java8新特性:Stream多线程并行数据处理
2017-12-20 11:38
267 查看
将一个顺序执行的流转变成一个并发的流只要调用 parallel()方法
public static long parallelSum(long n){
return Stream.iterate(1L, i -> i +1).limit(n).parallel().reduce(0L,Long::sum);
}
并行流就是一个把内容分成多个数据块,并用不不同的线程分别处理每个数据块的流。最后合并每个数据块的计算结果。
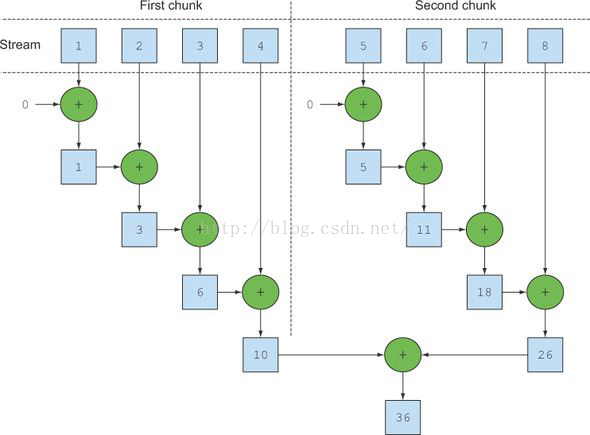
将一个并发流转成顺序的流只要调用sequential()方法
stream.parallel() .filter(...) .sequential() .map(...) .parallel() .reduce();
这两个方法可以多次调用, 只有最后一个调用决定这个流是顺序的还是并发的。
并发流使用的默认线程数等于你机器的处理器核心数。
通过这个方法可以修改这个值,这是全局属性。
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
并非使用多线程并行流处理数据的性能一定高于单线程顺序流的性能,因为性能受到多种因素的影响。
如何高效使用并发流的一些建议:
1. 如果不确定, 就自己测试。
2. 尽量使用基本类型的流 IntStream, LongStream, and DoubleStream
3. 有些操作使用并发流的性能会比顺序流的性能更差,比如limit,findFirst , 依赖元素顺序的操作在并发流中是极其消耗性能的 。findAny的性能就会好很多,应为不依赖顺序。
4. 考虑流中计算的性能(Q)和操作的性能(N)的对比, Q表示单个处理所需的时间, N表示需要处理的数量,如果Q的值越大, 使用并发流的性能就会越高。
5. 数据量不大时使用并发流,性能得不到提升。
6.考虑数据结构:并发流需要对数据进行分解,不同的数据结构被分解的性能时不一样的。
流的数据源和可分解性
7. 流的特性以及中间操作对流的修改都会对数据对分解性能造成影响。 比如固定大小的流在任务分解的时候就可以平均分配,但是如果有filter操作,那么流就不能预先知道在这个操作后还会剩余多少元素。
8. 考虑最终操作的性能:如果最终操作在合并并发流的计算结果时的性能消耗太大,那么使用并发流提升的性能就会得不偿失。
9.需要理解并发流实现机制:
fork/join 框架
fork/join框架是jdk1.7引入的,java8的stream多线程并非流的正是以这个框架为基础的,所以想要深入理解并发流就要学习fork/join框架。
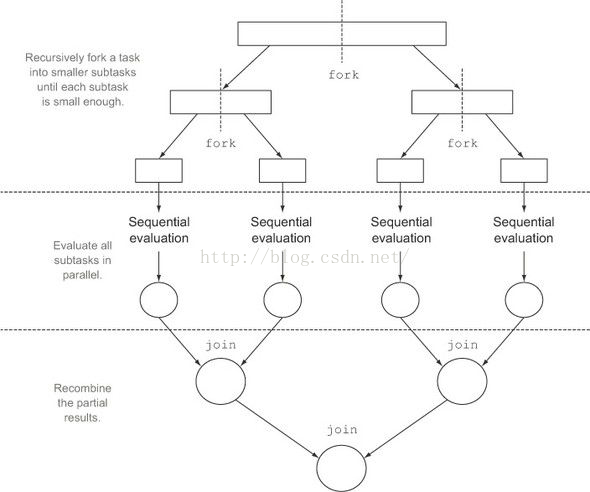
fork/join框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配线程池(ForkJoinPool)中的工作线程。要把任务提交到这个线程池,必须创建RecursiveTask<R>的一个子类,如果任务不返回结果则是RecursiveAction的子类。
fork/join框架流程示意图:
废话不多说,上代码:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
* Created by sunjin on 2016/7/5.
