DIY简易Python脚本调用AWVS扫描
2017-12-20 09:16
423 查看
前言
最近写了一个小系统,需要调用AWVS扫描工具的API接口实现扫描,在网上只搜到添加任务和生成报告的功能实现代码,无法添加扫描对象登录的用户名和密码,如果不登录系统扫描,扫描效果肯定会大打折扣。现在通过selenium实现,并实现扫描结果风险数量和类型的提取。代码分解
用到的库:selenium,requests,BeautifulSoup变量定义:包括awvs的用户名和密码、被测系统的用户名和密码等,具体如下,
awvs_username = ''
awvs_password = ''
app_username = ''
app_password = ''
app_url = '' # 被测系统域名
api_key = '1986ad8c0a5b3df4d7028d5f4c06e936cb0a9d0117d564f6d8d4801681ff3204c' # 由awvs生成,用于api操作的身份鉴定
awvs_url = "" # awvs的登录地址
headers = {"X-Auth": api_key, "content-type": "application/json"}添加扫描任务
首先登录通过selenium库定位元素的方法,实现登录awvs系统,登录后找到添加任务页面,添加被测目标的url和用户名密码,并获取到扫描目标target_id的值:dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0")
driver = webdriver.PhantomJS(executable_path='/etc/phantomjs', service_args=['--ignore-ssl-errors=true', '--ssl-protocol=any'], desired_capabilities=dcap)
driver.get(awvs_url)
print('[+] 登录awvs扫描系统')
driver.find_element_by_name('email').send_keys(awvs_username)
driver.find_element_by_name('password').send_keys(awvs_password)
driver.find_element_by_class_name('btn-dark').click()
driver.get(awvs_url + '/#/targets/')
driver.find_element(By.XPATH, '//div[@role="toolbar"]/button[2]').click()
driver.find_element_by_name('address').send_keys(app_url)
driver.find_element_by_class_name('btn-dark').click()
current_url = driver.current_url
target_id = current_url.split('/')[5]
driver.find_element(By.XPATH, '//input[@ng-change="siteLoginSection.onEnabledChanged()"]').click()
driver.find_element_by_name('username').send_keys(app_username)
driver.find_element_by_name('password').send_keys(app_password)
driver.find_element_by_name('retypePassword').send_keys(app_password)
driver.find_element(By.XPATH, '//button[@ng-disabled="!hasChanges()"]').click()
driver.quit()开启扫描任务
根据上一步获取的target_id,就可以开启扫描了,使用requests库提交一个post请求即可:data_start = {"target_id": target_id, "profile_id": "11111111-1111-1111-1111-111111111111",
"schedule": {"disable": False, "start_date": None, "time_sensitive": False}}
requests.post(awvs_url + "/api/v1/scans", data=json.dumps(data_start),
headers=headers, timeout=30, verify=False)获取scan_id
scan_id用于查看报告是否生成,下一步有用到:response = requests.get(awvs_url + "/api/v1/scans", headers=headers, timeout=30, verify=False)
