Datax与hadoop2.x兼容部署与实际项目应用工作记录分享
2017-12-21 21:02
645 查看
一、概述
Hadoop的版本更新挺快的,已经到了2.4,但是其周边工具的更新速度还是比较慢的,一些旧的周边工具版本对hadoop2.x的兼容性做得还不完善,特别是sqoop。最近,在为hadoop2.2.0找适合的sqoop版本时遇到了很多问题。尝试了多个sqoop1.4.x版本的直接简单粗暴的报版本不兼容问题,其中测了sqoop-1.4.4.bin__hadoop-0.23这个版本,在该版本中直接用sqoop的脚本export
HDFS的数据是没有问题的,但是一旦调用JAVA API来进行对HDFS的数据的export的时候就各种不兼容问题,原因是这个版本的API也是基于hadoop1.x来写的。另外还尝试了使用sqoop2(之前blog写过关于sqoop2的部署和使用情况:http://zengzhaozheng.blog.51cto.com/8219051/1431882 ),这个版本取消了sqoop1的脚本执行方式,可以采取交互式、api或者rest的方式工作,但是我在使用的过程中还是存在的一些问题:sqoop2(我用的是1.99.3)无法指定列的分隔符、对\N等字符的处理有问题、对列值的类型判断存在问题等(其详细问题所在请看,sqoop1.99.3源代码的org.apache.sqoop.job.io.Data类)。
这个礼拜终于找到了一个比较好的方案来取代sqoop作为HDFS到mysql的数据export模块,那就是大淘宝开源的datax。虽然datax采用的是单机方式的作业方式,但是经过试验我对比了一下其和sqoop性能上的差异,在数据量不是特别大的情况下datax和sqoop的性能相差不是很明显的,在少量数据的情况下datax的性能稍微好点。
这篇blog将简单介绍一下这个datax这个框架以及它的用法,特别地说说如果修改datax才能使得datax运行在hadoop2.x上(datax是基于hadoop1.x进行开发的)。另外,主要和大家分享一下我在自己项目中如何使用datax,如何通过自己编写的shell脚本将datax、mysql和项目粘合起来。
二、datax简介和datax在hadoop2.x上的兼容部署
1、datax简介
DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换。Datax框架中我最欣赏的就是基于插件的模式,你在部署的时候可以只安装那些用到的Reader/Writer插件rpm包,没有用的可以不用安装。同时,你也可以根据自己的特殊需求很快的写出Reader、Writer。Datax采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问。Datax的运行方式采用stand-alone方式,在数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC通信。下面是一个来自大淘宝开源官网的datax架构图:
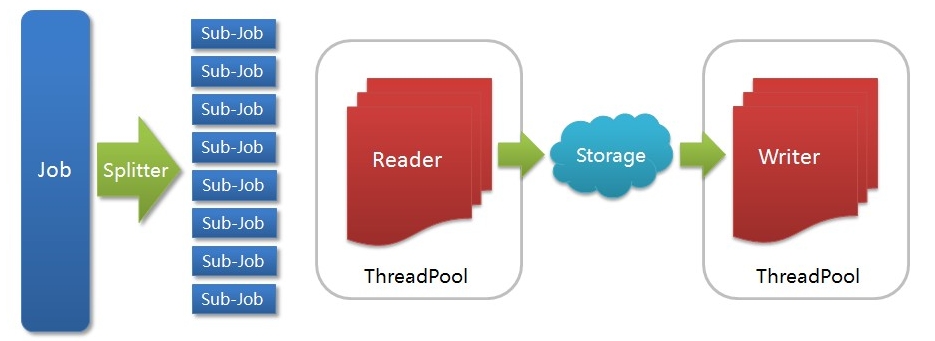
各个组件的作用:
Job: 一道数据同步作业
Splitter: 作业切分模块,将一个大任务与分解成多个可以并发的小任务.
