人脸识别算法(一)---eigenfaces
2017-12-21 16:27
232 查看
1 向量的表示及协方差矩阵:http://blog.csdn.net/songzitea/article/details/18219237
矩阵相乘、向量内积的意义:
A⋅B=|A|cos(a)
也就是说,设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度
向量(x,y)实际上表示线性组合:
x(1,0)T+y(0,1)T
要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值
将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
(1/2√−1/2√1/2√1/2√)(32)=(5/2√−1/2√)
例如(1,1),(2,2),(3,3),想变换到刚才那组基上,则可以这样表示:
(1/2√−1/2√1/2√1/2√)(112233)=(2/2√04/2√06/2√0)
于是一组向量的基变换被干净的表示为矩阵的相乘。
两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。
方差:
Var(a)=1m∑i=1m(ai−μ)2
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
D=====1mYYT1m(PX)(PX)T1mPXXTPTP(1mXXT)PTPCPTD===
=
=1mYYT1m(PX)(PX)T1mPXXTPTP(1mXXT)PTPCPT
D====
1mYYT1m(PX)(PX)T1mPXXTPTP(1mXXT)PTPCPT

重点:
一副人脸表示一个列向量(d=H*w),将N个人脸按列写入一个矩阵X(d*N);
将X表示成一个用某组基P映射得到Y;使得Y是的协方差矩阵是一个对角阵(除对角线外其余为0);
即Y的每一维表示的向量都是互为90度的;我们的目的就是找到方差最大的维,这样的话使得投影后的距离最大(类似于二维投影到一维);使得协方差为0,投影的目的基,相互垂直;
分析协方差矩阵(此处的X只是举例子):
X=(a1b1a2b2⋯⋯ambm)
然后我们用X乘以X的转置,并乘上系数1/m:
1mXXT=⎛⎝⎜⎜⎜⎜⎜1m∑i=1ma2i1m∑i=1maibi1m∑i=1maibi1m∑i=1mb2i⎞⎠⎟⎟⎟⎟⎟
对角线上的是方差表示的是离散程度,越大越好;非对角线表示的是协方差,向量a b的协方差表示的是a b 之间的相关程度,在向量中 两个向量的协方差就是向量的内积除以维数m,协方差为0,就是内积为零,内积又等于

所以两向量的夹角为90度;
对 (1/m)XX(T),矩阵对角化即可,得到的特征向量组P,Y=PX,原来的向量被映射到P为基地的空间中,Y的协方差矩阵为对角阵,即Y的每一维表示的向量都是互为90度的;
协方差分析:
概率角度:协方差矩阵为正表示两变量有相同的变化趋势(正相关),协方差为负 表示两变量负相关;为0,表示不相关;
向量角度:等于0,表示向量夹角90度;
不对,好像和向量为90度,没有关系,向量为90度,也只是所有人脸在这一维的表示和其他维的表示为90度,好像没用啊;
协方差矩阵为正表示两变量有相同的变化趋势(正相关),协方差为负 表示两变量负相关;为0,表示不相关;
个人认为使得协方差为0,仅仅是为了,使得在新基地表示向量时,各个维的数据分布是互不相关的;
这是个问题,未完 待续???
2 人脸识别之特征脸方法(Eigenface)(MATLAB源码):http://blog.csdn.net/zouxy09/article/details/45276053
中心思想:
将高维数据投影到低维空间,并且在低维中数据排列的足够离散;
如:二维投影到一维,投影后在一维空间中,数据尽可能离散分布;
X:将所有人脸拉伸成为列向量,一列一列摆放为矩阵X;
将高维数据投影到低维空间 Y=PX;Y的协方差矩阵Y×Y'的对角线元素表示的是投影后的数据在某一维的方差,要尽量大;非对角线表示的是不同维度的协方差,要等于0,表示各维不相关;
缺点:只考虑投影的时候总体离散度最大,但是将同一类的也映射的十分离散;
解决:fisherface解决了这个问题;
英文文献:


PCA中第一定义总的离散矩阵:

