神经网络优化算法
2017-09-05 14:56
309 查看
提高神经网络训练速率的方式:
1. 采用Mini-batch的方式,不要等到把所有的数据都遍历一遍才更新权重,采用batch的方式的缺点是收敛过程会有震荡的现象的出现,这样有时候就不得不采用比较小的learning rate来使结果收敛到比较好的结果
为了消除Mini-batch的震荡现象,可以采用以下
2. 动量梯度下降法:合成之前的方向

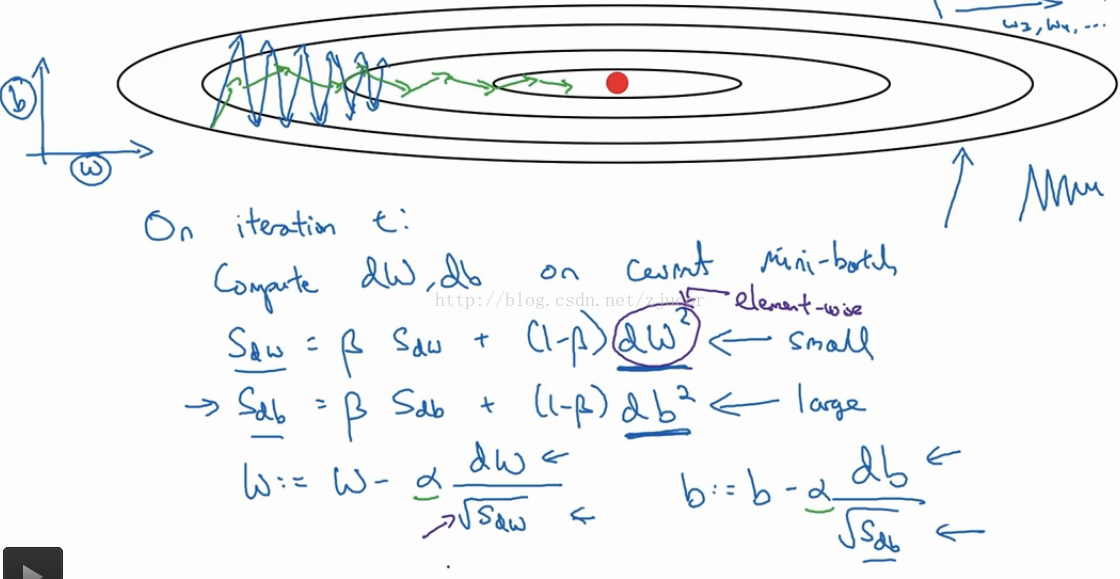
3. RMSprop:在梯度变化大的地方降低更新数据的速度,在梯度变化小的地方增加梯度变化的速度,以上图为例:在水平方向上梯度较小,因此采用比较大的更新权重
4. Adam优化算法:Adam = 动量下降 + RMSprop

2,3,4都是对Mini-batch有震荡的优化算法,一方面可以消除震荡更快的收敛,另一方面因为震荡小了可以采用更大的learning rate,也可以加速算法
5. learning rate decay:随着算法的运算缓慢减小learning rate,一方面震动幅度减小了,一定程度上可以加速收敛,另外一方面可以收敛到更接近optimal的值
6. 其实在比较深的神经网络中local optimal并不是问题,因为变量的维度高,同时在某一点都是最低点的概率很低,通常都是写saddle point(鞍点)
在deep learning里面真正的问题是plateaus(梯度长时间为0)
1. 采用Mini-batch的方式,不要等到把所有的数据都遍历一遍才更新权重,采用batch的方式的缺点是收敛过程会有震荡的现象的出现,这样有时候就不得不采用比较小的learning rate来使结果收敛到比较好的结果
为了消除Mini-batch的震荡现象,可以采用以下
2. 动量梯度下降法:合成之前的方向
3. RMSprop:在梯度变化大的地方降低更新数据的速度,在梯度变化小的地方增加梯度变化的速度,以上图为例:在水平方向上梯度较小,因此采用比较大的更新权重
4. Adam优化算法:Adam = 动量下降 + RMSprop
2,3,4都是对Mini-batch有震荡的优化算法,一方面可以消除震荡更快的收敛,另一方面因为震荡小了可以采用更大的learning rate,也可以加速算法
5. learning rate decay:随着算法的运算缓慢减小learning rate,一方面震动幅度减小了,一定程度上可以加速收敛,另外一方面可以收敛到更接近optimal的值
6. 其实在比较深的神经网络中local optimal并不是问题,因为变量的维度高,同时在某一点都是最低点的概率很低,通常都是写saddle point(鞍点)
在deep learning里面真正的问题是plateaus(梯度长时间为0)

相关文章推荐
- 神经网络优化算法详解(TensorFlow)
- Coursera | Andrew Ng (02-week2)—改善深层神经网络:优化算法
- 08. 训练神经网络3 -- 优化算法
- 神经网络梯度下降优化算法及初始化方法小结
- 机器学习(11.5)--神经网络(nn)算法的深入与优化(5) -- softmax的代码实现
- 神经网络的优化算法选择
- 基于遗传算法优化的神经网络算法
- 深度学习笔记6:神经网络优化算法之从SGD到Adam
- 深度学习与神经网络-吴恩达-第二周优化算法
- 利用遗传算法优化神经网络:Uber提出深度学习训练新方式
- 神经网络 优化算法 名词
- 遗传算法优化神经网络小车自动寻路走出迷宫(2) 神经网络与遗传算法应用
- 2.改善深层神经网络-第二周 优化算法
- 一文看懂各种神经网络优化算法:从梯度下降到Adam方法
- 机器学习(11.1)--神经网络(nn)算法的深入与优化(1)--介绍
- NN:神经网络算法进阶优化法,进一步提高手写数字识别的准确率—Jason niu
- DAY7: 神经网络及深度学习基础--算法的优化(deeplearning.ai)
- 【深度学习_2.2】神经网络之算法优化
- 神经网络(优化算法)
- 第2次课改善深层神经网络:超参数优化、正则化以及优化 - week2 优化算法