Sub-job: 数据同步作业切分后的小任务
Reader(Loader): 数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX
Storage: Reader和Writer通过Storage交换数据
Writer(Dumper): 数据写出模块,负责将数据从DataX导入至目的数据地
Datax内置插件:
DataX框架内部通过双缓冲队列、线程池封装等技术,集中处理了高速数据交换遇到的问题,提供简单的接口与插件交互,插件分为Reader和Writer两类,基于框架提供的插件接口,可以十分便捷的开发出需要的插件。比如想要从oracle导出数据到mysql,那么需要做的就是开发出OracleReader和MysqlWriter插件,装配到框架上即可。并且这样的插件一般情况下在其他数据交换场合是可以通用的。更大的惊喜是我们已经开发了如下插件:
Reader插件
hdfsreader : 支持从hdfs文件系统获取数据。
mysqlreader: 支持从mysql数据库获取数据。
sqlserverreader: 支持从sqlserver数据库获取数据。
oraclereader : 支持从oracle数据库获取数据。
streamreader: 支持从stream流获取数据(常用于测试)
httpreader : 支持从http URL获取数据。
Writer插件
hdfswriter:支持向hdbf写入数据。
mysqlwriter:支持向mysql写入数据。
oraclewriter:支持向oracle写入数据。
streamwriter:支持向stream流写入数据。(常用于测试)
2、datax在hadoop2.x上的兼容部署
Datax是基于Hadoop1.x开发的,因此要想基于HADOOP2.x使用hdfsreader和hdfswriter插件,那么必须对这些插件的本地库以及一些jar包替换掉,同时要增加Hadoop2.x所需的依赖包,下面以hdfsreader为例说明:
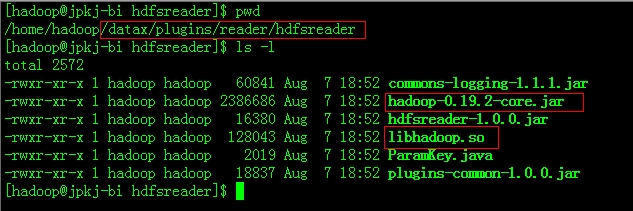
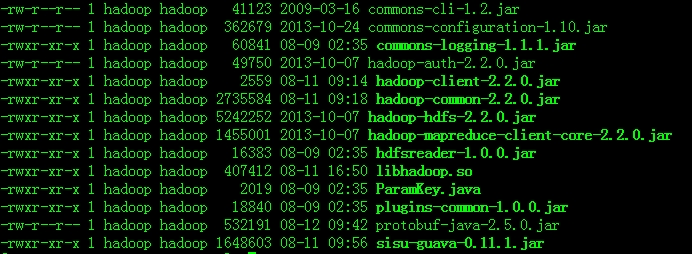
进入到plugins目录找到hdfsreader,将hadoop-0.19.2-core.jar删除,将本地库替换为$HAOOP_HOME2.x/lib/native/libhadoop.so。同时添加Hadoop2.x的依赖包,如下图:
另外,Datax需要hadoop1.x的hadoop-core.xml配置文件,但是hadoop2.x中不存在这个文件,这里有一个解决方法,就是将各个配置文件的配置项都集中写到一个新建的配置文件中,单独有datax使用,这个配置文件在datax的job xml文件由参数hadoop-conf配上。到现在为止,datax与hadoop2.x的兼容性修改已经完成了。
还要做其他环境的调整,确保java版本>=1.6,python的版本>=2.6(对于python的版本选择上,个人推荐2.6或者2.7,如果pytyon版本上到3.x的话会有错误,个人经验)。最后修改一下各个插件的rpm包的build路径:
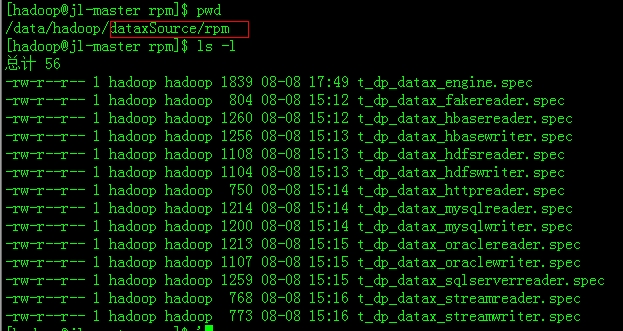
下面以t_dp_datax_engine.spec为例子:
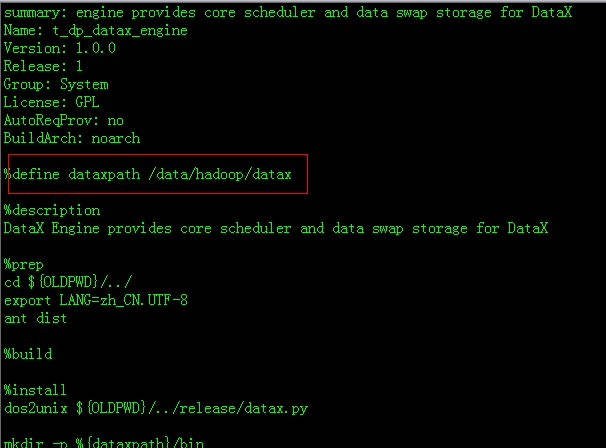
上面红色方框的地方是指build rpm 插件后新产生的文件夹位置,改为自己编辑的目录。
下面以t_dp_datax_engine.spec为例子,看看怎么build rpm 插件:
具体执行过程如下:
1、请先check out一份DataX源码,并cd切换到DataX源码中的rpm目录
2、编译打包DataX engine包,使用rpmbuild --ba t_dp_datax_engine.spec(请确保有root权限),打包生成的rpm后如下图所示

Rpm制作完成后,即可分发、安装,例如使用
rpm -ivh t_dp_datax_engine.rpm
即可安装DataX engine 包,需要注意的是engine的rpm地址源自于上图的截图中信息。
如下图:

安装完成后,在/home/taobao/datax/目录下会存在如下文件:

其他的插件按照这种方式按照好就ok了。
三、datax的实际应用记录分享
在blog的这部分主要分享一下我对datax使用的一个小案例,希望能够给初用datax的同学一点点参照。
