RabbitMQ学习心得——工作队列
2017-12-13 16:27
459 查看
上一篇教程介绍了RabbitMQ的第一种工作方式:Hello World。今天介绍它的第二种工作方式:工作队列。
生产者会发布一些耗时的任务到工作队列(Work Queue),让多个工作者(Worker)去执行。

工作队列(又称:任务队列——Task Queues)是为了避免等待一些占用大量资源、时间的操作。当我们把任务(Task)当作消息发送到队列中,一个运行在后台的工作者(worker)进程就会取出任务然后处理。当你运行多个工作者(workers),任务就会在它们之间共享。
在本地启动rabbit-server
为了更好的表现耗时复杂的任务,我们用time.sleep()函数来模拟这种情况。我们在字符串中加上点号(.)来表示任务的复杂程度,一个点(.)将会耗时1秒钟。比如"Hello..."就会耗时3秒钟。
new_task.py(用来发布任务)
worker.py(用来执行任务)
运行
打开三个终端,一个用来运行new_task.py(发布任务),另两个用来运行worker.py(用来执行任务)。
首先打开两个终端运行worker.py,等待执行任务。

再打开一个终端用来运行new_task.py,发布任务。(运行时要加参数)
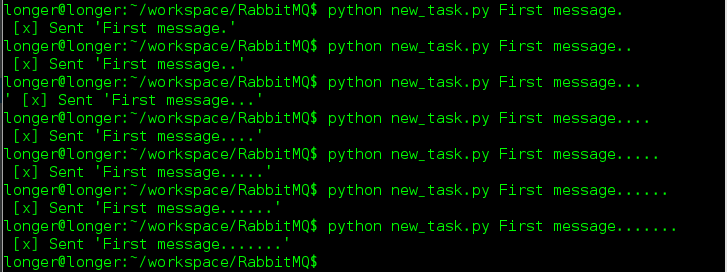
我们发布了7条复杂度不一样的任务,看一下任务的执行情况:
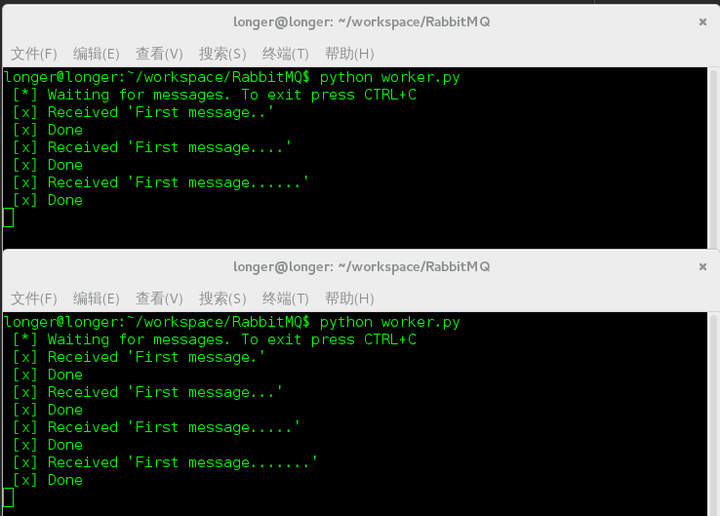
可以看到任务被执行。默认来说,RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin)。试着添加三个或更多得工作者(workers)。
疑难解惑
在上一篇教程中我们弱化了对“no_ack参数”的讲解。在Hello World工作方式中我们的代码如下:
这个参数代表消息响应,消息响应默认是开启的(no_ack=False)。在Hello World工作方式中我们把它关闭了。在关闭的状态下,消息被RabbitMQ发送给消费者(consumers)之后,马上就会在内存中移除。这对于前面的例子没什么影响。但对于工作队列来说,意义非同凡响。设想当RabbitMQ把一个任务分配给一个Worker去执行,而这个Worker在执行一半时挂掉了,任务未完成。而此时RabbitMQ已经把任务从内存中移除了。这是多么的操蛋呀。
而消息响应开启后,消费者会通过一个ack响应
告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,即使工作者(workers)偶尔的挂掉,也不会丢失消息。(可以验证一下,运行两个worker.py,在一个worker.py收到耗时较长的消息后立马关闭它,会发现RabbitMQ会把这个任务重新分发给另一个worker。)
关于声明队列,参数的问题,在RabbitMQ简介(下)中有介绍。Durable这个参数代表把队列声明为持久化。这时候,我们就可以确保在RabbitMq重启之后queue_declare队列不会丢失。另外,我们需要把我们的消息也要设为持久化——将delivery_mode的属性设为2。如下所示:
当我们注释掉这段代码后,会发现两个工作者(workers),处理奇数消息的比较繁忙,处理偶数消息的比较轻松。没有实现公平调度。我们可以使用basic.qos方法,并设置prefetch_count=1。这样是告诉RabbitMQ,在同一时刻,不要发送超过1条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。
一、实现目标
生产者会发布一些耗时的任务到工作队列(Work Queue),让多个工作者(Worker)去执行。
二、架构描述
工作队列(又称:任务队列——Task Queues)是为了避免等待一些占用大量资源、时间的操作。当我们把任务(Task)当作消息发送到队列中,一个运行在后台的工作者(worker)进程就会取出任务然后处理。当你运行多个工作者(workers),任务就会在它们之间共享。
三、准备
在本地启动rabbit-server为了更好的表现耗时复杂的任务,我们用time.sleep()函数来模拟这种情况。我们在字符串中加上点号(.)来表示任务的复杂程度,一个点(.)将会耗时1秒钟。比如"Hello..."就会耗时3秒钟。
四、代码实现
new_task.py(用来发布任务)# coding=utf-8 import pika import sys # 连接服务器 connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明队列 channel.queue_declare(queue='task_queue', durable=True) # 模拟任务的复杂度 message = ' '.join(sys.argv[1:]) or "Hello World!" channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2, # make message persistent )) print " [x] Sent %r" % (message,) connection.close()
worker.py(用来执行任务)
# coding=utf-8
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
