神经网络优化算法之不一样的梯度下降
2017-12-13 18:01
155 查看
在上一篇文章中,我们介绍了正则化的作用以及方法,有效的应对“过拟合”问题。今天我们又将提出另一优化算法——Mini-batch。
1. 什么是Mini-batch
前面我们提到,为了加快训练速度我们常采用向量化的手段来一次性训练所有的训练集,但是当训练集非常大时,这一过程是缓慢的。因此提出了Mini-batch的概念——将整个训练集划分成若干个小的训练集来依次训练。我们常用mini_batch_size来表示每个子训练集的大小,当mini_batch_size=m(m为整个训练集的大小)时,mini-batch梯度下降就是我们之前的batch梯度下降; 当mini_batch_size=1时,也就是每次只训练一个样本,我们称之为“随机梯度下降”。随机梯度下降和batch梯度下降是mini-batch梯度下降的两个极端:batch梯度下降训练过程缓慢,而随机梯度下降没有发挥向量化的优势。因此,在实际应用中我们常取这两者的中间值(一般为2^i的形式,如64、128、256、512)。
2. 如何实现Mini-batch
一般Mini-batch包含两个步骤:
数据洗牌:随机调整每个样本的位置,这一步骤确保将训练集分成不同的小批次。
划分:根据设置的mini_batch_size将训练集划分成若干个小批次
下面给出python代码:
# GRADED FUNCTION: random_mini_batches
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)
mini_batch_size -- size of the mini-batches, integer
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
np.random.seed(seed) # To make your "random" minibatches the same as ours
m = X.shape[1] # number of training examples
mini_batches = []
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation] #这个部分需要注意学习一下
shuffled_Y = Y[:, permutation].reshape((1,m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = int(math.floor(m/mini_batch_size)) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, k * mini_batch_size : (k+1) * mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size : (k+1) * mini_batch_size]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, mini_batch_size * num_complete_minibatches : m]
mini_batch_Y = shuffled_Y[:, mini_batch_size * num_complete_minibatches : m]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
3. Mini-batch带来的问题及解决办法
由于mini-batch梯度下降只看到一个子集的例子就进行参数更新,因此更新的方向有一定的变化,所以mini-batch梯度下降将会“振荡”收敛,如下图所示。
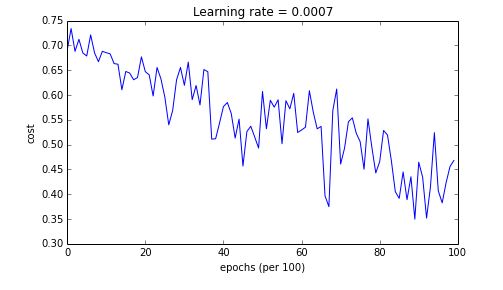
下面将介绍可以减少这些振荡的三种方法:Momentum、RMSprop、Adam。
3.1 Momentum
Momentum采用以下公式进行参数更新:
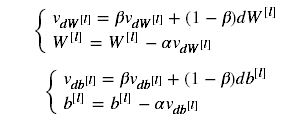
与之前不同的是引入了“指数加权平均”的概念。Momentum考虑了参数过去的渐变情况来进行平滑更新:首先把以前渐变的“方向”存储在变量v(形式上,v将是前面步骤中梯度的指数加权平均值)中,然后与当前参数变化方向加权平均。
3.2 RMSprop
RMSprop(Root Mean Square prop)的原理类似,其表现形式如下:
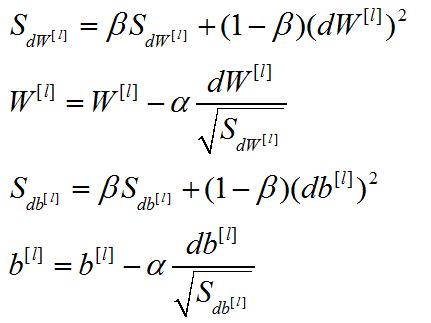
3.3 Adam
Adam将Momentum和RMSprop结合起来,其表现形式为:
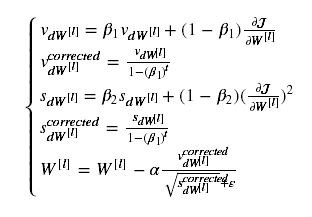
这里,还对指数加权平均进行了偏差修正。添加的ε也是为了避免分母太小引起的数值不稳定问题,一般取值10^-8。
4. 小结
对于解决梯度下降“振荡”收敛问题,Momentum通常是有效的。但对于有些mini-batch,依然很难优化。而Adam 可以更好的解决振荡收敛。对于简单数据集而言,进行多次迭代训练,这三种方法都会带来非常好的结果。其中Adam收敛地更快。
1. 什么是Mini-batch
前面我们提到,为了加快训练速度我们常采用向量化的手段来一次性训练所有的训练集,但是当训练集非常大时,这一过程是缓慢的。因此提出了Mini-batch的概念——将整个训练集划分成若干个小的训练集来依次训练。我们常用mini_batch_size来表示每个子训练集的大小,当mini_batch_size=m(m为整个训练集的大小)时,mini-batch梯度下降就是我们之前的batch梯度下降; 当mini_batch_size=1时,也就是每次只训练一个样本,我们称之为“随机梯度下降”。随机梯度下降和batch梯度下降是mini-batch梯度下降的两个极端:batch梯度下降训练过程缓慢,而随机梯度下降没有发挥向量化的优势。因此,在实际应用中我们常取这两者的中间值(一般为2^i的形式,如64、128、256、512)。
