(PATTERN, soup_list_2)
string_list_3 = re.findall(PATTERN, soup_list_3)
string_list_4 = re.findall(PATTERN, soup_list_4)
string_list_5 = re.findall(PATTERN, soup_list_5)
string_list_6 = re.findall(PATTERN, soup_list_6)
#print(doc)
content_1 = ''.join(string_list_1)#转化为字符串
content_2 = ''.join(string_list_2)
content_3 = ''.join(string_list_3)
content_4 = ''.join(string_list_4)
content_5 = ''.join(string_list_5)
content_6 = ''.join(string_list_6)
strinfo = re.compile('\xa0')
content_1 = strinfo.sub(' ',content_1)
content_2 = strinfo.sub(' ',content_2)
content_3 = strinfo.sub(' ',content_3)
content_4 = strinfo.sub(' ',content_4)
content_5 = strinfo.sub(' ',content_5)
content_6 = strinfo.sub(' ',content_6)
#print(content_1)
#print(content_2)
#print(content_3)
print(content_5)
line=[]
content_1=content_1+','
line.append(content_1)
content_2=content_2+','
line.append(content_2)
content_3=content_3+','
line.append(content_3)
content_4=content_4+','
line.append(content_4)
content_6=content_6+','
content_5_raw=content_5+','
line.append(content_5_raw)
if re.findall(PATTERN_2,content_5):
if re.findall(PATTERN_4_Chinese,content_5):
money_list=re.findall(PATTERN_4_Chinese,content_5)
#print(money_list)
money_1=money_list[len(money_list)-1]
money=self.Chinese_conv_to_math(money_1)
content_5_1=money+','
line.append(content_5_1)
elif re.findall(PATTERN_4,content_5):
money_list=re.findall(PATTERN_4,content_5)
int_list=[]
for i in money_list:
int_list.append(float(i))
content_5_1=str(max(int_list))+','
line.append(content_5_1)
#print('罚款:万元')
elif re.findall(PATTERN_6,content_5):
money_list=re.findall(PATTERN_6,content_5)
dollar=float(money_list[len(money_list)-1])
dollar=dollar*6.6/10000
content_5_1=str(dollar)+','
line.append(content_5_1)
#print('罚款:美元')
elif re.findall(PATTERN_5,content_5):
money_list=re.findall(PATTERN_5,content_5)
delete = re.compile(',')
money = delete.sub('',str(money_list[len(money_list)-1]))
yuan=float(money)
yuan=yuan/10000
content_5_1=str(yuan)+','
line.append(content_5_1)
#print('罚款:元')
else:
content_5_1=' ,'
line.append(content_5_1)
else:
content_5_1=' ,'
line.append(content_5_1)
if re.findall(PATTERN_3,content_5):
content_5_2='1,'
line.append(content_5_2)
else:
content_5_2=' ,'
line.append(content_5_2)
if re.findall(PATTERN_8,content_5):
content_5_2_1='1,'
line.append(content_5_2_1)
else:
content_5_2_1 = ' ,'
line.append(content_5_2_1)
if re.findall(PATTERN_1,content_5):
content_5_3='1,'
line.append(content_5_3)
else:
content_5_3=' ,'
line.append(content_5_3)
if re.findall(PATTERN_7,content_5):
content_5_4=' ,1,'
line.append(content_5_4)
else:
content_5_4=' , ,'
line.append(content_5_4)
if re.findall(PATTERN_9,content_5):
content_5_5='1,'
line.append(content_5_5)
else:
content_5_5=' ,'
line.append(content_5_5)
content_5_after=' ,'
line.append(content_5_after)
line.append(content_6)
content_7=url_1+','
line.append(content_7)
self.write_to_ducument(line)
def write_to_ducument(self,line):
#print('正在写入文件...')
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
path='grab_3.txt'
f=open(path,'a')
line_1=''.join(line)
f.write('\n'+line_1)
def write_to_ducument_error(self,error):
#print('正在写入文件...')
