Fast and Provably Good Seedings for k-Means阅读笔记
2017-12-18 12:05
591 查看
相关基础
K-Means及其改进
经典的K-Means是最常用的一种聚类算法。k-Means聚类算法可以对数据点或一些不知道标签但总类别数(比如总共有K个类别)比较明确的一些观测值进行聚类。其目的是使用一些相似性度量(比如欧式距离)来将数据聚集到K个类别。这种算法通常被称为Lloyd算法,该算法的核心包括需要找出每个类别的聚类中心,使得同一个类别中的数据点到聚类中心的距离最小。1. 基本原理
k-means(K-平均)是一种基于质心的聚类算法。其算法流程如图4-1所示: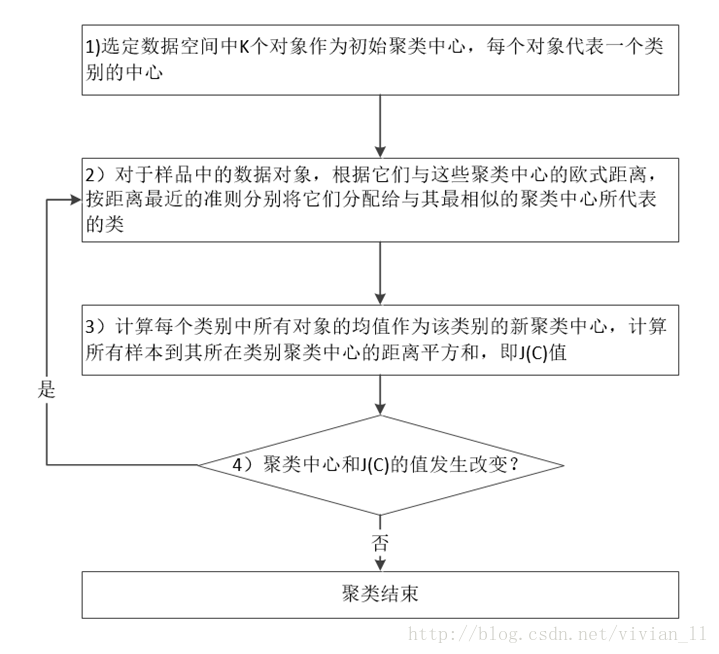
K-means聚类的目标是实现目标函数的最小化,实际应用中,对欧几里得空间中的数据,目标函数常使用误差平方和(Sum of the Squared Error,SSE)来表示。SSE定义如下:
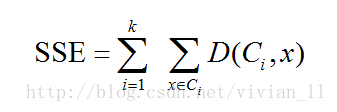
其中,D是两个样点在平直空间的欧几里得距离。误差平方和会随着迭代次数的增加而减小,最后趋于稳定。但误差平方和是一个非凸函数(non-convex function),只能发现局部最优解(locally optimal solution)而不能保证全局最优解(globally optimal solution)。因此实际应用的时候可以多运行数次K-均值算法,使用效果最好的一次。
值得一提的是关于聚类中心数目(K值)的选取,的确存在一种可行的方法,叫做Elbow method:通过绘制K-means代价函数与聚类数目K的关系图,选取直线拐点处的K值作为最佳的聚类中心数目。但在这边不做过多的介绍,因为上述方法中的拐点在实际情况中是很少出现的。比较提倡的做法还是从实际问题出发,人工指定比较合理的K值,通过多次随机初始化聚类中心选取比较满意的结果。
2. K-means++
K-means算法的先决条件是1)必须先行指定k的大小,及最终结果需要聚为几类。2)第一次分配数据点的时候需要选取起始质心(seeds),即初始化聚类中心点。标准的K-means算法是随机选择seeds的,这样可能会导致聚类结果和实际的数据分布差距较大。k-means++是一种基于采样方法(称为D^2-sampling)的中心点选择方法。其核心为:最开始的质心间两两的距离要尽可能远。该算法的实现过程为:先从输入的点中随机选一点作为第一个聚类中心;对于数据集中每点x,计算它与最近的中心点的距离D(x);选择一个新的中心点,原则是:某点被选为质心的概率与该点的D(x)成正相关;然后重复以上两步直到选出k个中心;最后利用这k个起始质心来运行标准的k-means算法。
其中选择聚类中心的原则是:D(x)较大的点,被选取作为聚类中心的概率较大。由上述过程可知,K-means++的关键是D(x)和点被选择的概率以怎样一种方式联系起来。一种方法是:随机选出第一个聚类中心点当“种子点”后,计算出每个点的D(x)并保存在一个数组里,并把这些距离加起来得到Sum(D(x))。再取一个能落在Sum(D(x))中的随机值Random,再令Random -= D(x),直到其<=0,选取此时该D(x)对应的点作为下一个“种子点”。最后重复以上两步直到选出k个聚类中心。
虽然K-means++算法改进了标准K-means算法随机选取初始质心的缺点,但其内在的有序性导致了它的可扩展型不足。由于选择下一个中心点所需的计算依赖于已经选择的所有中心点,这种内在的顺序执行特性使得到 k 个聚类中心必须遍历数据集 k 次,从而使得算法无法并行扩展而应用在超大规模数据集上。