results = json.loads(response.content.decode('utf-8'))
scan_id = ''
for result in results['scans']:
if result['target_id'] == target_id:
scan_id = result['scan_id']生成扫描报告并提取关键信息
while True:
time.sleep(30)
try:
response = requests.get(awvs_url + "/api/v1/scans/" + str(scan_id), headers=headers, timeout=30,
verify=False)
result = json.loads(response.content.decode('utf-8'))
status = result['current_session']['status']
except:
status = ''
# 如果是completed 表示结束.可以生成报告
if status == "completed":
data_report = {"template_id": "11111111-1111-1111-1111-111111111111",
"source": {"list_type": "scans", "id_list": [scan_id]}}
response = requests.post(awvs_url + "/api/v1/reports", data=json.dumps(data_report),
headers=headers, timeout=30, verify=False)
result = response.headers
report = result['Location'].replace('/api/v1/reports/', '/reports/download/')
report_url = awvs_url.rstrip('/') + report + '.html'
print(report_url)
html = requests.get(report_url, verify=False)
report_name = scan_id + '.html'
soup = BeautifulSoup(html.content, 'html.parser', from_encoding='utf8')
high_num = soup.find('td', class_='ax-alerts-distribution__label--high').find_next_sibling().text # 高风险数量
medium_num = soup.find('td', class_='ax-alerts-distribution__label--medium').find_next_sibling().text # 中风险数量
risk_list = []
risks_h3 = soup.find_all('h3', class_='ax-section-title ax-section-title--big')
for risk_h3 in risks_h3:
risk = risk_h3.get_text().strip(' \r\n')
risk_list.append(risk)
risks = '\n'.join(risk_list) # 得到风险列表类型在自己系统上的显示效果:
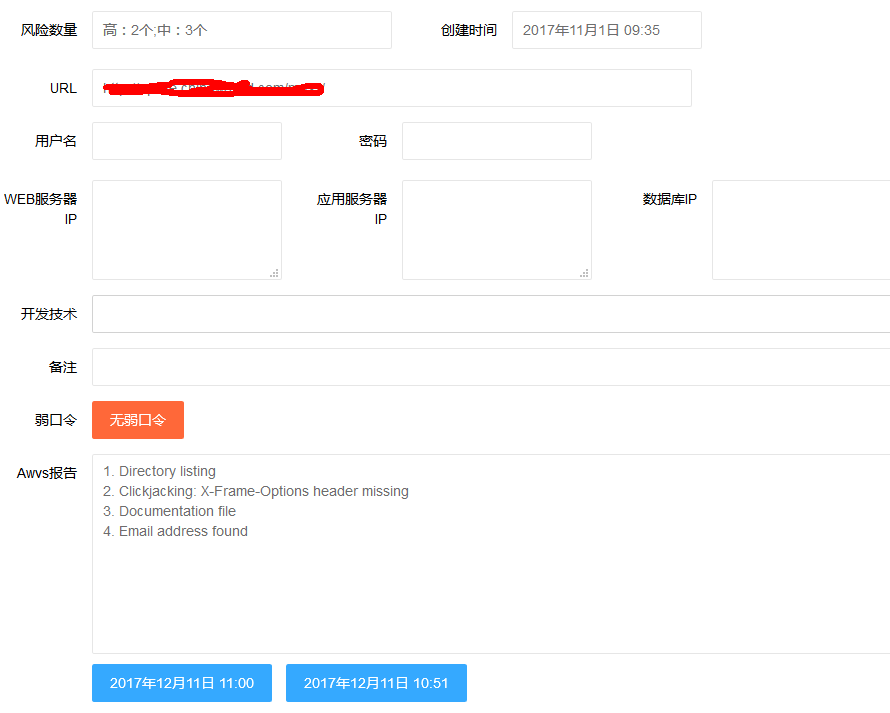
专栏

相关文章推荐
- DIY简易Python脚本调用AWVS扫描
- 自动旁注并多进程调用wwwscan扫描旁注结果的python脚本。
- 【转】C#中调用python脚本
- python调用Namp扫描端口状态
- shell脚本调用python模块
- Java程序中实现调用Python脚本的方法详解
- 【Python】如何在VBA中调用Python脚本
- Python编写简易脚本文件
- python调用Shell脚本:os.system(cmd)或os.popen(cmd)
- python调用Shell脚本:os.system(cmd)或os.popen(cmd)
- 在C#中调用python脚本,并使用python第三方arcpy模块
- nodejs调用脚本(python/shell)和系统命令
- 在java中调用python脚本
- c++中调用python脚本提示 error LNK2001: 无法解析的外部符号
- Labview调用Python脚本
- C++中调用Python脚本
- java调用python脚本方法
- java调用python脚本并向python脚本传递参数
- python调用shell脚本
- 使用Runtime.getRuntime().exec()在java中调用python脚本