python学习日记20171219
2017-12-19 17:10
190 查看
split()函数的用法
在机器学习实战中遇到的问题for line in array0Lines:
#去掉字符串头尾的空格,类似于Java的trim()
print (line)
line=line.strip()
#将整行元素按照tab分割成一个元素列表
listFromLine=line.split('\t')
分割前
40920 8.326976 0.953952 largeDoses
分割后
['40920', '8.326976', '0.953952', 'largeDoses']
实际上,txt文本中存储的都是str格式的数字和字符,需要通过字符操作,将str分开成程序可识别的英文和数字
np.where和matlab 中的find
>>a = np.array(a) >>a array([1, 2, 3, 1, 2, 3, 1, 2, 3]) >>idx = np.where(a > 2) >>idx (array([2, 5, 8], dtype=int32),) >>a[idx] # 这种做法并不推荐 array([3, 3, 3]) >>a[a>2] # 推荐的做法 array([3, 3, 3])
[code]ax.scatter用法[/code]ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
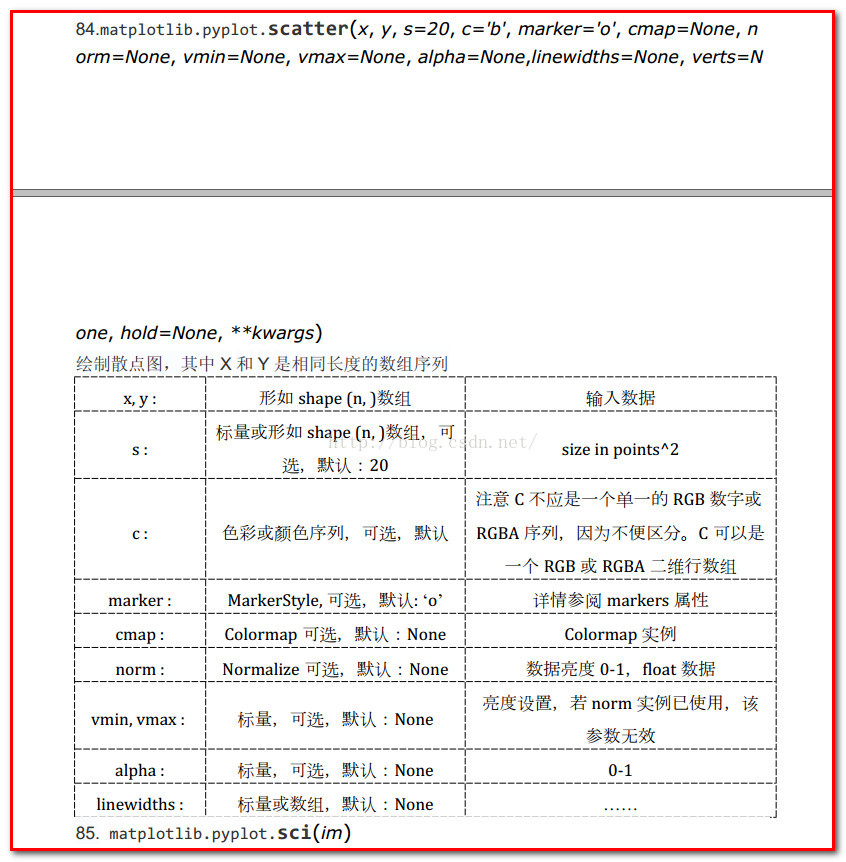
升级可视化:,其他博客有误!!!
datingLabels = array(datingLabels)
idx_1= where(datingLabels==1)
print (datingDataMat[idx_1,1])
p1 = ax.scatter(datingDataMat[idx_1,0],datingDataMat[idx_1,1],marker= '*',color = 'r',label='1',s=10)
idx2= where(datingLabels==2)
p2= ax.scatter(datingDataMat[idx2,0],datingDataMat[idx2,1],marker= 'o',color ='b',label='1',s=10)
idx3= where(datingLabels==3)
p3= ax.scatter(datingDataMat[idx3,0],datingDataMat[idx3,1],marker= '+',color ='g',label='1',s=30)
plt.legend(loc = 'upper right')
plt.show()

相关文章推荐
- python学习日记1--基础语法篇
- python学习日记_第四天(ex9~11)
- 萌新的Python学习日记 - 爬虫无影 - 添加headers抓取动态网页内容:TripAdvisor(上)
- python 学习日记(五)
- python学习日记-01
- 学习python 日记 -----(一)
- 【Python学习日记】 第四天
- python学习日记_第一天
- python学习日记
- Python 学习日记 2018-01-09
- python学习日记,易错知识点总结(1)
- 萌新的Python学习日记 - 爬虫无影 - 使用BeautifulSoup + css selector 抓取动态网页内容:Knewone
- Python 学习日记第三篇 -- 字典
- python学习日记_第五天(ex12~13)
- [学习日记](1)python中的.pyc
- Python学习日记之爬取美女写真图片
- python-学习日记-多线程
- python学习日记-D1
- Python学习日记
- Python 学习日记-01.中文编码声明# coding:UTF-8