* 继承RecursiveTask来创建可以用于分支/合并的框架任务
*/
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
//要求和的数组
private final long[] numbers;
//子任务处理的数组开始和终止的位置
private final int start;
private final int end;
//不在将任务分解成子任务的阀值大小
public static final int THRESHOLD = 10000;
//用于创建组任务的构造函数
public ForkJoinSumCalculator(long[] numbers){
this(numbers, 0, numbers.length);
}
//用于递归创建子任务的构造函数
public ForkJoinSumCalculator(long[] numbers,int start,int end){
this.numbers = numbers;
this.start = start;
this.end = end;
}
//重写接口的方法
@Override
protected Long compute() {
//当前任务负责求和的部分的大小
int length = end - start;
//如果小于等于阀值就顺序执行计算结果
if(length <= THRESHOLD){
return computeSequentially();
}
//创建子任务来为数组的前一半求和
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2);
//将子任务拆分出去,丢到ForkJoinPool线程池异步执行。
leftTask.fork();
//创建子任务来为数组的后一半求和
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end);
//第二个任务直接使用当前线程计算而不再开启新的线程。
long rightResult = rightTask.compute();
//读取第一个子任务的结果,如果没有完成则等待。
long leftResult = leftTask.join();
//合并两个子任务的计算结果
return rightResult + leftResult;
}
//顺序执行计算的简单算法
private long computeSequentially(){
long sum = 0;
for(int i =start; i< end; i++){
sum += numbers[i];
}
return sum;
}
//提供给外部使用的入口方法
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
}
注意事项:
1. 调用join 方法要等到调用这个方法的线程的自己的任务完成之后。
2. 不要直接去调用ForkJoinPool的invoke方法 ,只需要调用RecursiveTask的fork或者compute。
3. 拆解任务时只需要调用一次fork执行其中一个子任务, 另一个子任务直接利用当前线程计算。应为fork方法只是在ForkJoinPool中计划一个任务。
4.任务拆分的粒度不宜太细,不否得不偿失。
工作盗取
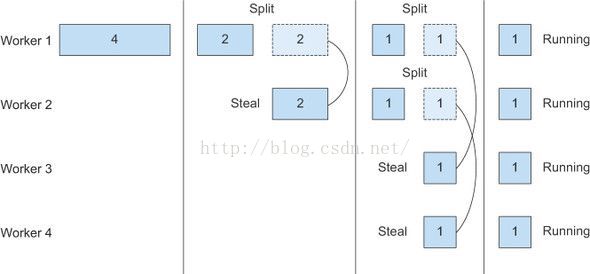
由于各种因素,即便任务拆分是平均的,也不能保证所有子任务能同时执行结束, 大部分情况是某些子任务已经结束, 其他子任务还有很多, 在这个时候就会有很多资源空闲, 所以fork/join框架通过工作盗取机制来保证资源利用最大化, 让空闲的线程去偷取正在忙碌的线程的任务。
在没有任务线程中的任务存在一个队列当中, 线程每次会从头部获取一个任务执行,执行完了再从queue的头部获取一个任务,直到队列中的所有任务执行完,这个线程偷取别的线程队列中的任务时会从队列到尾部获取任务,并且执行,直到所有任务执行结束。
从这个角度分析,任务的粒度越小, 资源利用越充分。
工作盗取示意图
可拆分迭代器Spliterator
它和Iterator一样也是用于遍历数据源中的元素,但是他是为并行执行而设计的。 java8 所有数据结构都实现了 这个接口, 一般情况不需要自己写实现代码。但是了解它的实现方式会让你对并行流的工作原理有更深的了解。(未完待续)
作者:明翼(XGogo)
出处:http://www.cnblogs.com/seaspring/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
不能用于商业用户,若商业使用请联系:
-------------
QQ:107463366
微信:shinelife
-------------
将一个顺序执行的流转变成一个并发的流只要调用 parallel()方法
public static long parallelSum(long n){
return Stream.iterate(1L, i -> i +1).limit(n).parallel().reduce(0L,Long::sum);
}
并行流就是一个把内容分成多个数据块,并用不不同的线程分别处理每个数据块的流。最后合并每个数据块的计算结果。
将一个并发流转成顺序的流只要调用sequential()方法
