实时计算框架storm基础
2017-12-20 22:50
531 查看
1、实时计算阶段安排
day01 企业消息队列kafka接收实时产生的数据,用来计算。
day02 实时计算框架storm基础
day03 实时计算框架storm运行原理
day04 实时计算案例之日志告警系统
day05 实时计算案例之流量日志分析/交易风险控制系统
day06 推荐系统案例
day07 推荐系统数据清洗与存储(Hbase、Redis)
day08 搜索系统之elasticSearch
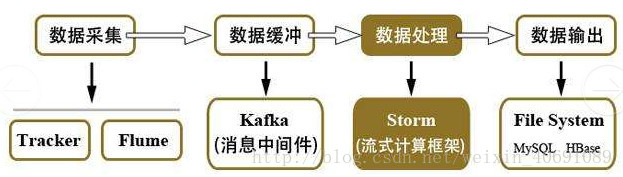
2、大数据课程整体结构
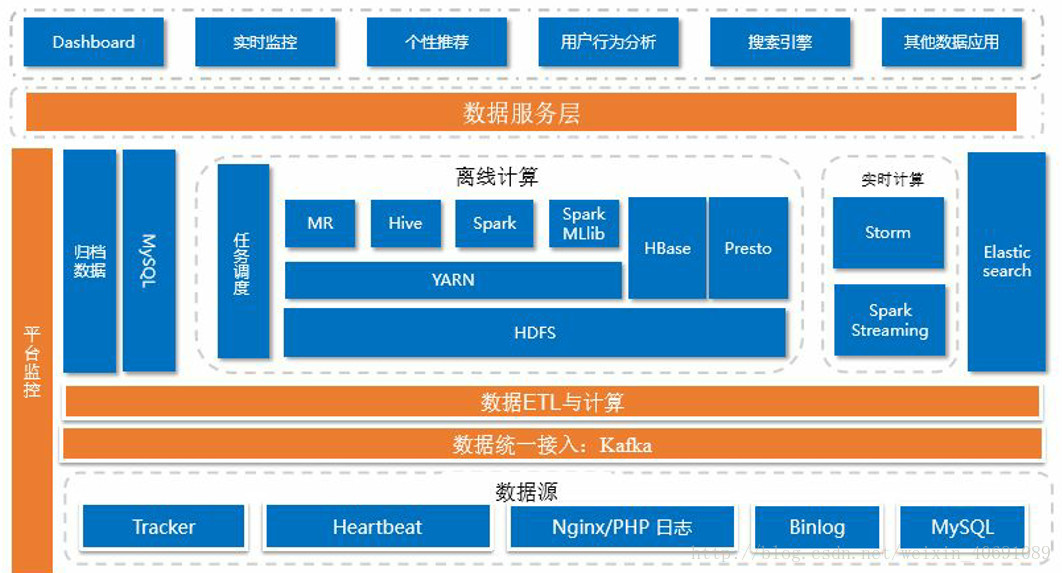
3、大数据实时存储

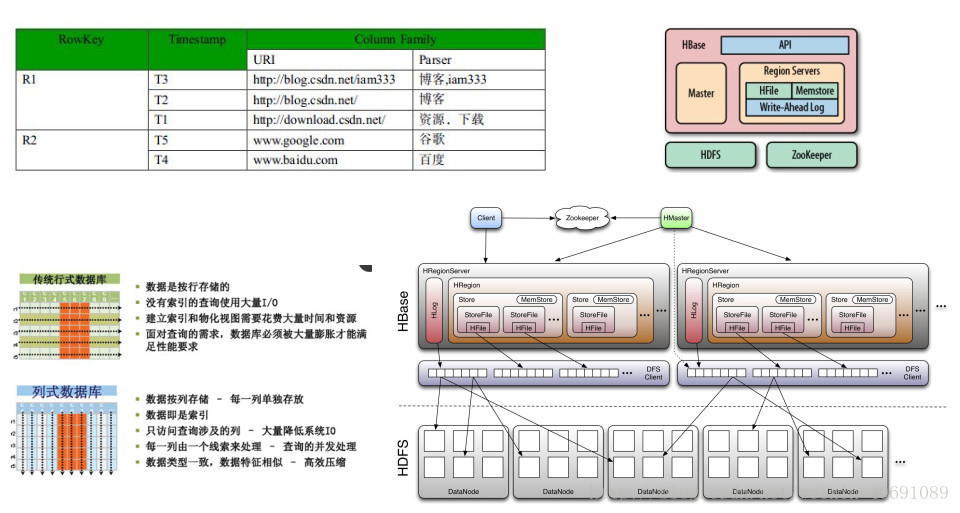
4、Kafka配置文件server.properties
修改三个地方:broker.id
每个kafka实例都具备一个唯一的id
log.dirs
Kafka用来存放消息的路径,需要在每台机器上创建
zookeeper.connect
Kafka信息存放在zookeeper中,需要制定zookeeper地址。
每个Kafka实例启动的时候,都会将自己的信息注册到zookeeper中。

配置文件
broker.id=0 4000 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/export/data/kafka num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=zk01:2181,zk02:2181,zk03:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0
5、Kafka启动需知(一键启动)
启动zookeeper集群一键启动脚本的环境变量配置
#set onekey env
export OK_HOME=/export/servers/oneKey
export PATH=${OK_HOME}/zk:$PATH
export PATH=${OK_HOME}/storm:$PATH
export PATH=${OK_HOME}/kafka:$PATH关于黑洞
一键启动的目录信息
-rw-r--r--. 1 root root 21 Nov 11 03:46 slave -rwxr-xr-x. 1 root root 160 Nov 11 03:46 startzk.sh -rwxr-xr-x. 1 root root 172 Nov 11 03:47 stopzk.sh
/export/servers/oneKey/zk
startzk.sh文件
cat /export/servers/oneKey/zk/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;nohup zkServer.sh start >/dev/nul* 2>&1 &"
}&
wait
donestopzk.sh 停止脚本
cat /export/servers/oneKey/zk/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep QuorumPeerMain |cut -c 1-4 |xargs kill -s 9"
}&
wait
done跨服务器运行命令
ssh hostname “command”
启动Kafka集群
环境变量
#set onekey env
export OK_HOME=/export/servers/oneKey
export PATH=${OK_HOME}/zk:$PATH
export PATH=${OK_HOME}/storm:$PATH
export PATH=${OK_HOME}/kafka:$PATHkafka环境变量配置
#set kafka env
export KAFKA_HOME=/export/servers/kafka
export PATH=${KAFKA_HOME}/bin:$PATH启动脚本
cat /export/servers/oneKey/kafka/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;nohup kafka-server-start.sh /export/servers/kafka/config/server.properties >/dev/nul* 2>&1 &"
}&
wait
done停止脚本
cat /export/servers/oneKey/kafka/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -c 1-4 |xargs kill -s 9 "
}&
wait
done6、Kafka配置文件详解

6.1、 producer端配置文件说明
