【ML学习笔记】12:k-近邻算法的demo
2017-12-22 21:14
363 查看
k-近邻算法(KNN)是一种有监督学习的分类算法,属于非概率分类器。
其基本思路就是,实例的每一个特征都可以赋予一个值去度量,如果有n个特征,那么也就是相当于实例在n维空间中(n个方向各自不同,显然这种假定是建立在我们认为这些特征互不相关的基础上的)。
而k-近邻算法也就是,把这个投入到学习机器去做预测的实例的特征向量,认定是表达了n维空间上的一个点,这个空间不见得是欧式空间,然后去寻找训练集中k个和这个点距离最近(这个距离自然是定义在这个空间上的距离)的点对应的实例,去看这些实例对应的标签,出现频数最多的那个标签就成为我们kNN算法预测的标签。
下面这个demo是跟着书上做的,加了一些可视化的成分,有很多细节值得注意,算是回顾了python的小部分语法。
这是一个后缀名为.py的模块,写好以后,在命令行进入到这个模块文件所在的目录,然后再进入python回显界面去使用它!
导入模块,然后使用它:
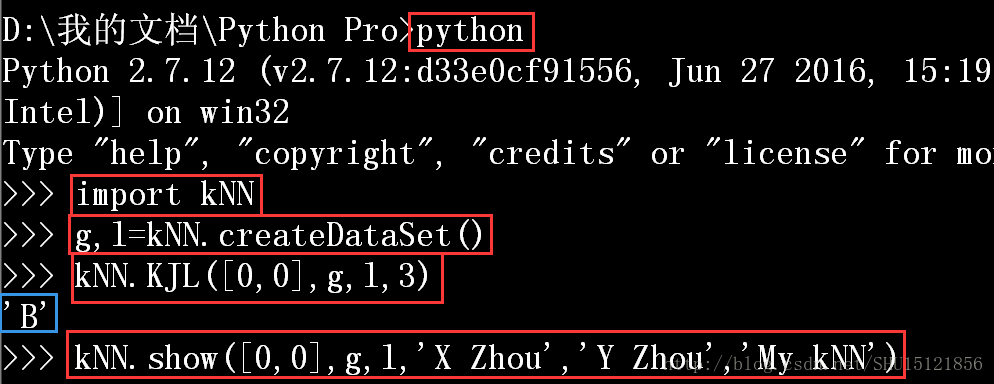
运行结果:
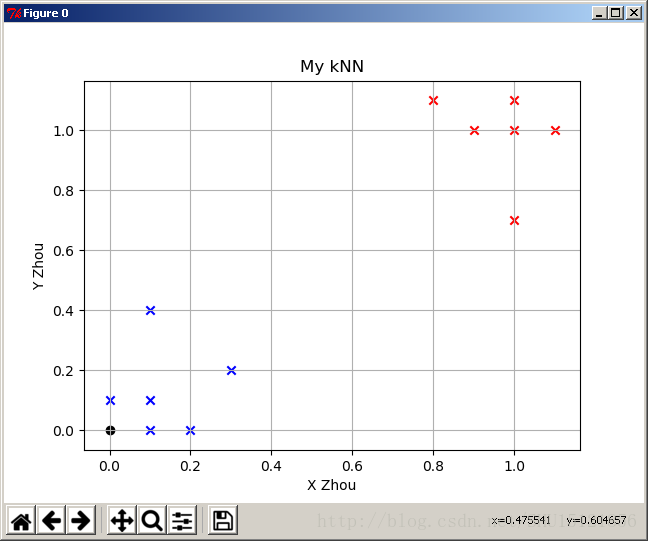
在这里我使用的是L2范数距离(欧式距离)的平方,开根号不影响比较大小。
此外,为了显示点的标签,可以用:
但是这个程序里是每个点画一次,不是传入相同标签的点的集和,所以直接这样用结果是这样:
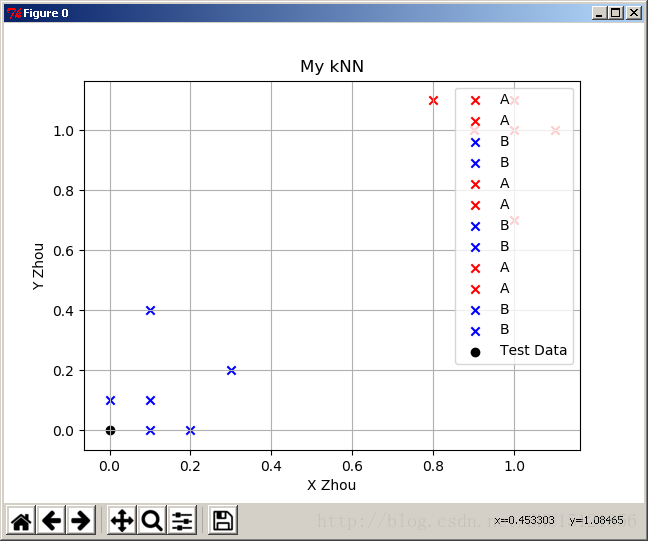
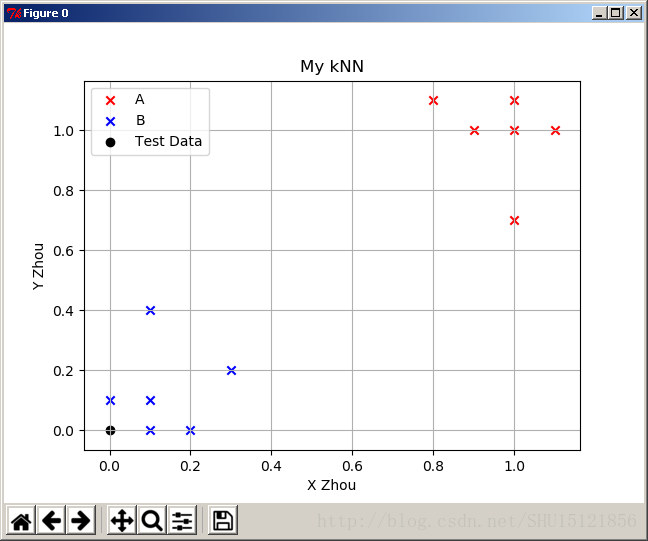
所以可以去改一下for循环,只对新发现的类的那个点传入label参数:
为了不遮挡,放在左上角:
其基本思路就是,实例的每一个特征都可以赋予一个值去度量,如果有n个特征,那么也就是相当于实例在n维空间中(n个方向各自不同,显然这种假定是建立在我们认为这些特征互不相关的基础上的)。
而k-近邻算法也就是,把这个投入到学习机器去做预测的实例的特征向量,认定是表达了n维空间上的一个点,这个空间不见得是欧式空间,然后去寻找训练集中k个和这个点距离最近(这个距离自然是定义在这个空间上的距离)的点对应的实例,去看这些实例对应的标签,出现频数最多的那个标签就成为我们kNN算法预测的标签。
下面这个demo是跟着书上做的,加了一些可视化的成分,有很多细节值得注意,算是回顾了python的小部分语法。
这是一个后缀名为.py的模块,写好以后,在命令行进入到这个模块文件所在的目录,然后再进入python回显界面去使用它!
#-*-coding:utf-8-*-
from numpy import * #科学计算包
import operator #运算符模块
from matplotlib import pyplot as plt
#上一行的末尾不能打注释!
#创建训练集和标签
def createDataSet():
#训练集的特征
group=array(
[[1.0,1.1],[1.0,1.0],[0.1,0],[0,0.1],
[0.9,1.0],[1.0,0.7],[0.2,0],[0.1,0.1],
[1.1,1.0],[0.8,1.1],[0.1,0.4],[0.3,0.2]])
#对应的标签
labels=['A','A','B','B',
'A','A','B','B',
'A','A','B','B']
return group,labels
#k-近邻算法(输入的特征向量,训练集特征向量矩阵,训练集标签向量,k值)
def KJL(inX,dataSet,labels,k):
#用shape[0]读取训练集第一维的长度(行数即训练集实例数)
dataSetRow=dataSet.shape[0]