stream.parallel() .filter(...) .sequential() .map(...) .parallel() .reduce();
这两个方法可以多次调用, 只有最后一个调用决定这个流是顺序的还是并发的。
并发流使用的默认线程数等于你机器的处理器核心数。
通过这个方法可以修改这个值,这是全局属性。
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
并非使用多线程并行流处理数据的性能一定高于单线程顺序流的性能,因为性能受到多种因素的影响。
如何高效使用并发流的一些建议:
1. 如果不确定, 就自己测试。
2. 尽量使用基本类型的流 IntStream, LongStream, and DoubleStream
3. 有些操作使用并发流的性能会比顺序流的性能更差,比如limit,findFirst , 依赖元素顺序的操作在并发流中是极其消耗性能的 。findAny的性能就会好很多,应为不依赖顺序。
4. 考虑流中计算的性能(Q)和操作的性能(N)的对比, Q表示单个处理所需的时间, N表示需要处理的数量,如果Q的值越大, 使用并发流的性能就会越高。
5. 数据量不大时使用并发流,性能得不到提升。
6.考虑数据结构:并发流需要对数据进行分解,不同的数据结构被分解的性能时不一样的。
流的数据源和可分解性
7. 流的特性以及中间操作对流的修改都会对数据对分解性能造成影响。 比如固定大小的流在任务分解的时候就可以平均分配,但是如果有filter操作,那么流就不能预先知道在这个操作后还会剩余多少元素。
8. 考虑最终操作的性能:如果最终操作在合并并发流的计算结果时的性能消耗太大,那么使用并发流提升的性能就会得不偿失。
9.需要理解并发流实现机制:
fork/join 框架
fork/join框架是jdk1.7引入的,java8的stream多线程并非流的正是以这个框架为基础的,所以想要深入理解并发流就要学习fork/join框架。
fork/join框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配线程池(ForkJoinPool)中的工作线程。要把任务提交到这个线程池,必须创建RecursiveTask<R>的一个子类,如果任务不返回结果则是RecursiveAction的子类。
fork/join框架流程示意图:
废话不多说,上代码:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
* Created by sunjin on 2016/7/5.
* 继承RecursiveTask来创建可以用于分支/合并的框架任务
*/
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
//要求和的数组
private final long[] numbers;
//子任务处理的数组开始和终止的位置
private final int start;
private final int end;
//不在将任务分解成子任务的阀值大小
public static final int THRESHOLD = 10000;
//用于创建组任务的构造函数
public ForkJoinSumCalculator(long[] numbers){
this(numbers, 0, numbers.length);
}
//用于递归创建子任务的构造函数
public ForkJoinSumCalculator(long[] numbers,int start,int end){
this.numbers = numbers;
this.start = start;
this.end = end;
}
//重写接口的方法
@Override
protected Long compute() {
//当前任务负责求和的部分的大小
int length = end - start;
//如果小于等于阀值就顺序执行计算结果
if(length <= THRESHOLD){
return computeSequentially();
}
//创建子任务来为数组的前一半求和
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2);
//将子任务拆分出去,丢到ForkJoinPool线程池异步执行。
leftTask.fork();
//创建子任务来为数组的后一半求和
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end);
//第二个任务直接使用当前线程计算而不再开启新的线程。
long rightResult = rightTask.compute();
//读取第一个子任务的结果,如果没有完成则等待。
long leftResult = leftTask.join();
//合并两个子任务的计算结果
return rightResult + leftResult;
}
//顺序执行计算的简单算法
private long computeSequentially(){
long sum = 0;
for(int i =start; i< end; i++){
sum += numbers[i];
}
return sum;
}
//提供给外部使用的入口方法