#指定kafka节点列表,用于获取metadata,不必全部指定 metadata.broker.list=kafka01:9092,kafka02:9092,kafka03:9092 # 指定分区处理类。默认kafka.producer.DefaultPartitioner,表通过key哈希到对应分区 #partitioner.class=kafka.producer.DefaultPartitioner # 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩。压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定。 compression.codec=none # 指定序列化处理类 serializer.class=kafka.serializer.DefaultEncoder # 如果要压缩消息,这里指定哪些topic要压缩消息,默认empty,表示不压缩。 #compressed.topics= # 设置发送数据是否需要服务端的反馈,有三个值0,1,-1 # 0: producer不会等待broker发送ack # 1: 当leader接收到消息之后发送ack # -1: 当所有的follower都同步消息成功后发送ack. request.required.acks=0 # 在向producer发送ack之前,broker允许等待的最大时间 ,如果超时,broker将会向producer发送一个error ACK.意味着上一次消息因为某种原因未能成功(比如follower未能同步成功) request.timeout.ms=10000 # 同步还是异步发送消息,默认“sync”表同步,"async"表异步。异步可以提高发送吞吐量, 也意味着消息将会在本地buffer中,并适时批量发送,但是也可能导致丢失未发送过去的消息 producer.type=sync # 在async模式下,当message被缓存的时间超过此值后,将会批量发送给broker,默认为5000ms # 此值和batch.num.messages协同工作. queue.buffering.max.ms = 5000 # 在async模式下,producer端允许buffer的最大消息量 # 无论如何,producer都无法尽快的将消息发送给broker,从而导致消息在producer端大量沉积 # 此时,如果消息的条数达到阀值,将会导致producer端阻塞或者消息被抛弃,默认为10000 queue.buffering.max.messages=20000 # 如果是异步,指定每次批量发送数据量,默认为200 batch.num.messages=500 # 当消息在producer端沉积的条数达到"queue.buffering.max.meesages"后 # 阻塞一定时间后,队列仍然没有enqueue(producer仍然没有发送出任何消息) # 此时producer可以继续阻塞或者将消息抛弃,此timeout值用于控制"阻塞"的时间 # -1: 无阻塞超时限制,消息不会被抛弃 # 0:立即清空队列,消息被抛弃 queue.enqueue.timeout.ms=-1 # 当producer接收到error ACK,或者没有接收到ACK时,允许消息重发的次数 # 因为broker并没有完整的机制来避免消息重复,所以当网络异常时(比如ACK丢失) # 有可能导致broker接收到重复的消息,默认值为3. message.send.max.retries=3 # producer刷新topic metada的时间间隔,producer需要知道partition leader的位置,以及当前topic的情况 # 因此producer需要一个机制来获取最新的metadata,当producer遇到特定错误时,将会立即刷新 # (比如topic失效,partition丢失,leader失效等),此外也可以通过此参数来配置额外的刷新机制,默认值600000 topic.metadata.refresh.interval.ms=60000
6.2、broker端配置文件说明
#broker的全局唯一编号,不能重复 broker.id=0 #用来监听链接的端口,producer或consumer将在此端口建立连接 port=9092 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘IO的现成数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接受套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka运行日志存放的路径 log.dirs=/export/data/kafka/ #topic在当前broker上的分片个数 num.partitions=2 #用来恢复和清理data下数据的线程数量 