PCA中选择w矩阵使得WSW的行列式最大(就是对角阵);
eigenface定义总体离散矩阵:
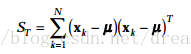
eigenface求解目标函数:

寻找矩阵W,使得Wt*St*W的行列式最大;因为St是满秩的显然,w为St的特征向量矩阵时,其行列式最大;
参考文献:Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection
Peter N. Belhumeur, Joao~
P. Hespanha, and David J. Kriegman (1997)
在这里因为我假设我要识别的未知人肯定是训练集合里有的,所以我通过比较,选择最小的k就是这个人脸对应的训练集合的脸。实际上,一般都是设定距离阈值,当距离小于阈值时说明要判别的脸和训练集内的第k个脸是同一个人的。当遍历所有训练集都大于阈值时,根据距离值的大小又可分为是新的人脸或者不是人脸的两种情况。根据训练集的不同,阈值设定并不是固定的。
下面就直接给出基于特征脸的人脸识别实现过程:
1)将训练集的每一个人脸图像都拉长一列,将他们组合在一起形成一个大矩阵A。假设每个人脸图像是MxM大小,那么拉成一列后每个人脸样本的维度就是d=MxM大小了。假设有N个人脸图像,那么样本矩阵A的维度就是dxN了。
2)将所有的N个人脸在对应维度上加起来,然后求个平均,就得到了一个“平均脸”。你把这个脸显示出来的话,还挺帅的哦。
3)将N个图像都减去那个平均脸图像,得到差值图像的数据矩阵Φ。
4)计算协方差矩阵C=ΦΦT。再对其进行特征值分解。就可以得到想要的特征向量(特征脸)了。
5)将训练集图像和测试集的图像都投影到这些特征向量上了,再对测试集的每个图像找到训练集中的最近邻或者k近邻啥的,进行分类即可。
3 OpenCV人脸识别实验(一)——特征脸(Eigenfaces)及其重构的源代码详解(opencv源码):http://blog.csdn.net/loveliuzz/article/details/73810334
4 人脸识别算法-特征脸方法(Eigenface)及python实现(原理讲的更加透彻):http://lib.csdn.net/article/python/43249
特征脸实现步骤(大家如果英语好可以看看这个点击打开链接):
1.获取包含M张人脸图像的集合

。我们这里使用15张xxx.normal.pgm来作为人脸训练图像,所以这里M=15.我们把导入的图像拉平,
本来是98*116的矩阵,我们拉平也就是一个11368*1的矩阵,然后M张放在一个大矩阵下,该矩阵为11368*15。
2.我们计算平均图像

,并获得偏差矩阵

。为11368*15.平均图像也就把每一行的15个元素平均计算,
这样最后的平均图像就是一个我们所谓的大众脸。然后每张人脸都减去这个平均图像,最后得到。


3.求得的协方差矩阵。并计算的特征值和特征向量。这是标准的PCA算法流程。但是在这里一个很大的问题就是,协方差矩阵的维度会大到无法计算,例如我们这个11368*15的矩阵,它的协方差矩阵是11368*11368,这个计算量非常大,而且储存也很困难,所以有大神推导出了下面的方法:
设 T 是预处理图像的矩阵,每一列对应一个减去均值图像之后的图像。则,协方差矩阵为 S = TTT ,并且对 S 的特征值分解为

然而, TTT 是一个非常大的矩阵。因此,如果转而使用如下的特征值分解
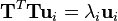
此时,我们发现如果在等式两边乘以T,可得到
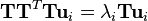
这就意味着,如果 ui 是 TTT的一个特征向量,则 vi = Tui 是 S 的一个特征向量。
看懂上面这一些需要一些线性代数知识,这里的T 就是上面的偏差矩阵, 反正到最后我们得TTT的一个特征向量,再用T与之相乘就是协方差矩阵的特征向量
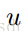
。而此时我们求的特征向量是11368*15的矩阵,
每一行(11368*1)如果变成图像大小矩阵(98*116)的话,都可以看做是一个新人脸,被称为特征脸。这里展现我试验中的其中一部分。