#用shape[1]读取训练集第二维的长度(列数即特征数)
dataSetCol=dataSet.shape[1]
#读取输入向量的列数(特征数)
inXCol=len(inX)
#训练集标签向量的个数
labelsLen=len(labels)
#对训练集的判定
if labelsLen!=dataSetRow:
print "训练集的特征集和标签集实例数目不等"
return
#对输入的判定
if inXCol!=dataSetCol:
print "用于测试的的实例的特征数目和训练集特征数目不等"
return
#用tile()将输入的特征向量重复成和训练集特征向量一样多的行
#变成2维,里面的维度重复1次,外面一层重复dataSetRow次
diffMat=tile(inX,(dataSetRow,1))
#减去训练集特征向量矩阵得到存偏差的矩阵
diffMat=diffMat-dataSet
#将减出来的偏差矩阵每个元素平方
sqDiffMat=diffMat**2
#对行求和,表示这个实例和这行对应的训练集实例的L2范数的平方
sqDistances=sqDiffMat.sum(axis=1)
#为了方便就不开根号(**0.5)了
#argsort()返回其从小到大排序的排序索引序列
sortIndex=sqDistances.argsort()
#空字典,用来存各个标签在前k邻居中出现的次数
classCount={}
#找前k个距离最近的,也就是排序下标从0~k-1的
for i in range(k):
#暂存第i近(从0计数)训练集实例的标签
voteIlab=labels[sortIndex[i]]
#先取字典中以这个标签为key的value值,如果没有则返回0
#加上1作为以这个标签为key的value值
classCount[voteIlab]=classCount.get(voteIlab,0)+1
#把classCount用iteritems()方法变成可迭代对象传入
#用operator.itemgetter()方法定义一个函数给参数key,这个函数按1号域排序
#将reverse参数显示修正为True,表示降序排序(找频数最大的)
sortedClassCount=sorted(
classCount.iteritems(),
key=operator.itemgetter(1),
reverse=True)
#排序好后,第0个对象就是要找的那个频率最高的实例的[标签,频率]了
#只返回标签
return sortedClassCount[0][0]
#显示训练集和输入的实例(二维特征)
#(输入的特征向量,训练集特征向量矩阵,训练集标签向量,x轴名称,y轴名称,标题)
def show(inX,dataSet,labels,xlab,ylab,tit):
#用shape[0]读取训练集第一维的长度(行数即训练集实例数)
dataSetRow=dataSet.shape[0]
#用shape[1]读取训练集第二维的长度(列数即特征数)
dataSetCol=dataSet.shape[1]
#读取输入向量的列数(特征数)
inXCol=len(inX)
#训练集标签向量的个数
labelsLen=len(labels)
#对训练集的判定
if labelsLen!=dataSetRow:
print "训练集的特征集和标签集实例数目不等"
return
#对维度的判定
if dataSetCol!=2:
print "特征不是两维的,暂时不能用这个方法"
return
#对输入实例的判定
if inXCol!=dataSetCol:
print "用于测试的的实例的特征数目和训练集特征数目不等"
return
#绘制窗口
plt.figure(0)
#横纵坐标名称,标题名称
plt.xlabel(xlab)