num.recovery.threads.per.data.dir=1 #segment文件保留的最长时间,超时将被删除 log.retention.hours=1 #滚动生成新的segment文件的最大时间 log.roll.hours=1 #日志文件中每个segment的大小,默认为1G log.segment.bytes=1073741824 #周期性检查文件大小的时间 log.retention.check.interval.ms=300000 #日志清理是否打开 log.cleaner.enable=true #broker需要使用zookeeper保存meta数据 zookeeper.connect=zk01:2181,zk02:2181,zk03:2181 #zookeeper链接超时时间 zookeeper.connection.timeout.ms=6000 #partion buffer中,消息的条数达到阈值,将触发flush到磁盘 log.flush.interval.messages=10000 #消息buffer的时间,达到阈值,将触发flush到磁盘 log.flush.interval.ms=3000 #删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除 delete.topic.enable=true #此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092 unsuccessfu* 错误! host.name=kafka01 advertised.host.name=192.168.140.128
6.3、consumer端配置文件说明
# zookeeper连接服务器地址 zookeeper.connect=zk01:2181,zk02:2181,zk03:2181 # zookeeper的session过期时间,默认5000ms,用于检测消费者是否挂掉 zookeeper.session.timeout.ms=5000 #当消费者挂掉,其他消费者要等该指定时间才能检查到并且触发重新负载均衡 zookeeper.connection.timeout.ms=10000 # 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息 zookeeper.sync.time.ms=2000 #指定消费 group.id=itcast # 当consumer消费一定量的消息之后,将会自动向zookeeper提交offset信息 # 注意offset信息并不是每消费一次消息就向zk提交一次,而是现在本地保存(内存),并定期提交,默认为true auto.commit.enable=true # 自动更新时间。默认60 * 1000 auto.commit.interval.ms=1000 # 当前consumer的标识,可以设定,也可以有系统生成,主要用来跟踪消息消费情况,便于观察 conusmer.id=xxx # 消费者客户端编号,用于区分不同客户端,默认客户端程序自动产生 client.id=xxxx # 最大取多少块缓存到消费者(默认10) queued.max.message.chunks=50 # 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新 的consumer上,如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册 "Partition Owner registry"节点信息,但是有可能此时旧的consumer尚没有释放此节点, 此值用于控制,注册节点的重试次数. rebalance.max.retries=5 # 获取消息的最大尺寸,broker不会像consumer输出大于此值的消息chunk 每次feth将得到多条消息,此值为总大小,提升此值,将会消耗更多的consumer端内存 fetch.min.bytes=6553600 # 当消息的尺寸不足时,server阻塞的时间,如果超时,消息将立即发送给consumer fetch.wait.max.ms=5000 socket.receive.buffer.bytes=655360 # 如果zookeeper没有offset值或offset值超出范围。那么就给个初始的offset。有smallest、largest、anything可选,分别表示给当前最小的offset、当前最大的offset、抛异常。默认largest auto.offset.reset=smallest # 指定序列化处理类 derializer.class=kafka.serializer.DefaultDecoder
7、Kafka整体概念梳理

Producer :消息生产者,就是向kafka broker发消息的客户端。
第一个问题:数据分发机制
第二个问题:消息是否会丢失
Consumer :消息消费者,向kafka broker取消息的客户端