具体业务场景:
需要将存储在HDFS上的一些表export到mysql中,不希望datax对每一个表的export操作都产生一个job xml文件,希望对不同的表动态使用同一个 job xml文件(这个用datax配置文件动态参数结合shell实现)。同时,根据公司业务的需求当不同的HDFS 表export到mysql的前后还需要做一些基于mysql的DML操作(这个可以通过datax 配置文件中的pre以及post参数进行配置,但是我为了方便流程的控制用shell取代了)。
实现步骤:
步骤1:
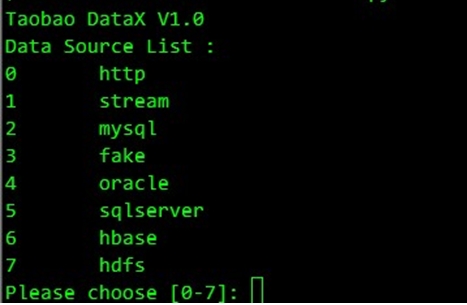
执行$DATAX_HOME/bin/datax.py -e命令,选择data source来源,这里我们选择7:
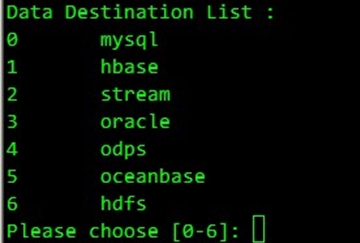
接着选择export的目标源,这个我们选择0:
步骤2:
根据自己的业务需求和HADOOP的相应环境配置产生的job xml,进入到$DATAX_HOME/jobs,编辑job配置文件,我的配置如下(里边的一些动态参数有下面我自己写的Shell中进行控制):
步骤3:
编写Shell脚本export_hdfs2mysql.sh对整个Datax作业根据业务需求进行控制:
简单说说我这个shell脚本的用途,主要是对datax中的job配置文件的动态参数进行控制。另外,根据公司业务的不同需求,这十几个需要导入mysql的表其中有些表在导入之前和导入之后需要做不同的完善工作,这个通过这shell来控制。对于这个Shell脚本我是花了点时间进行重构的,功能点还是比较清晰、简洁的。
步骤4:
执行脚本:nohup ./export_hdfs2mysql.sh 20140815 >> ./../idigg_task/logs/export.log & 大功告成。
三、总结
本blog主要介绍了datax框架、对它的部署、与hadoop2.x的兼容性修改和结合我的个人开发案例说了下datax的实际使用。整个Datax的部署和使用过程还是比较方便的,其效率也是相当不错,而且性能是可控的(通过job配置文件配置读、写线程数)。在大多数情况下,datax和sqoop的性能上可以作为互补,是一个相当不错的产品。另外,说说Shell。Shell是我个人最喜欢的一种威武工具,它不仅具有天然的操作系统原生优势,同时它具有强大的粘合作用,可以将各种技术非常完美的粘合在一个项目之中。熟练的掌握Shell的编写,可以使一个开发者的战斗力上升几个等级,这个是我在实际工作中总结出来的绝对的真理。
Hadoop的版本更新挺快的,已经到了2.4,但是其周边工具的更新速度还是比较慢的,一些旧的周边工具版本对hadoop2.x的兼容性做得还不完善,特别是sqoop。最近,在为hadoop2.2.0找适合的sqoop版本时遇到了很多问题。尝试了多个sqoop1.4.x版本的直接简单粗暴的报版本不兼容问题,其中测了sqoop-1.4.4.bin__hadoop-0.23这个版本,在该版本中直接用sqoop的脚本export
HDFS的数据是没有问题的,但是一旦调用JAVA API来进行对HDFS的数据的export的时候就各种不兼容问题,原因是这个版本的API也是基于hadoop1.x来写的。另外还尝试了使用sqoop2(之前blog写过关于sqoop2的部署和使用情况:http://zengzhaozheng.blog.51cto.com/8219051/1431882 ),这个版本取消了sqoop1的脚本执行方式,可以采取交互式、api或者rest的方式工作,但是我在使用的过程中还是存在的一些问题:sqoop2(我用的是1.99.3)无法指定列的分隔符、对\N等字符的处理有问题、对列值的类型判断存在问题等(其详细问题所在请看,sqoop1.99.3源代码的org.apache.sqoop.job.io.Data类)。
这个礼拜终于找到了一个比较好的方案来取代sqoop作为HDFS到mysql的数据export模块,那就是大淘宝开源的datax。虽然datax采用的是单机方式的作业方式,但是经过试验我对比了一下其和sqoop性能上的差异,在数据量不是特别大的情况下datax和sqoop的性能相差不是很明显的,在少量数据的情况下datax的性能稍微好点。
这篇blog将简单介绍一下这个datax这个框架以及它的用法,特别地说说如果修改datax才能使得datax运行在hadoop2.x上(datax是基于hadoop1.x进行开发的)。另外,主要和大家分享一下我在自己项目中如何使用datax,如何通过自己编写的shell脚本将datax、mysql和项目粘合起来。