# 沉睡几秒,模拟任务
time.sleep(body.count('.'))
print " [x] Done"
# 给予消息的响应
ch.basic_ack(delivery_tag=method.delivery_tag)
# 收到消息后,在没做出响应之前,不要再给我发消息,即ack
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()运行
打开三个终端,一个用来运行new_task.py(发布任务),另两个用来运行worker.py(用来执行任务)。
首先打开两个终端运行worker.py,等待执行任务。
再打开一个终端用来运行new_task.py,发布任务。(运行时要加参数)
我们发布了7条复杂度不一样的任务,看一下任务的执行情况:
可以看到任务被执行。默认来说,RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin)。试着添加三个或更多得工作者(workers)。
疑难解惑
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
# 沉睡几秒,模拟任务
time.sleep(body.count('.'))
print " [x] Done"
# 给予消息的响应
ch.basic_ack(delivery_tag=method.delivery_tag)
# 收到消息后,在没做出响应之前,不要再给我发消息,即ack
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')在上一篇教程中我们弱化了对“no_ack参数”的讲解。在Hello World工作方式中我们的代码如下:
channel.basic_consume(callback, queue='hello', no_ack=True)
这个参数代表消息响应,消息响应默认是开启的(no_ack=False)。在Hello World工作方式中我们把它关闭了。在关闭的状态下,消息被RabbitMQ发送给消费者(consumers)之后,马上就会在内存中移除。这对于前面的例子没什么影响。但对于工作队列来说,意义非同凡响。设想当RabbitMQ把一个任务分配给一个Worker去执行,而这个Worker在执行一半时挂掉了,任务未完成。而此时RabbitMQ已经把任务从内存中移除了。这是多么的操蛋呀。
而消息响应开启后,消费者会通过一个ack响应
ch.basic_ack(delivery_tag=method.delivery_tag)
告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,即使工作者(workers)偶尔的挂掉,也不会丢失消息。(可以验证一下,运行两个worker.py,在一个worker.py收到耗时较长的消息后立马关闭它,会发现RabbitMQ会把这个任务重新分发给另一个worker。)
# 声明队列 channel.queue_declare(queue='task_queue', durable=True)
关于声明队列,参数的问题,在RabbitMQ简介(下)中有介绍。Durable这个参数代表把队列声明为持久化。这时候,我们就可以确保在RabbitMq重启之后queue_declare队列不会丢失。另外,我们需要把我们的消息也要设为持久化——将delivery_mode的属性设为2。如下所示:
channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2, # make message persistent ))
# 公平调度 channel.basic_qos(prefetch_count=1)
当我们注释掉这段代码后,会发现两个工作者(workers),处理奇数消息的比较繁忙,处理偶数消息的比较轻松。没有实现公平调度。我们可以使用basic.qos方法,并设置prefetch_count=1。这样是告诉RabbitMQ,在同一时刻,不要发送超过1条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。

相关文章推荐
- [RabbitMQ]03_RabbitMQ学习之工作队列(java)
- rabbitMQ消息服务器学习笔记(java)2 工作队列
- RabbitMQ学习之工作队列(java)
- RabbitMQ学习小结(二)----工作队列
- (转) RabbitMQ学习之工作队列(java)
- Rabbitmq学习笔记三:工作队列work queue
- RabbitMQ (消息队列)专题学习03 Work Queues(工作队列)
- RabbitMQ学习总结 第三篇:工作队列Work Queue
- RabbitMQ入门(2)--工作队列
- RabbitMQ之工作队列
- RabbitMQ五种消息队列学习(三)--Work模式
- Linux Kernel 学习笔记14:工作队列
- RabbitMQ (二)工作队列
- RabbitMQ学习之:(一)初识、概念及心得
- RabbitMQ 一二事(2) - 工作队列使用
- RabbitMQ工作队列示例
- RabbitMQ教程之php-amqplib(三)工作队列
- RabbitMQ (二)工作队列
- RabbitMQ (消息队列)专题学习04 Publish/Subscribe(发布者/订阅者)
- RabbitMQ学习心得——RabbitMQ简介(下)