Topic :名称。
一类消息的分类名称,怎么区分一类消息?
Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
为什么要有Consumer Group? 提供并发和容错。
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
用来存放数据
Kafka为什么快?
pagecache:实时消费数据,针对实时消费,数据其实就在broker内存中。
sendfile:消费之前的数据,可以直接通过系统层面将数据发送出去。
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
为什么要进行partition?
副本机制
segment ,将保存在一个partition文件目录下的数据,切分为多个文件段。 主要方便快速删除和快速查找。
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
Replication:Kafka支持以Partition为单位对Message进行冗余备份,每个Partition都可以配置至少1个Replication(当仅1个Replication时即仅该Partition本身)。
副本中谁来当leader。
Leader:每个Replication集合中的Partition都会选出一个唯一的Leader,所有的读写请求都由Leader处理。其他Replicas从Leader处把数据更新同步到本地,过程类似大家熟悉的MySQL中的Binlog同步。每个Cluster当中会选举出一个Broker来担任Controller,负责处理Partition的Leader选举,协调Partition迁移等工作。
ISR(In-Sync Replica):是Replicas的一个子集,表示目前Alive且与Leader能够“Catch-up”的Replicas集合。由于读写都是首先落到Leader上,所以一般来说通过同步机制从Leader上拉取数据的Replica都会和Leader有一些延迟(包括了延迟时间和延迟条数两个维度),任意一个超过阈值都会把该Replica踢出ISR。每个Partition都有它自己独立的ISR。
8、Kafka细节补充
8.1、使用Kafka Producer生产数据并观察segment段的变化

public static void main(String[] args) {
//1、准备配置文件
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//2、创建KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
//3、发送数据
/**
* 在ProducerRecord构造参数中key的情况下,会根据key进行hash取模,得到partition的编号。
*
*/
while(true){
kafkaProducer.send(new ProducerRecord<String, String>("yum02", "我是很多内容……"));
}8.2、使用Kafka Producer生产数据的分发策略
The default partitioning strategy: * <li>If a partition is specified in the record, use it * <li>If no partition is specified but a key is present choose a partition based on a hash of the key * <li>If no partition or key is present choose a partition in a round-robin fashion
分发策略: 1)如果指定了partition,直接使用 2)如果没有指定partition,但是制定了key,可以使用key做hash取模 3)如果没有指定partition,又没有指定key,使用轮训的方式
//在ProducerRecord构造参数中有key的情况下,会根据key进行hash取模,得到partition的编号
kafkaProducer.send(new ProducerRecord<String, String>("yun02","num","Consumer Group "));
// 如果沒有key,也沒有partition就會輪訓
kafkaProducer.send(new ProducerRecord<String, String>("yum02", "afka Web "));
//如果指定了partition,就會使用partition
kafkaProducer.send(new ProducerRecord<String, String>("yun02",1,"num","value"));8.3、Kafka为什么那么快?