4.主成分分析。在求得的特征向量和特征值中,越大的特征值对于我们区分越重要,也就是我们说的主成分,我们只需要那些大的特征值对应的特征向量,
而那些十分小甚至为0的特征值对于我们来说,对应的特征向量几乎没有意义。在这里我们通过一个阈值selecthr来控制,当排序后的特征值的一部分相加
大于该阈值时,我们选择这部分特征值对应的特征向量,此时我们剩下的矩阵是11368*M',M'根据情况在变化。 这样我们不仅减少了计算量,而且保留
了主成分,减少了噪声的干扰。
5.这一步就是开始进行人脸识别了。此时我们导入一个新的人脸,我们使用上面主成分分析后得到的特征向量
,来求得一个每一个特征向量对于导入人脸的权重向量
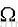
。

这里的

就是上面第2步求得的平均图像。 特征向量其实就是训练集合的图像与均值图像在该方向上的偏差,通过未知人脸在特征向量的投影,我们就可以知道未知人脸与平均图像在不同方向上的差距。此时我们用上面第2步我们求得的偏差矩阵的每一行做这样的处理,每一行都会得到一个权重向量。我们利用求得

与

的欧式距离来判断未知人脸与第k张训练人脸之间的差距。

在这里因为我假设我要识别的未知人肯定是训练集合里有的,所以我通过比较

,选择最小的k就是这个人脸对应的训练集合的脸。实际上,一般都是设定距离阈值,当距离小于阈值时说明要判别的脸和训练集内的第k个脸是同一个人的。当遍历所有训练集都大于阈值时,根据距离值的大小又可分为是新的人脸或者不是人脸的两种情况。根据训练集的不同,阈值设定并不是固定的。
矩阵相乘、向量内积的意义:
A⋅B=|A|cos(a)
也就是说,设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度
向量(x,y)实际上表示线性组合:
x(1,0)T+y(0,1)T
要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值
基变换的矩阵表示:
将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:(1/2√−1/2√1/2√1/2√)(32)=(5/2√−1/2√)
例如(1,1),(2,2),(3,3),想变换到刚才那组基上,则可以这样表示:
(1/2√−1/2√1/2√1/2√)(112233)=(2/2√04/2√06/2√0)
于是一组向量的基变换被干净的表示为矩阵的相乘。
两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。
方差:
Var(a)=1m∑i=1m(ai−μ)2
协方差矩阵对角化
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:D=====1mYYT1m(PX)(PX)T1mPXXTPTP(1mXXT)PTPCPTD===
=
=1mYYT1m(PX)(PX)T1mPXXTPTP(1mXXT)PTPCPT
D====
1mYYT1m(PX)(PX)T1mPXXTPTP(1mXXT)PTPCPT
重点:
一副人脸表示一个列向量(d=H*w),将N个人脸按列写入一个矩阵X(d*N);
将X表示成一个用某组基P映射得到Y;使得Y是的协方差矩阵是一个对角阵(除对角线外其余为0);
即Y的每一维表示的向量都是互为90度的;我们的目的就是找到方差最大的维,这样的话使得投影后的距离最大(类似于二维投影到一维);使得协方差为0,投影的目的基,相互垂直;
分析协方差矩阵(此处的X只是举例子):
X=(a1b1a2b2⋯⋯ambm)
然后我们用X乘以X的转置,并乘上系数1/m:
1mXXT=⎛⎝⎜⎜⎜⎜⎜1m∑i=1ma2i1m∑i=1maibi1m∑i=1maibi1m∑i=1mb2i⎞⎠⎟⎟⎟⎟⎟
对角线上的是方差表示的是离散程度,越大越好;非对角线表示的是协方差,向量a b的协方差表示的是a b 之间的相关程度,在向量中 两个向量的协方差就是向量的内积除以维数m,协方差为0,就是内积为零,内积又等于