二、datax简介和datax在hadoop2.x上的兼容部署
1、datax简介
DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换。Datax框架中我最欣赏的就是基于插件的模式,你在部署的时候可以只安装那些用到的Reader/Writer插件rpm包,没有用的可以不用安装。同时,你也可以根据自己的特殊需求很快的写出Reader、Writer。Datax采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问。Datax的运行方式采用stand-alone方式,在数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC通信。下面是一个来自大淘宝开源官网的datax架构图:
各个组件的作用:
Job: 一道数据同步作业
Splitter: 作业切分模块,将一个大任务与分解成多个可以并发的小任务.
Sub-job: 数据同步作业切分后的小任务
Reader(Loader): 数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX
Storage: Reader和Writer通过Storage交换数据
Writer(Dumper): 数据写出模块,负责将数据从DataX导入至目的数据地
Datax内置插件:
DataX框架内部通过双缓冲队列、线程池封装等技术,集中处理了高速数据交换遇到的问题,提供简单的接口与插件交互,插件分为Reader和Writer两类,基于框架提供的插件接口,可以十分便捷的开发出需要的插件。比如想要从oracle导出数据到mysql,那么需要做的就是开发出OracleReader和MysqlWriter插件,装配到框架上即可。并且这样的插件一般情况下在其他数据交换场合是可以通用的。更大的惊喜是我们已经开发了如下插件:
Reader插件
hdfsreader : 支持从hdfs文件系统获取数据。
mysqlreader: 支持从mysql数据库获取数据。
sqlserverreader: 支持从sqlserver数据库获取数据。
oraclereader : 支持从oracle数据库获取数据。
streamreader: 支持从stream流获取数据(常用于测试)
httpreader : 支持从http URL获取数据。
Writer插件
hdfswriter:支持向hdbf写入数据。
mysqlwriter:支持向mysql写入数据。
oraclewriter:支持向oracle写入数据。
streamwriter:支持向stream流写入数据。(常用于测试)
2、datax在hadoop2.x上的兼容部署
Datax是基于Hadoop1.x开发的,因此要想基于HADOOP2.x使用hdfsreader和hdfswriter插件,那么必须对这些插件的本地库以及一些jar包替换掉,同时要增加Hadoop2.x所需的依赖包,下面以hdfsreader为例说明:
进入到plugins目录找到hdfsreader,将hadoop-0.19.2-core.jar删除,将本地库替换为$HAOOP_HOME2.x/lib/native/libhadoop.so。同时添加Hadoop2.x的依赖包,如下图:
另外,Datax需要hadoop1.x的hadoop-core.xml配置文件,但是hadoop2.x中不存在这个文件,这里有一个解决方法,就是将各个配置文件的配置项都集中写到一个新建的配置文件中,单独有datax使用,这个配置文件在datax的job xml文件由参数hadoop-conf配上。到现在为止,datax与hadoop2.x的兼容性修改已经完成了。
还要做其他环境的调整,确保java版本>=1.6,python的版本>=2.6(对于python的版本选择上,个人推荐2.6或者2.7,如果pytyon版本上到3.x的话会有错误,个人经验)。最后修改一下各个插件的rpm包的build路径:
下面以t_dp_datax_engine.spec为例子:
上面红色方框的地方是指build rpm 插件后新产生的文件夹位置,改为自己编辑的目录。
下面以t_dp_datax_engine.spec为例子,看看怎么build rpm 插件:
具体执行过程如下:
1、请先check out一份DataX源码,并cd切换到DataX源码中的rpm目录