两个技术:pagecache:数据生产放入pagecache、数据读取从pagecache从读取,针对实时消费的情况。
sendfile:直接在系统层面将数据发送出去,减少应用层面的数据拷贝,提高效率针对消费历史数据的情况
8.4、zookeeper可视化工具使用

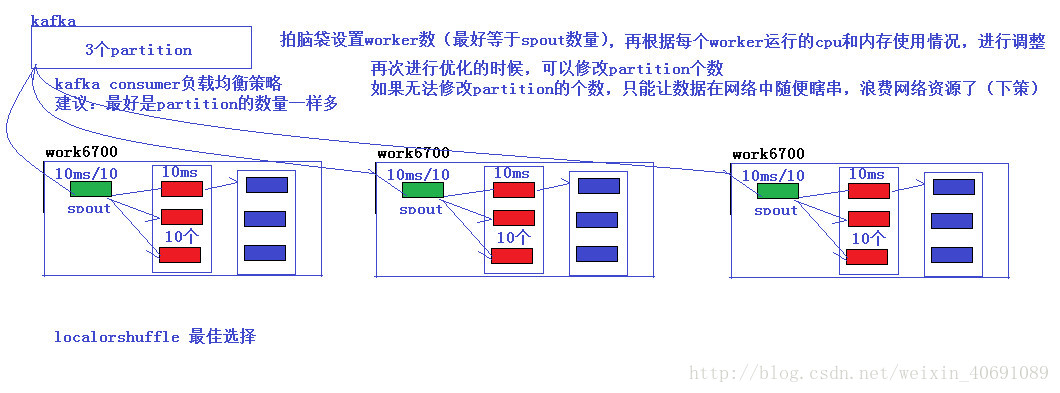
9、Storm一個項目究竟設置幾個worker?
一个项目每个环节(组件)设置多少个并行度?//设置应用程序的worker数
config.setNumWorkers(1);
//设置组件的并行度
topologyBuilder.setSpout("SentenceSpout",new SentenceSpout(),1);
topologyBuilder.setBolt("splitBolt",new SplitBolt(),1).shuffleGrouping("SentenceSpout");
topologyBuilder.setBolt("WordCountBolt",new WordCountBolt(),1).shuffleGrouping("splitBolt");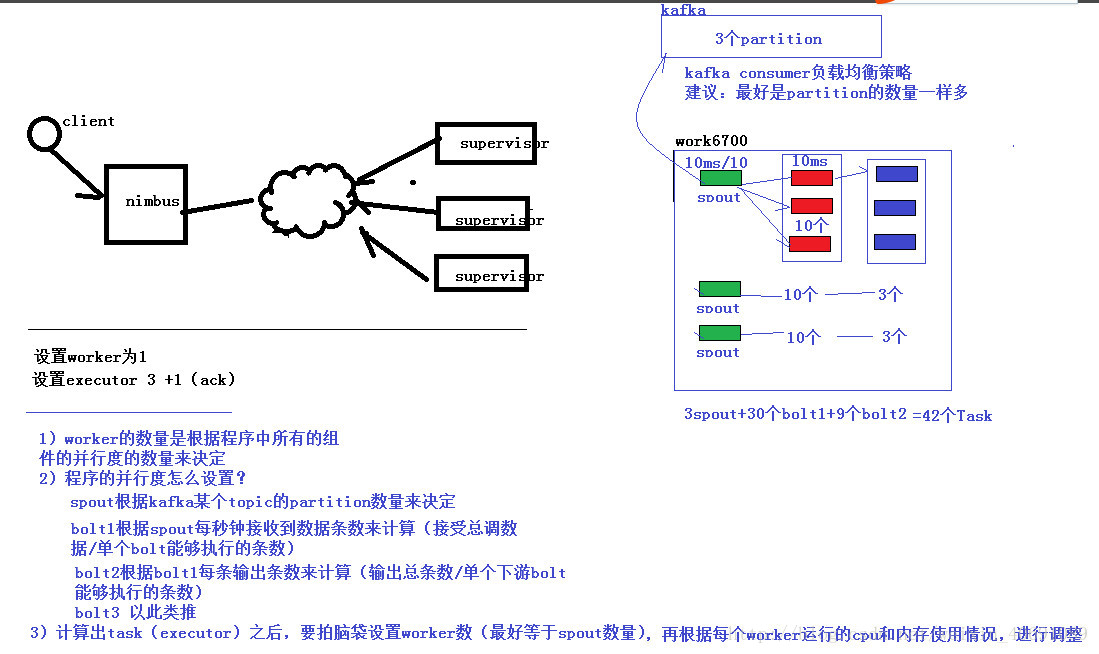
10、实时看板案例实战
项目范围不同岗位的人
看订单数、订单人数、订单金额
数据从何而来?
如何获取订单相关?
数据库?索引库?消息队列?选择哪一个?
数据库 select * from 表 groupby 分类1,分类2
压力大 ,业务部门不可能让你执行sql
分库分表,一条sql根本写不出来
索引库?
搜索引擎,当数据库的从库使用,可以做。
消息队列——>AMQ
订单系统每创建一个订单,都会将消息传入到amq。
数据部门通过flume或者其他的技术手段,将amq的数据同步到kafka
实时看板从kafka中获取数据,并进行计算。
程序架构
真实场景:订单系统———->AMQ—————Flume————Kafka———Storm————-Redis———–JavaWeb
案例场景:订单系统(producer)———–Kafka———Storm————-Redis———–JavaWeb
数据长什么样?
pinyougou: 订单编号、订单金额、商品名称、商品分类、商品。
真实订单:买家信息(手机号、省市县、姓名,账户、收货地址)、商品信息(sku详情挂上)、支付方式、卖家信息(手机号、省市县、姓名,账户、收货地址、公司信息)等等,差不多200多个字段。
伪造订单信息:
准备工作
准备数据格式
在kafka中创建topic (itcast_order,7个partition2个副本)
名称:itcast_order
设置分片数据:
根据数据量的大小,根据条数据
比如:500万订单,每条订单信息占用0.2M 每天100万M====1T
假设有7台机器(Kafka),创建7partition
设置副本
2个就可以了,3个就可以了。
执行创建命令:
bin/kafka-topics.sh --create --zookeeper zk01:2181 --replication-factor 2 --partitions 7 --topic itcast_order
使用kafkaproducer编写生产者发送数据,数据使用json串的方式发送
package cn.itcast.realtime.kanban.order;
import com.google.gson.Gson;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 模拟生成订单信息
* 1)准备一个订单的javaben
* 2) 发送订单信息到kafka
*/
public class OrderProducer {
public static void main(String[] args) {
//1、准备配置文件
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//2、创建KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
while (true) {
//3、发送数据
PaymentInfo paymentInfo = new PaymentInfo();
kafkaProducer.send(new ProducerRecord<String, String>("itcast_order", paymentInfo.random()));
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}package cn.itcast.realtime.kanban.order;
import com.alibaba.fastjson.JSON;
import com.google.gson.Gson;
import java.io.Serializable;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Random;
import java.util.UUID;
public class PaymentInfo implements Serializable {
private static final long serialVersionUID = -7958315778386204397L;