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
}
注意事项:
1. 调用join 方法要等到调用这个方法的线程的自己的任务完成之后。
2. 不要直接去调用ForkJoinPool的invoke方法 ,只需要调用RecursiveTask的fork或者compute。
3. 拆解任务时只需要调用一次fork执行其中一个子任务, 另一个子任务直接利用当前线程计算。应为fork方法只是在ForkJoinPool中计划一个任务。
4.任务拆分的粒度不宜太细,不否得不偿失。
工作盗取
由于各种因素,即便任务拆分是平均的,也不能保证所有子任务能同时执行结束, 大部分情况是某些子任务已经结束, 其他子任务还有很多, 在这个时候就会有很多资源空闲, 所以fork/join框架通过工作盗取机制来保证资源利用最大化, 让空闲的线程去偷取正在忙碌的线程的任务。
在没有任务线程中的任务存在一个队列当中, 线程每次会从头部获取一个任务执行,执行完了再从queue的头部获取一个任务,直到队列中的所有任务执行完,这个线程偷取别的线程队列中的任务时会从队列到尾部获取任务,并且执行,直到所有任务执行结束。
从这个角度分析,任务的粒度越小, 资源利用越充分。
工作盗取示意图
可拆分迭代器Spliterator
它和Iterator一样也是用于遍历数据源中的元素,但是他是为并行执行而设计的。 java8 所有数据结构都实现了 这个接口, 一般情况不需要自己写实现代码。但是了解它的实现方式会让你对并行流的工作原理有更深的了解。(未完待续)
作者:明翼(XGogo)
出处:http://www.cnblogs.com/seaspring/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
不能用于商业用户,若商业使用请联系:
-------------
QQ:107463366
微信:shinelife
-------------
public static long parallelSum(long n){
return Stream.iterate(1L, i -> i +1).limit(n).parallel().reduce(0L,Long::sum);
}
并行流就是一个把内容分成多个数据块,并用不不同的线程分别处理每个数据块的流。最后合并每个数据块的计算结果。
将一个并发流转成顺序的流只要调用sequential()方法
stream.parallel() .filter(...) .sequential() .map(...) .parallel() .reduce();
这两个方法可以多次调用, 只有最后一个调用决定这个流是顺序的还是并发的。
并发流使用的默认线程数等于你机器的处理器核心数。
通过这个方法可以修改这个值,这是全局属性。
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
并非使用多线程并行流处理数据的性能一定高于单线程顺序流的性能,因为性能受到多种因素的影响。
如何高效使用并发流的一些建议:
1. 如果不确定, 就自己测试。
2. 尽量使用基本类型的流 IntStream, LongStream, and DoubleStream
3. 有些操作使用并发流的性能会比顺序流的性能更差,比如limit,findFirst , 依赖元素顺序的操作在并发流中是极其消耗性能的 。findAny的性能就会好很多,应为不依赖顺序。
4. 考虑流中计算的性能(Q)和操作的性能(N)的对比, Q表示单个处理所需的时间, N表示需要处理的数量,如果Q的值越大, 使用并发流的性能就会越高。
5. 数据量不大时使用并发流,性能得不到提升。
6.考虑数据结构:并发流需要对数据进行分解,不同的数据结构被分解的性能时不一样的。
流的数据源和可分解性
| 源 | 可分解性 |
| ArrayList | 非常好 |
| LinkedList | 差 |
| IntStream.range | 非常好 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
7. 流的特性以及中间操作对流的修改都会对数据对分解性能造成影响。 比如固定大小的流在任务分解的时候就可以平均分配,但是如果有filter操作,那么流就不能预先知道在这个操作后还会剩余多少元素。
8. 考虑最终操作的性能:如果最终操作在合并并发流的计算结果时的性能消耗太大,那么使用并发流提升的性能就会得不偿失。
9.需要理解并发流实现机制:
fork/join 框架
fork/join框架是jdk1.7引入的,java8的stream多线程并非流的正是以这个框架为基础的,所以想要深入理解并发流就要学习fork/join框架。
fork/join框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配线程池(ForkJoinPool)中的工作线程。要把任务提交到这个线程池,必须创建RecursiveTask<R>的一个子类,如果任务不返回结果则是RecursiveAction的子类。
fork/join框架流程示意图:
废话不多说,上代码:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
* Created by sunjin on 2016/7/5.