2、编译打包DataX engine包,使用rpmbuild --ba t_dp_datax_engine.spec(请确保有root权限),打包生成的rpm后如下图所示
Rpm制作完成后,即可分发、安装,例如使用
rpm -ivh t_dp_datax_engine.rpm
即可安装DataX engine 包,需要注意的是engine的rpm地址源自于上图的截图中信息。
如下图:
安装完成后,在/home/taobao/datax/目录下会存在如下文件:
其他的插件按照这种方式按照好就ok了。
三、datax的实际应用记录分享
在blog的这部分主要分享一下我对datax使用的一个小案例,希望能够给初用datax的同学一点点参照。
具体业务场景:
需要将存储在HDFS上的一些表export到mysql中,不希望datax对每一个表的export操作都产生一个job xml文件,希望对不同的表动态使用同一个 job xml文件(这个用datax配置文件动态参数结合shell实现)。同时,根据公司业务的需求当不同的HDFS 表export到mysql的前后还需要做一些基于mysql的DML操作(这个可以通过datax 配置文件中的pre以及post参数进行配置,但是我为了方便流程的控制用shell取代了)。
实现步骤:
步骤1:
执行$DATAX_HOME/bin/datax.py -e命令,选择data source来源,这里我们选择7:
接着选择export的目标源,这个我们选择0:
步骤2:
根据自己的业务需求和HADOOP的相应环境配置产生的job xml,进入到$DATAX_HOME/jobs,编辑job配置文件,我的配置如下(里边的一些动态参数有下面我自己写的Shell中进行控制):
编写Shell脚本export_hdfs2mysql.sh对整个Datax作业根据业务需求进行控制:
步骤4:
执行脚本:nohup ./export_hdfs2mysql.sh 20140815 >> ./../idigg_task/logs/export.log & 大功告成。
三、总结
本blog主要介绍了datax框架、对它的部署、与hadoop2.x的兼容性修改和结合我的个人开发案例说了下datax的实际使用。整个Datax的部署和使用过程还是比较方便的,其效率也是相当不错,而且性能是可控的(通过job配置文件配置读、写线程数)。在大多数情况下,datax和sqoop的性能上可以作为互补,是一个相当不错的产品。另外,说说Shell。Shell是我个人最喜欢的一种威武工具,它不仅具有天然的操作系统原生优势,同时它具有强大的粘合作用,可以将各种技术非常完美的粘合在一个项目之中。熟练的掌握Shell的编写,可以使一个开发者的战斗力上升几个等级,这个是我在实际工作中总结出来的绝对的真理。

相关文章推荐
- Datax与hadoop2.x兼容部署与实际项目应用工作记录分享 推荐
- 分享并记录云服务器上部署Web项目使用公网IP访问的jing
- 分享并记录云服务器上部署Web项目使用公网IP访问的jing
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享
- 项目实际部署记录(ubuntu)
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享 推荐
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享
- 实际工作中:----FastDFS在项目中的应用
- 【无私分享:从入门到精通ASP.NET MVC】从0开始,一起搭框架、做项目(6) 控制器基类 主要做登录用户、权限认证、日志记录等工作
- 工作日志记录:关于脉脉这款应用的默认用户头像的一种实现方法
- 菜鸟-手把手教你把Acegi应用到实际项目中(11)-切换用户
- javaweb监听器记录应用的在线人数[从学习到工作(四)]
- bash实战篇-数组在工作中的实际应用(测试环境发布脚本) 推荐
- HTML5 placeholder实际应用经验分享及拓展
- JPA级联(一对一 一对多 多对多)注解【实际项目中摘取的】并非自己实际应用
- 项目管理实际经验分享
- OracleWeblogic12C安装教程和在IDEA部署WebLogic12C项目分享经验
- Java实际项目中应用的一些技巧(不断更新)
- AtomicInteger在实际项目中的应用
- ckplayer 项目实际应用代码整理,支持标清,高清,超清切换!