private String orderId;//订单编号
private Date createOrderTime;//订单创建时间
private String paymentId;//支付编号
private Date paymentTime;//支付时间
private String productId;//商品编号
private String productName;//商品名称
private long productPrice;//商品价格
private long promotionPrice;//促销价格
private String shopId;//商铺编号
private String shopName;//商铺名称
private String shopMobile;//商品电话
private long payPrice;//订单支付价格
private int num;//订单数量
/**
* <Province>19</Province>
* <City>1657</City>
* <County>4076</County>
*/
private String province; //省
private String city; //市
private String county;//县
//102,144,114
private String catagorys;
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getCounty() {
return county;
}
public void setCounty(String county) {
this.county = county;
}
public String getCatagorys() {
return catagorys;
}
public void setCatagorys(String catagorys) {
this.catagorys = catagorys;
}
public PaymentInfo() {
}
public PaymentInfo(String orderId, Date createOrderTime, String paymentId, Date paymentTime, String productId, String productName, long productPrice, long promotionPrice, String shopId, String shopName, String shopMobile, long payPrice, int num) {
this.orderId = orderId;
this.createOrderTime = createOrderTime;
this.paymentId = paymentId;
this.paymentTime = paymentTime;
this.productId = productId;
this.productName = productName;
this.productPrice = productPrice;
this.promotionPrice = promotionPrice;
this.shopId = shopId;
this.shopName = shopName;
this.shopMobile = shopMobile;
this.payPrice = payPrice;
this.num = num;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Date getCreateOrderTime() {
return createOrderTime;
}
public void setCreateOrderTime(Date createOrderTime) {
this.createOrderTime = createOrderTime;
}
public String getPaymentId() {
return paymentId;
}
public void setPaymentId(String paymentId) {
this.paymentId = paymentId;
}
public Date getPaymentTime() {
return paymentTime;
}
public void setPaymentTime(Date paymentTime) {
this.paymentTime = paymentTime;
}
public String getProductId() {
return productId;
}
public void setProductId(String productId) {
this.productId = productId;
}
public String getProductName() {
return productName;
}
public void setProductName(String productName) {
this.productName = productName;
}
public long getProductPrice() {
return productPrice;
}
public void setProductPrice(long productPrice) {