* 继承RecursiveTask来创建可以用于分支/合并的框架任务
*/
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
//要求和的数组
private final long[] numbers;
//子任务处理的数组开始和终止的位置
private final int start;
private final int end;
//不在将任务分解成子任务的阀值大小
public static final int THRESHOLD = 10000;
//用于创建组任务的构造函数
public ForkJoinSumCalculator(long[] numbers){
this(numbers, 0, numbers.length);
}
//用于递归创建子任务的构造函数
public ForkJoinSumCalculator(long[] numbers,int start,int end){
this.numbers = numbers;
this.start = start;
this.end = end;
}
//重写接口的方法
@Override
protected Long compute() {
//当前任务负责求和的部分的大小
int length = end - start;
//如果小于等于阀值就顺序执行计算结果
if(length <= THRESHOLD){
return computeSequentially();
}
//创建子任务来为数组的前一半求和
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2);
//将子任务拆分出去,丢到ForkJoinPool线程池异步执行。
leftTask.fork();
//创建子任务来为数组的后一半求和
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end);
//第二个任务直接使用当前线程计算而不再开启新的线程。
long rightResult = rightTask.compute();
//读取第一个子任务的结果,如果没有完成则等待。
long leftResult = leftTask.join();
//合并两个子任务的计算结果
return rightResult + leftResult;
}
//顺序执行计算的简单算法
private long computeSequentially(){
long sum = 0;
for(int i =start; i< end; i++){
sum += numbers[i];
}
return sum;
}
//提供给外部使用的入口方法
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
}
注意事项:
1. 调用join 方法要等到调用这个方法的线程的自己的任务完成之后。
2. 不要直接去调用ForkJoinPool的invoke方法 ,只需要调用RecursiveTask的fork或者compute。
3. 拆解任务时只需要调用一次fork执行其中一个子任务, 另一个子任务直接利用当前线程计算。应为fork方法只是在ForkJoinPool中计划一个任务。
4.任务拆分的粒度不宜太细,不否得不偿失。
工作盗取
由于各种因素,即便任务拆分是平均的,也不能保证所有子任务能同时执行结束, 大部分情况是某些子任务已经结束, 其他子任务还有很多, 在这个时候就会有很多资源空闲, 所以fork/join框架通过工作盗取机制来保证资源利用最大化, 让空闲的线程去偷取正在忙碌的线程的任务。
在没有任务线程中的任务存在一个队列当中, 线程每次会从头部获取一个任务执行,执行完了再从queue的头部获取一个任务,直到队列中的所有任务执行完,这个线程偷取别的线程队列中的任务时会从队列到尾部获取任务,并且执行,直到所有任务执行结束。
从这个角度分析,任务的粒度越小, 资源利用越充分。
工作盗取示意图
可拆分迭代器Spliterator
它和Iterator一样也是用于遍历数据源中的元素,但是他是为并行执行而设计的。 java8 所有数据结构都实现了 这个接口, 一般情况不需要自己写实现代码。但是了解它的实现方式会让你对并行流的工作原理有更深的了解。(未完待续)
作者:明翼(XGogo)
出处:http://www.cnblogs.com/seaspring/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
不能用于商业用户,若商业使用请联系:
-------------
QQ:107463366
微信:shinelife
-------------
将一个顺序执行的流转变成一个并发的流只要调用 parallel()方法
public static long parallelSum(long n){
return Stream.iterate(1L, i -> i +1).limit(n).parallel().reduce(0L,Long::sum);
}
并行流就是一个把内容分成多个数据块,并用不不同的线程分别处理每个数据块的流。最后合并每个数据块的计算结果。
将一个并发流转成顺序的流只要调用sequential()方法
stream.parallel() .filter(...) .sequential() .map(...) .parallel() .reduce();
这两个方法可以多次调用, 只有最后一个调用决定这个流是顺序的还是并发的。
并发流使用的默认线程数等于你机器的处理器核心数。
通过这个方法可以修改这个值,这是全局属性。
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
并非使用多线程并行流处理数据的性能一定高于单线程顺序流的性能,因为性能受到多种因素的影响。
如何高效使用并发流的一些建议:
1. 如果不确定, 就自己测试。
2. 尽量使用基本类型的流 IntStream, LongStream, and DoubleStream
3. 有些操作使用并发流的性能会比顺序流的性能更差,比如limit,findFirst , 依赖元素顺序的操作在并发流中是极其消耗性能的 。findAny的性能就会好很多,应为不依赖顺序。
4. 考虑流中计算的性能(Q)和操作的性能(N)的对比, Q表示单个处理所需的时间, N表示需要处理的数量,如果Q的值越大, 使用并发流的性能就会越高。
5. 数据量不大时使用并发流,性能得不到提升。
6.考虑数据结构:并发流需要对数据进行分解,不同的数据结构被分解的性能时不一样的。
流的数据源和可分解性
| 源 | 可分解性 |
| ArrayList | 非常好 |
| LinkedList | 差 |
| IntStream.range | 非常好 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
7. 流的特性以及中间操作对流的修改都会对数据对分解性能造成影响。 比如固定大小的流在任务分解的时候就可以平均分配,但是如果有filter操作,那么流就不能预先知道在这个操作后还会剩余多少元素。
8. 考虑最终操作的性能:如果最终操作在合并并发流的计算结果时的性能消耗太大,那么使用并发流提升的性能就会得不偿失。
9.需要理解并发流实现机制:
fork/join 框架
fork/join框架是jdk1.7引入的,java8的stream多线程并非流的正是以这个框架为基础的,所以想要深入理解并发流就要学习fork/join框架。
fork/join框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配线程池(ForkJoinPool)中的工作线程。要把任务提交到这个线程池,必须创建RecursiveTask<R>的一个子类,如果任务不返回结果则是RecursiveAction的子类。
fork/join框架流程示意图:
废话不多说,上代码:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
* Created by sunjin on 2016/7/5.