所以两向量的夹角为90度;
对 (1/m)XX(T),矩阵对角化即可,得到的特征向量组P,Y=PX,原来的向量被映射到P为基地的空间中,Y的协方差矩阵为对角阵,即Y的每一维表示的向量都是互为90度的;
协方差分析:
概率角度:协方差矩阵为正表示两变量有相同的变化趋势(正相关),协方差为负 表示两变量负相关;为0,表示不相关;
向量角度:等于0,表示向量夹角90度;
不对,好像和向量为90度,没有关系,向量为90度,也只是所有人脸在这一维的表示和其他维的表示为90度,好像没用啊;
协方差矩阵为正表示两变量有相同的变化趋势(正相关),协方差为负 表示两变量负相关;为0,表示不相关;
个人认为使得协方差为0,仅仅是为了,使得在新基地表示向量时,各个维的数据分布是互不相关的;
这是个问题,未完 待续???
2 人脸识别之特征脸方法(Eigenface)(MATLAB源码):http://blog.csdn.net/zouxy09/article/details/45276053
中心思想:
将高维数据投影到低维空间,并且在低维中数据排列的足够离散;
如:二维投影到一维,投影后在一维空间中,数据尽可能离散分布;
X:将所有人脸拉伸成为列向量,一列一列摆放为矩阵X;
将高维数据投影到低维空间 Y=PX;Y的协方差矩阵Y×Y'的对角线元素表示的是投影后的数据在某一维的方差,要尽量大;非对角线表示的是不同维度的协方差,要等于0,表示各维不相关;
缺点:只考虑投影的时候总体离散度最大,但是将同一类的也映射的十分离散;
解决:fisherface解决了这个问题;
英文文献:
PCA中第一定义总的离散矩阵:
PCA中选择w矩阵使得WSW的行列式最大(就是对角阵);
eigenface定义总体离散矩阵:
eigenface求解目标函数:
寻找矩阵W,使得Wt*St*W的行列式最大;因为St是满秩的显然,w为St的特征向量矩阵时,其行列式最大;
参考文献:Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection
Peter N. Belhumeur, Joao~
P. Hespanha, and David J. Kriegman (1997)
在这里因为我假设我要识别的未知人肯定是训练集合里有的,所以我通过比较,选择最小的k就是这个人脸对应的训练集合的脸。实际上,一般都是设定距离阈值,当距离小于阈值时说明要判别的脸和训练集内的第k个脸是同一个人的。当遍历所有训练集都大于阈值时,根据距离值的大小又可分为是新的人脸或者不是人脸的两种情况。根据训练集的不同,阈值设定并不是固定的。
下面就直接给出基于特征脸的人脸识别实现过程:
1)将训练集的每一个人脸图像都拉长一列,将他们组合在一起形成一个大矩阵A。假设每个人脸图像是MxM大小,那么拉成一列后每个人脸样本的维度就是d=MxM大小了。假设有N个人脸图像,那么样本矩阵A的维度就是dxN了。
2)将所有的N个人脸在对应维度上加起来,然后求个平均,就得到了一个“平均脸”。你把这个脸显示出来的话,还挺帅的哦。
3)将N个图像都减去那个平均脸图像,得到差值图像的数据矩阵Φ。
4)计算协方差矩阵C=ΦΦT。再对其进行特征值分解。就可以得到想要的特征向量(特征脸)了。
5)将训练集图像和测试集的图像都投影到这些特征向量上了,再对测试集的每个图像找到训练集中的最近邻或者k近邻啥的,进行分类即可。
3 OpenCV人脸识别实验(一)——特征脸(Eigenfaces)及其重构的源代码详解(opencv源码):http://blog.csdn.net/loveliuzz/article/details/73810334
4 人脸识别算法-特征脸方法(Eigenface)及python实现(原理讲的更加透彻):http://lib.csdn.net/article/python/43249
特征脸实现步骤(大家如果英语好可以看看这个点击打开链接):