this.productPrice = productPrice;
}
public long getPromotionPrice() {
return promotionPrice;
}
public void setPromotionPrice(long promotionPrice) {
this.promotionPrice = promotionPrice;
}
public String getShopId() {
return shopId;
}
public void setShopId(String shopId) {
this.shopId = shopId;
}
public String getShopName() {
return shopName;
}
public void setShopName(String shopName) {
this.shopName = shopName;
}
public String getShopMobile() {
return shopMobile;
}
public void setShopMobile(String shopMobile) {
this.shopMobile = shopMobile;
}
public long getPayPrice() {
return payPrice;
}
public void setPayPrice(long payPrice) {
this.payPrice = payPrice;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
@Override
public String toString() {
return "PaymentInfo{" +
"orderId='" + orderId + '\'' +
", createOrderTime=" + createOrderTime +
", paymentId='" + paymentId + '\'' +
", paymentTime=" + paymentTime +
", productId='" + productId + '\'' +
", productName='" + productName + '\'' +
", productPrice=" + productPrice +
", promotionPrice=" + promotionPrice +
", shopId='" + shopId + '\'' +
", shopName='" + shopName + '\'' +
", shopMobile='" + shopMobile + '\'' +
", payPrice=" + payPrice +
", num=" + num +
'}';
}
public String random() {
this.orderId = UUID.randomUUID().toString().replaceAll("-", "");
this.paymentId = UUID.randomUUID().toString().replaceAll("-", "");
this.productPrice = new Random().nextInt(1000);
this.promotionPrice = new Random().nextInt(500);
this.payPrice = new Random().nextInt(480);
this.shopId = new Random().nextInt(200000) + "";
this.catagorys = new Random().nextInt(10000) + "," + new Random().nextInt(10000) + "," + new Random().nextInt(10000);
this.province = new Random().nextInt(23) + "";
this.city = new Random().nextInt(265) + "";
this.county = new Random().nextInt(1489) + "";
String date = "2015-11-11 12:22:12";
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
this.createOrderTime = simpleDateFormat.parse(date);
} catch (ParseException e) {
e.printStackTrace();
}
String jsonString = JSON.toJSONString(this);
return jsonString;
}
}
使用storm消费kafka中的数据(storm-kafka)

“`java
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
//创建一个TopologyBuilder用来组装任务信息
TopologyBuilder topologyBuilder = new TopologyBuilder();
// 设置kafkaspout
KafkaSpoutConfig.Builder
附1:Kafka常见问题
Kafka是什么?