* 继承RecursiveTask来创建可以用于分支/合并的框架任务
*/
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
//要求和的数组
private final long[] numbers;
//子任务处理的数组开始和终止的位置
private final int start;
private final int end;
//不在将任务分解成子任务的阀值大小
public static final int THRESHOLD = 10000;
//用于创建组任务的构造函数
public ForkJoinSumCalculator(long[] numbers){
this(numbers, 0, numbers.length);
}
//用于递归创建子任务的构造函数
public ForkJoinSumCalculator(long[] numbers,int start,int end){
this.numbers = numbers;
this.start = start;
this.end = end;
}
//重写接口的方法
@Override
protected Long compute() {
//当前任务负责求和的部分的大小
int length = end - start;
//如果小于等于阀值就顺序执行计算结果
if(length <= THRESHOLD){
return computeSequentially();
}
//创建子任务来为数组的前一半求和
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2);
//将子任务拆分出去,丢到ForkJoinPool线程池异步执行。
leftTask.fork();
//创建子任务来为数组的后一半求和
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end);
//第二个任务直接使用当前线程计算而不再开启新的线程。
long rightResult = rightTask.compute();
//读取第一个子任务的结果,如果没有完成则等待。
long leftResult = leftTask.join();
//合并两个子任务的计算结果
return rightResult + leftResult;
}
//顺序执行计算的简单算法
private long computeSequentially(){
long sum = 0;
for(int i =start; i< end; i++){
sum += numbers[i];
}
return sum;
}
//提供给外部使用的入口方法
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
}
注意事项:
1. 调用join 方法要等到调用这个方法的线程的自己的任务完成之后。
2. 不要直接去调用ForkJoinPool的invoke方法 ,只需要调用RecursiveTask的fork或者compute。
3. 拆解任务时只需要调用一次fork执行其中一个子任务, 另一个子任务直接利用当前线程计算。应为fork方法只是在ForkJoinPool中计划一个任务。
4.任务拆分的粒度不宜太细,不否得不偿失。
工作盗取
由于各种因素,即便任务拆分是平均的,也不能保证所有子任务能同时执行结束, 大部分情况是某些子任务已经结束, 其他子任务还有很多, 在这个时候就会有很多资源空闲, 所以fork/join框架通过工作盗取机制来保证资源利用最大化, 让空闲的线程去偷取正在忙碌的线程的任务。
在没有任务线程中的任务存在一个队列当中, 线程每次会从头部获取一个任务执行,执行完了再从queue的头部获取一个任务,直到队列中的所有任务执行完,这个线程偷取别的线程队列中的任务时会从队列到尾部获取任务,并且执行,直到所有任务执行结束。
从这个角度分析,任务的粒度越小, 资源利用越充分。
工作盗取示意图
可拆分迭代器Spliterator
它和Iterator一样也是用于遍历数据源中的元素,但是他是为并行执行而设计的。 java8 所有数据结构都实现了 这个接口, 一般情况不需要自己写实现代码。但是了解它的实现方式会让你对并行流的工作原理有更深的了解。(未完待续)
作者:明翼(XGogo)
出处:http://www.cnblogs.com/seaspring/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
不能用于商业用户,若商业使用请联系:
-------------
QQ:107463366
微信:shinelife
-------------

相关文章推荐
- java8新特性(六):Stream多线程并行数据处理
- java8新特性(六):Stream多线程并行数据处理
- 详解Java8特性之Stream API并行流
- Java Stream API(五)-- 并行数据处理
- Java_基础—多线程的引入/并发和并行的区别
- java多线程之多线程的三大特性
- Stream:java1.8新特性
- JAVA8新特性--stream
- Java 多线程编程之一 进程与线程,并发和并行的区别
- java技术系列(三) 多线程之并行处理和同步
- Java8特性详解 lambda表达式 Stream
- Java8新特性-010-Stream规约-终止操作
- java多线程之并行和并发
- Java8 新特性之Stream----java.util.stream
- java高级特性之多线程 线程池
- Java8新特性学习-Stream的Reduce及Collect方法详解
- Java8新特性-011-Stream收集-终止操作
- Java多线程-新特性-有返回值的线程
- Java多线程-新特性-有返回值的线程
- java高级特性之多线程