1.获取包含M张人脸图像的集合
。我们这里使用15张xxx.normal.pgm来作为人脸训练图像,所以这里M=15.我们把导入的图像拉平,
本来是98*116的矩阵,我们拉平也就是一个11368*1的矩阵,然后M张放在一个大矩阵下,该矩阵为11368*15。
2.我们计算平均图像
,并获得偏差矩阵
。为11368*15.平均图像也就把每一行的15个元素平均计算,
这样最后的平均图像就是一个我们所谓的大众脸。然后每张人脸都减去这个平均图像,最后得到。
3.求得的协方差矩阵。并计算的特征值和特征向量。这是标准的PCA算法流程。但是在这里一个很大的问题就是,协方差矩阵的维度会大到无法计算,例如我们这个11368*15的矩阵,它的协方差矩阵是11368*11368,这个计算量非常大,而且储存也很困难,所以有大神推导出了下面的方法:
设 T 是预处理图像的矩阵,每一列对应一个减去均值图像之后的图像。则,协方差矩阵为 S = TTT ,并且对 S 的特征值分解为
然而, TTT 是一个非常大的矩阵。因此,如果转而使用如下的特征值分解
此时,我们发现如果在等式两边乘以T,可得到
这就意味着,如果 ui 是 TTT的一个特征向量,则 vi = Tui 是 S 的一个特征向量。
看懂上面这一些需要一些线性代数知识,这里的T 就是上面的偏差矩阵, 反正到最后我们得TTT的一个特征向量,再用T与之相乘就是协方差矩阵的特征向量
。而此时我们求的特征向量是11368*15的矩阵,
每一行(11368*1)如果变成图像大小矩阵(98*116)的话,都可以看做是一个新人脸,被称为特征脸。这里展现我试验中的其中一部分。
4.主成分分析。在求得的特征向量和特征值中,越大的特征值对于我们区分越重要,也就是我们说的主成分,我们只需要那些大的特征值对应的特征向量,
而那些十分小甚至为0的特征值对于我们来说,对应的特征向量几乎没有意义。在这里我们通过一个阈值selecthr来控制,当排序后的特征值的一部分相加
大于该阈值时,我们选择这部分特征值对应的特征向量,此时我们剩下的矩阵是11368*M',M'根据情况在变化。 这样我们不仅减少了计算量,而且保留
了主成分,减少了噪声的干扰。
5.这一步就是开始进行人脸识别了。此时我们导入一个新的人脸,我们使用上面主成分分析后得到的特征向量
,来求得一个每一个特征向量对于导入人脸的权重向量
。
这里的
就是上面第2步求得的平均图像。 特征向量其实就是训练集合的图像与均值图像在该方向上的偏差,通过未知人脸在特征向量的投影,我们就可以知道未知人脸与平均图像在不同方向上的差距。此时我们用上面第2步我们求得的偏差矩阵的每一行做这样的处理,每一行都会得到一个权重向量。我们利用求得
与
的欧式距离来判断未知人脸与第k张训练人脸之间的差距。
在这里因为我假设我要识别的未知人肯定是训练集合里有的,所以我通过比较
,选择最小的k就是这个人脸对应的训练集合的脸。实际上,一般都是设定距离阈值,当距离小于阈值时说明要判别的脸和训练集内的第k个脸是同一个人的。当遍历所有训练集都大于阈值时,根据距离值的大小又可分为是新的人脸或者不是人脸的两种情况。根据训练集的不同,阈值设定并不是固定的。

相关文章推荐
- PCA人脸识别算法Matlab版
- 人脸识别算法初次了解
- 基于“视频图像”的人脸识别算法
- 人脸识别---基于深度学习和稀疏表达的人脸识别算法
- 新的人脸识别算法
- 人脸识别算法初次了解
- 基于神经网络的人脸识别算法的优缺点
- 基于“视频图像”的人脸识别算法
- 十五、人脸识别算法初次了解
- 人脸识别算法初次了解
- 深度学习与人脸识别系列(7)__人脸识别算法简要说明与总结
- 基于神经网络的人脸识别算法的优缺点
- 人脸识别算法初次了解
- 人脸识别算法初次了解
- 特征脸(Eigenfaces)
- 验证人脸识别算法
- Yale数据集上几个人脸识别算法的结果
- 人脸识别算法初次了解
- 机器学习: 特征脸算法 EigenFaces
- 基于“视频图像”的人脸识别算法