分布式消息队列,类似于JMS。典型的生产者消费者模式。生产的数据存放到kafka的集群,集群由很多个broker组成
kafka集群的元数据保存在zookeeper上。
针对一个topic为什么要进行分区?
一般情况下,针对海量数据,都会将数据分为很多个部分(分片),单独存放在不同的机器上。如果一个topic的数据量非常大,我们要提前规划好分区数
producer根据分区数进行数据分发(分发策略partitioner)
针对一个分区,为什么要添加副本?
副本机制的存放时为了保证数据的安全(容错)添加副本添加多少个好?
添加副本副作用的,数据要同步到不同机器上,有大量的网络传输和磁盘占用。
根据业务对数据容错性,可以设置副本数为N。N=2
一个分区在broker是以目录的形式存放的,为什么分区下会设置segment段?
消息队列系统,一般都是实时,只能短时间保存数据。比如保存一个小时以内的数据。broker需要对分片的数据进行定时的删除,按照一定的数据量来保存数据,方便根据数据最后修改的时间进行删除。
producer数据生产不丢失的问题?
ACK (Acknowledgement)即是确认字符,在数据通信中,接收站发给发送站的一种传输类控制字符。表示发来的数据已确认接收无误。数据生产环节不丢失(ack机制)
如果是同步模式下
将发送状态设置为-1,是最为妥当的。但是,由于-1是让所有的副本都确定收到数据,这个过程会有较长的等待。面对海量的数据,如果每条消息都确认的话,效率会大大降低。
一般做法的做法: 设置让leader接收到数据就确认,就也是1,提高效率,这个方案可能会有丢失的风险。
如果是在异步模式下(也有ack)
生产的数据并不会立即发送给broker,会在produer段有个容器(队列)来临时缓存数据。
针对这个容器,有个阻塞设置。如果设置为0,就是立即丢弃数据。如果这是为-1,就永久阻塞。
如果在producer永久阻塞时,人为关闭producer代码所在进程,会立即清空队列中的数据,导致数据丢失。

相关文章推荐
- Storm分布式实时流计算框架相关技术总结
- storm实时流式计算框架集群搭建过程
- 实时计算框架之一:Storm之框架搭建
- 实时计算框架Storm本地模式搭建
- 实时流式计算框架Storm 0.9.0发布通知(中文版)
- storm实时流式计算框架集群搭建过程
- 实时流式计算框架Storm 0.9.0发布通知(中文版)
- storm实时流式计算框架集群搭建过程
- Storm实时计算框架的编程模式
- 实时计算框架之二:Storm之入门实例
- storm实时流式计算框架集群搭建过程
- 实时计算框架 Storm 的一步步搭建教程
- Clojure 实战 (5):Storm 实时计算框架
- Storm+Kafka实时计算框架搭建
- 从Storm和Spark 学习流式实时分布式计算的设计
- Twitter Storm 实时数据处理框架分析总结
- 从Storm和Spark 学习流式实时分布式计算的设计
- 实时计算开发-Storm从入门到精通
- Storm实时计算编程入门:概念讲解及编程实现
- Twitter Storm 实时数据处理框架分析总结