附上原始文献:《k-means++: The Advantages of Careful Seeding》
3.基于MCMC采样的算法
很显然,上述方法在选择seeding的时候本来就是个计算量大的任务。为此有人提出基于MCMC的采样方法,k−MC2就是为了降低 *k-*means 算法的时间复杂度的改进算法。主要思想就是使用MCMC采样来近似 D2−sampling 这个过程。具体做法是:在选取候选种子节点时,随机选取一个seeding,然后用MCMC的方法采样出长为M的马尔科夫链,使得马尔科夫链的平稳分布为 p(x) ,从而马尔科夫链达到平稳状态后的那些状态就可以看作是以 p(x) 进行采样的样本点。取最后(K-1)个数作为中心点,target distribution是距离的函数,满足距离越远,概率越大(表达的含义同k-means++),proposal distribution是一个常函数,1/样本数。
k-MC^2 算法有一个缺点,即由于在MCMC过程中,算法使用的提案分布 q(x) 为均匀分布,这导致了潜在的缺点,就是那些样本数较小的聚类中可能不会被选中为候选节点。
关于时间复杂度的表述,见原始文献(AAAI):《Approximate K-Means++ in Sublinear Time》。这篇也是本论文作者同一批人写的。。。
4.AFK-MC2
因为上述的proposal distribution太过特别(均匀分布),上述的作者们换了这个proposal distribution,将与距离有关的分布作为一个term加入原始的分布中,据文章描述,这个提高了聚类的鲁棒性,也就是可以适应更多的数据分布假设,而非原来的一种均匀分布(严格地说是产生数据的分布)。这种方法的关键之处在于它使用马尔科夫链对k-Means++进行近似处理,也就是将数据点看做状态点。第一个状态是随机采样的数据点,通过一个随机过程来决定链的状态是否要转移到其他的随机数据点。状态是否转移与所有点的初始距离是相互独立的(马尔科夫链的稳定状态与初始状态无关),并且初始距离作为预处理的一部分只计算一次。与k-Means++不同的是,AFK-MC2算法只需要遍历一次数据集。
也就是下面要说的论文:《Fast and Provably Good Seedings for k-Means》
论文部分
论文摘要(翻译)
在为k-means获取高质量聚类(clustering)中,发现初始聚类中心的任务——seeding——是极其重要的。然而,当前最佳的算法k-means++的seeding 在大规模数据集上扩展不是很好,因为其内在是序列形式的,并且需要 k值在数据中的完全通过。近期的研究表明,马尔科夫链蒙特卡罗采样法(Markov chain Monte Carlo sampling)可被用来有效地近似 k-means++ 的 seeding 步骤。然而,这一结果需要在生成分布的数据上进行假设。我们提出了一种简单的、更快的 seeding 算法,即使在没有数据上的假设的情况下也能产生好的聚类。我们的分析表明该算法可在解决方案质量和计算成本之间良好地权衡,能将 k-means++ 的 seeding 速度提升几个数量级。我们在多个真实世界数据集上的大量实验中验证了该理论成果。引言
K-Means++是使用最广泛的选取聚类中心的方法具体的做法就是随机先选取一个初始中心点,然后计算各个数据点到这个中心点的距离,最后用距离做比值,随机抽取一个点,此时抽取的点,有很大概率离初始化的中心点较远,重复此步骤,然后按k-means来迭代,直至收敛。算法步骤如下:
1.任意选取一个数据点作为中心点c1;
2.以