plt.ylabel(ylab)
plt.title(tit)
#需要网格
plt.grid(True)
#用来管理颜色表
idx=0
clr=['r','b','y','g','c','m']
bqzd={}
#循环画每一个点(实际上也可以传入list画一群点)
for i in range(labelsLen):
#如果这个标签没放入字典
if bqzd.get(labels[i],0)==0:
bqzd[labels[i]]=clr[idx] #放入字典
idx=(idx+1)%6 #取新的颜色表下标
#绘制这个点
plt.scatter(
dataSet[i][0],
dataSet[i][1],
color=bqzd[labels[i]],
marker='x',
label=labels[i])
#绘制给定的实例点
plt.scatter(
inX[0],
inX[1],
color='k',
marker='o',
label='Test Data')
plt.show()
return导入模块,然后使用它:
运行结果:
在这里我使用的是L2范数距离(欧式距离)的平方,开根号不影响比较大小。
此外,为了显示点的标签,可以用:
#右上角打标注 plt.legend(loc = 'upper right')
但是这个程序里是每个点画一次,不是传入相同标签的点的集和,所以直接这样用结果是这样:
所以可以去改一下for循环,只对新发现的类的那个点传入label参数:
#循环画每一个点(实际上也可以传入list画一群点) for i in range(labelsLen): #如果这个标签没放入字典 if bqzd.get(labels[i],0)==0: bqzd[labels[i]]=clr[idx] #放入字典 idx=(idx+1)%6 #取新的颜色表下标 #绘制这个点 plt.scatter( dataSet[i][0], dataSet[i][1], color=bqzd[labels[i]], marker='x', label=labels[i]) else: #绘制这个点 plt.scatter( dataSet[i][0], dataSet[i][1], color=bqzd[labels[i]], marker='x')
为了不遮挡,放在左上角:
#左上角打标注 plt.legend(loc = 'upper left')

相关文章推荐
- 【ML学习笔记】13:k-近邻算法做数值特征分类
- 初学ML笔记N0.2——生成学习算法
- OpenCV学习笔记——小试随机森林(random forest)算法ml
- ML:Scikit-Learn 学习笔记(3) --- Nearest Neighbors 最近邻 回归及相关算法
- 初学ML笔记N0.2——生成学习算法
- 初学ML笔记N0.2——生成学习算法
- Python 学习笔记(Machine Learning In Action)K-近邻算法(KNN)机器学习实战
- 机器学习笔记--K-近邻算法(二)
- 初学ML笔记N0.2——生成学习算法
- 【ML学习笔记】朴素贝叶斯算法的demo(机器学习实战例子)
- 机器学习实战笔记(1)——k-近邻算法
- 初学ML笔记N0.2——生成学习算法
- 【算法学习笔记】12.数据结构基础 图的初步1
- 学习笔记之K-近邻算法
- 【机器学习】k-近邻算法(kNN) 学习笔记
- 初学ML笔记N0.2——生成学习算法
- 韩顺平_PHP程序员玩转算法公开课(第一季)12_双向链表crud操作之_水浒英雄排行_学习笔记_源代码图解_PPT文档整理
- 【算法学习笔记】12.数据结构基础 图的初步1
- 初学ML笔记N0.2——生成学习算法
- 机器学习笔记(8)---K-近邻算法(6)---KNN算法学习总结