卷积网络为什么有效的直观原理解释
2017-12-13 21:21
183 查看
假设输入输出为两层网络如下图所示:

其中X有C~G 5个特征维度,Y有两个特征维度A、B, 且所有变量特征均为2值变量即{0,1}
假设: 当{C,D,F}或{C,D,E}这两个特征组合输入时分类为A,即输入X=[1,1,0,1,0] 或 [1,1,1,0,0] 时Y=[1,0]
当{E,F,G}或{D,F,G}这两个特征组合输入时分类为B, 即输入Y=[0,0,1,1,1] 或 [0,1,0,1,1] 时 Y=[0,1]
那么如何利用卷积网络来根据输入X得到对应的输出Y ? 我们是否只需要卷积和特征组合相同就可以得到输出Y了呢?
我们可以尝试这样做,

这里假设激活函数为
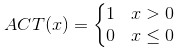
卷积公式为:

在X为不同输入时可以得到:

所以我们可以假设所有b都为-2,这时上面卷积结果加上b经过激活函数可以得到结果(4个数据行)R:

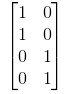
说明可以有效区分标签A和B,但是我们现在得到的是4维的列数据,所以我们还需要两个卷积核才能将结果对应为2维的,同上我们仍然可以定义卷积核:

对R作卷积

这里设置b为0,这个时候可以得到4个数据行2维列数据(正和我们对应的标签一样)
所以我们可以发现卷积有一个特点,就是卷积相当与对数据的一次观测,如果数据包含与卷积相同或者相似的模式,卷积就能将该模式提取出来[1],并且我们可以通过修改卷积的偏置来达到我们理想的模式匹配,但是有人就说了,你只是完美拟合了上面四个数据,那么我们可以看一下在随机数据上的表现:

结果具有较强的稳健性,源代码如下:
可以设想,如果我们按从下到上的模式特征去组合,比如A可以由{C,D,E}表示,而C,D,E再按照同样的方式由其他变量表示,从下到上不断的增加层数组合输入,最后我们要分类识别的输入将变得异常复杂和高维,是基本不可能用一般的分类器来分的,而深度卷积网络正是因为通过分层特征观测不断的组合特征,才能适应于非常高维和高组合的数据。
卷积更像是对数据的观测,即每次卷积运算都是卷积核对数据的一次观测,每次观测都是在确认是否观测的数据和卷积核是相似或相同的。卷积也让人产生这样的思考,这里有点认知学的意味,就是你看到的世界并不是真实的世界,你看到的世界是你用自己拥有的观测尺度对世界的测量。你看到了某个事物仅仅是因为你有这个事物的观测尺度。
参考文献:
1. Understanding Convolutional Neural Networks with A Mathematical Model
其中X有C~G 5个特征维度,Y有两个特征维度A、B, 且所有变量特征均为2值变量即{0,1}
假设: 当{C,D,F}或{C,D,E}这两个特征组合输入时分类为A,即输入X=[1,1,0,1,0] 或 [1,1,1,0,0] 时Y=[1,0]
当{E,F,G}或{D,F,G}这两个特征组合输入时分类为B, 即输入Y=[0,0,1,1,1] 或 [0,1,0,1,1] 时 Y=[0,1]
那么如何利用卷积网络来根据输入X得到对应的输出Y ? 我们是否只需要卷积和特征组合相同就可以得到输出Y了呢?
我们可以尝试这样做,
这里假设激活函数为
卷积公式为:
在X为不同输入时可以得到:
所以我们可以假设所有b都为-2,这时上面卷积结果加上b经过激活函数可以得到结果(4个数据行)R:
说明可以有效区分标签A和B,但是我们现在得到的是4维的列数据,所以我们还需要两个卷积核才能将结果对应为2维的,同上我们仍然可以定义卷积核:
对R作卷积
这里设置b为0,这个时候可以得到4个数据行2维列数据(正和我们对应的标签一样)
所以我们可以发现卷积有一个特点,就是卷积相当与对数据的一次观测,如果数据包含与卷积相同或者相似的模式,卷积就能将该模式提取出来[1],并且我们可以通过修改卷积的偏置来达到我们理想的模式匹配,但是有人就说了,你只是完美拟合了上面四个数据,那么我们可以看一下在随机数据上的表现:
结果具有较强的稳健性,源代码如下:
import numpy as np X=np.random.rand(20,5) X=np.round(X) C=[[1,1,0,1,0], [1,1,1,0,0], [0,0,1,1,1], [0,1,0,1,1]] C=np.array(C) R=np.dot(X,C.T)-2 R=R>0 R=R.astype(np.int) C2=[[1,1,0,0], [0,0,1,1]] C2=np.array(C2) R2=np.dot(R,C2.T)+0 R2=R2>0 R2=R2.astype(np.int) print X print R2
可以设想,如果我们按从下到上的模式特征去组合,比如A可以由{C,D,E}表示,而C,D,E再按照同样的方式由其他变量表示,从下到上不断的增加层数组合输入,最后我们要分类识别的输入将变得异常复杂和高维,是基本不可能用一般的分类器来分的,而深度卷积网络正是因为通过分层特征观测不断的组合特征,才能适应于非常高维和高组合的数据。
卷积更像是对数据的观测,即每次卷积运算都是卷积核对数据的一次观测,每次观测都是在确认是否观测的数据和卷积核是相似或相同的。卷积也让人产生这样的思考,这里有点认知学的意味,就是你看到的世界并不是真实的世界,你看到的世界是你用自己拥有的观测尺度对世界的测量。你看到了某个事物仅仅是因为你有这个事物的观测尺度。
参考文献:
1. Understanding Convolutional Neural Networks with A Mathematical Model

相关文章推荐
- 用量子物理学原理解释为什么振金可以吸收能量(论发散思维的重要性)
- 通俗直观地解释为什么svm支持向量机可以假设离判决面最近的点在wx+b=±1上
- (转)区块链原理最清晰最直观的解释
- Linux driver - PCI的原理解释,为什么说PCI是auto-config的设备
- Session原理解释,为什么使用session
- Session原理解释,为什么使用session
- 0909编译原理理解和解释
- JAVA Hibernate工作原理及为什么要用
- 为什么要用UML建模之建模原理
- 一劳永逸:关于C/C++中指针、数组与函数复合定义形式的直观解释
- 如何向外行解释产品经理频繁更改需求为什么会令程序员烦恼?
- 如何安装EFI分区引导(很好的解释了OSX破解原理)
- onvif 开发框架生成,解决在线/本地生成https,ssl/tsl错误,以及原理解释
- Google工程师解释Googlebot抓取网页的原理
- 数字图像处理—图像高斯模糊运算直观解释
- 解释“易语言.飞扬”为什么不支持“OCX开发,DLL开发,COM调用,独立编译”
- 数据归一化(normalizing)的直观理解和通俗解释。
- 一张图解释NIO原理
- Gini coefficient直观的解释与实现
- android的原理,为什么我们不需要太多的剩余内存(转)