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
path='error_3.txt'
f=open(path,'a')
f.write('\n'+error)
def run(self):
self.fetch_url() #运行抓取网址的程序
if __name__ == '__main__':
craw = Crawler()
craw.run()
四、 漏爬数据的处理
至此,网页数据爬取基本已经完成了,还是之前所说,如果这个项目不是商业性项目,那么做到现在这一步为止已经很好了,因为已经可以爬取98%的数据,无论用于什么性质的数据分析都完全可以了。但是倘若用于商用,数据应该一条不漏才是最优,所以现在还要分析漏爬的页码的问题所在:
1、 原页码给的是PDF链接地址
2、 原页码是纯粹的文本格式
3、 原页码给出的是图片格式
分析出了以上三种漏爬的情况,不得不吐槽一下网页编程人员的闲心,PDF链接地址、图片格式,文本格式,这些并不比单纯地编写表格轻松,但是他们却不知道出于何种原因写了几百个这样奇葩的网页!(做到此处时,表示我的内心已经很疲惫。。)幸而我在编写主程序时,专门编写了用于处理漏爬网页的代码,将它们的网址链接均存储在了一个txt文本中,这样还算让我省去了一些分析时间。于是接下来就是读取txt文本的网页链接,并判别打开的网页为何种类型,并按照对应类型爬取网页并存储为相应的格式:
附上处理以上三种格式的子程序:
1、 PDF格式:
def Get_Pdf_url(self,pdf_url): #处理PDF格式的数据
pdf_url='http://www.cbrc.gov.cn'+pdf_url[0]
request = urllib.request.Request(url=pdf_url,headers=FAKE_HEADER)
doc = urllib.request.urlopen(request)
#doc = response.text
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
file_name = 'PDF_page_'+str(self.page_1)+'.pdf'
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = doc.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name)
2、 文本格式:
def Txt(self,soup_all): #处理文本格式的程序
soup_all=str(soup_all)
#**************数据预处理,去除一些干扰的空白符号
pre = re.compile('\s*')
soup_1 = pre.sub('',soup_all)
#************数据预处理,去除html源码中的注释符号
delete = re.compile('<!--.*?-->')
soup_1 = delete.sub('',soup_all)
#************数据预处理,去除html源码中的英文字符,
pre_1 = re.compile(',')
soup_1 = pre_1.sub('',soup_all)
#************数据预处理,去除html源码中的特殊字符,
strinfo = re.compile('\xa0')
soup_1 = strinfo.sub(' ',soup_1)
soup_1 = re.findall(PATTERN, soup_1)
txt = ''.join(soup_1)#转化为字符串
self.Write_to_txt(txt)
def Write_to_txt(self,txt):
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到指定文件目录
file_name='Doc_page_'+str(self.page_2)+'.txt'
f=open(file_name,'a')
f.write(txt)
print ("Sucessful to download" + " " + file_name)
3、 图片格式:
def Get_Img_url(self,img_url):
img_url='http://www.cbrc.gov.cn'+img_url[0]
#response = requests.get(url=pdf_url,headers=self.headers) #将网址修改指向下一个页面
request = urllib.request.Request(url=img_url,headers=FAKE_HEADER)
doc = urllib.request.urlopen(request)
#doc = response.text
os.chdir('D:\\Python_Code\\Python_网络爬虫基础学习\\爬取网页数据') #改变工作目录到桌面文件目录
file_name = 'Image_page_'+str(self.page_1)+'.gif'
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = doc.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name)
由于错误处理的程序不大重要,所以源程序就不附上了,在上面仅附上了各个小部分的错误处理子程序代码。
总结:
终于,这篇教程写完了,有些累。。。稍微总结一下,首先要说明的是,我没有系统学过爬虫,这些代码都是借鉴网上各种大神的博客所写,可能并没有那么优,但不管怎么说,也算是解决了问题,最后的数据验收也没有什么大问题,我也算是松了一口气~
关于爬虫需要提及的是,大家在编写爬虫时,尤其是新手比如我,一定要划分好流程,一块一块地处理问题,千万不要妄想一下子写出全部的程序,就算是写出来了,也需要许多改动,此时如果子程序写得太乱,过于冗余的话,是不可取的,一定要学会将子程序分块编写,这样才能帮助程序的调试,当然一些错误检查机制也不要忽视,可能在最后阶段,这些错误检查机制能让你省去特别多的额外劳动力!

相关文章推荐
- 浅谈ODS与DW的区别-数据项目实战总结
- iOS项目开发实战——获取网页源代码的二进制数据
- 项目实战:APP登入后,数据的持久化储存
- 最近实战项目总结
- javaee学习之路(二十一)JavaWeb项目实战--银行存款业务
- [MarsZ]ThinkPHP项目实战总结
- [MarsZ]ThinkPHP项目实战总结
- vue项目实战总结笔记
- 数据恢复实战技术总结
- Android实战-个人App乐逗项目(第一阶段:微信精选文章完成与总结)
- 【springmvc+mybatis项目实战】杰信商贸-28.POI百万数据打印
- Python实战(二)—— urllib2 下载网页的方式总结
- 网页项目总结
- 【ssm个人博客项目实战05】easy ui datagrid实现数据的分页显示
- 四轴项目总结之二-姿态,数据篇
- U6数据导出工具项目总结三 鼠标单击或者双击DataGridView控件时获取鼠标点击位置的值
- 项目开发实战 jQuery+php+mysql实现数据上传功能(补充!!!)
- Android项目实战经验总结
- DeepLearning(基于caffe)实战项目(7)--从caffe结构里函数总结一览caffe
- iOS项目开发实战——iOS网络编程获取网页Html源码