2. 如何实现Mini-batch
一般Mini-batch包含两个步骤:
数据洗牌:随机调整每个样本的位置,这一步骤确保将训练集分成不同的小批次。
划分:根据设置的mini_batch_size将训练集划分成若干个小批次
下面给出python代码:
# GRADED FUNCTION: random_mini_batches
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)
mini_batch_size -- size of the mini-batches, integer
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
np.random.seed(seed) # To make your "random" minibatches the same as ours
m = X.shape[1] # number of training examples
mini_batches = []
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation] #这个部分需要注意学习一下
shuffled_Y = Y[:, permutation].reshape((1,m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = int(math.floor(m/mini_batch_size)) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, k * mini_batch_size : (k+1) * mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size : (k+1) * mini_batch_size]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, mini_batch_size * num_complete_minibatches : m]
mini_batch_Y = shuffled_Y[:, mini_batch_size * num_complete_minibatches : m]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
3. Mini-batch带来的问题及解决办法
由于mini-batch梯度下降只看到一个子集的例子就进行参数更新,因此更新的方向有一定的变化,所以mini-batch梯度下降将会“振荡”收敛,如下图所示。
下面将介绍可以减少这些振荡的三种方法:Momentum、RMSprop、Adam。
3.1 Momentum
Momentum采用以下公式进行参数更新:
与之前不同的是引入了“指数加权平均”的概念。Momentum考虑了参数过去的渐变情况来进行平滑更新:首先把以前渐变的“方向”存储在变量v(形式上,v将是前面步骤中梯度的指数加权平均值)中,然后与当前参数变化方向加权平均。
3.2 RMSprop
RMSprop(Root Mean Square prop)的原理类似,其表现形式如下:
3.3 Adam
Adam将Momentum和RMSprop结合起来,其表现形式为:
这里,还对指数加权平均进行了偏差修正。添加的ε也是为了避免分母太小引起的数值不稳定问题,一般取值10^-8。
4. 小结
对于解决梯度下降“振荡”收敛问题,Momentum通常是有效的。但对于有些mini-batch,依然很难优化。而Adam 可以更好的解决振荡收敛。对于简单数据集而言,进行多次迭代训练,这三种方法都会带来非常好的结果。其中Adam收敛地更快。

相关文章推荐
- 机器学习(11.2)--神经网络(nn)算法的深入与优化(2) -- QuadraticCost、CorssEntropyCost、SoftMax的javascript数据演示测试代码
- 神经网络优化算法选择
- 【深度学习_2.2】神经网络之算法优化
- 神经网络 优化算法 名词
- 神经网络(优化算法)
- 神经网络优化算法
- CNN:人工智能之神经网络算法进阶优化,六种不同优化算法实现手写数字识别逐步提高,应用案例自动驾驶之捕捉并识别周围车牌号—Jason niu
- 吴恩达神经网络和深度学习课程自学笔记(六)之优化算法
- 第2次课改善深层神经网络:超参数优化、正则化以及优化 - week2 优化算法
- 机器学习(11.3)--神经网络(nn)算法的深入与优化(3) -- QuadraticCost(二次方代价函数)数理分析
- 遗传算法优化神经网络小车自动寻路走出迷宫(2) 神经网络与遗传算法应用
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
- Tensorflow基础:神经网络优化算法
- 神经网络的优化算法选择
- 机器学习(11.4)--神经网络(nn)算法的深入与优化(4) -- CorssEntropyCost(交叉熵代价函数)数理分析与代码实现
- 2.改善深层神经网络-第二周 优化算法
- 深度学习笔记6:神经网络优化算法之从SGD到Adam
- 利用遗传算法优化神经网络:Uber提出深度学习训练新方式
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
- 各种神经网络优化算法:从梯度下降到Adam方法