的概率选取其余的中心点;
3.重复2直到选满k个中心点
4.其余步骤与标准k-means相同
这个方法称为

。这么做可以很大程度上避免初始选初始选中心点的问题。这种算法最大的问题是不容易扩展到大数据集,因为它的seeding步骤和Lloyd’s algorithm的每一步迭代都需要所有的成对距离。Lloyd’s算法可以在MapReduce框架中并行化,甚至被快速随机优化技术所取代,比如在线或者小批量K-means(online or mini-batch k-Means )。然而,seeding步骤却要求需要k从本质上连续地通过数据,这使得它甚至对于中k都是不切实际的。
这突出了对快速和可扩展seeding算法的需求。 Bachem等人提出了一种使用马尔可夫链蒙特卡罗(MCMC)方法近似k-means ++的快速的播种算法。
论文的贡献:
本文的目的是为k - means提供快速、有竞争力的seeding在数据没有先验假设时。作为我们的主要贡献,我们
(1)提出了一种简单快速的k - means算法,
(2)证明它在数据上没有假设的情况下产生了很好的聚类,
(3)在对数据生成分布的假设下提供更强的理论保证,
(4)将算法扩展到任意距离度量和各种散度度量,
(5)将算法与以往的结果进行比较,既有理论性的,也有经验的
(6)演示了它在几个真实的数据集上的有效性。
Background and related work
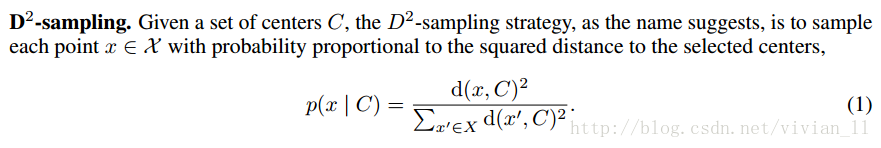


由此可见,计算复杂度从O(nkd)到O(mk^2d),这样就允许有更多的数据参与聚类,这在图像领域极为有用。
Assumption-free K-MC2
Bachem等人2016年提出的K-MC2有以下三个缺点:1.这种方法只在假设数据满足上节所述的分布时可用,比如不能用于现实中常被观测到的重尾分布(heavytailed distributions)。
2.验证这个假设在计算上非常困难。
3.Bachem等人(2016)的定理2并没有描述m和算法求解质量之间的tradeoff。
只有选择特定的链长度
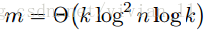
才有效。因此,如果假设不成立,我们就得不到理论上的保证。此外,定理2中的常数未知且可能很大。
我们的方法使用三个关键元素来解决这些缺点。首先,我们提出一个建议分布而废弃了在α(x)上的假设(α在论文上一节中定义)。第二,一种新的理论分析
允许我们在不假设β(x)的情况下获得解决方案质量的理论保证。
最后,我们的结果表明了增加的马氏链长度m和算法质量的提高之间的tradeoff。
算法步骤:

建议分布:

这个更换的提案分布是这篇论文的核心,可以满足更多数据分布假设下的鲁棒性。
算法:

实验结果
本节实证检验了我们的理论结果并将提出的无假设K-MC2(ASSUMPTION-FREE K-MC2即AFK-MC2)和三种选种策略相比较:1)随机选种,2)K-means++选种,3)K-MC2。在足够的条件下,AFK-MC2和k-Means++可以达到相同的稳定状态。结果表明,对于大数据集,在0到1%的相对误差下,AFK-MC2算法要比k-Means++快200到1000倍。
总结
In this paper, we propose ASSUMPTION-FREE K-MC2, a simple and fast seeding algorithm fork-Means. In contrast to the previously introduced algorithm K-MC2, it produces provably good
clusterings even without assumptions on the data. As a key advantage, ASSUMPTION-FREE K-MC2
allows to provably trade off solution quality for a decreased computational effort. Extensive experiments illustrate the practical significance of the proposed algorithm: It obtains competitive clusterings
at a fraction of the cost of k-means++ seeding and it outperforms or matches its main competitor
K-MC2 on all considered data sets.
目前Github上已经有基于Cython的AFK-MC2算法的实现,还有一些与scikit-learn配合使用的示例。
Thinking
这样修改给人的感觉就是给原来的算法加入了一些先验分布信息,从而在选择候选节点时更为准确。从而整个算法的鲁棒性更好。从原始文章中看到,proposal distribution中关于距离的term和样本数目的term前的weight是1/2,会不会有些新的想法出现?此外,能否找到其他的采样分布进一步降低时间复杂度的同时,具有较好的鲁棒性?
参考网址:
K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比
[读论文]fast-and-provably-good-seedings-for-k-means较为简洁明了地介绍了K-means,K-means++,MCMC近似的K-means++,本论文改进的K-mc^2算法
[paper]关于K-means变种的论文阅读这篇文章里也有很多参考文献和GitHub上代码的安装步骤
[TIL][心得] K-MC2: Approximate K-Means++ in Sublinear Time本文基础的那篇论文的心得
Fast and Provably Good Seedings for k-means

相关文章推荐
- Fast and Provably Good Seedings for k-means
- 《Fast and Accurate Inference with Adaptive Ensemble Prediction in Image Classification阅读笔记
- [分布式系统学习]阅读笔记 Distributed systems for fun and profit 抽象 之二
- Good Features to Correlate for Visual Tracking 阅读笔记
- [EMNLP2017]Global Normalization of Convolutional Neural Networks for Joint Entity and Relation(阅读笔记)
- Fast dynamic execution offloading for efficient mobile cloud computing阅读笔记
- 笔记-2012-Fast Online Training with Frequency-Adaptive Learning Rates for CWS and New
- T-Finder: A Recommender System for Finding Passengers and Vacant Taxis(阅读笔记)20171225
- 论文阅读笔记:R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation
- Query-Adaptive Late Fusion for Image Search and Person Re-identification阅读笔记
- Parallel Tracking and Mapping for Small AR Workspaces阅读笔记(PTAM)
- Rich featureHierarchies for accurate object detection and semantic segmentation 阅读笔记
- Deep Learning (Ian Goodfellow, Yoshua Bengio and Aaron Courville) 阅读笔记
- 【论文阅读笔记】Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net
- 阅读笔记(Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding)
- [分布式系统学习]阅读笔记 Distributed systems for fun and profit 之三 时间和顺序
- ThinkAir: Dynamic resource allocation and parallel execution in the cloud for mobile code offloading阅读笔记
- [分布式系统学习]阅读笔记 Distributed systems for fun and profit 之四 Replication 拷贝
- LSTM Recurrent Neural Networks for Short Text and Sentiment Classication文章阅读笔记
- [分布式系统学习]阅读笔记 Distributed systems for fun and profit 之一 基本概念