分批次插入mysql:一次性插入mysql两万以上数据造成数据库假死
2017-12-12 17:42
357 查看
项目距离上线的日期越来越近了,需要规范一下数据库中的数据,就需要从前端页面上导入系统数据到mysql数据库。导入3万数据,期间会有校验,最后分别插入到四张表中,本库插入3张表,云平台插入一张表,运行到一半的时候就前端页面假死了,最后通过分批插入数据解决问题,以下是实验并解决的过程。
前端:Angular
后端:SSM+Dubbo+Mysql数据库
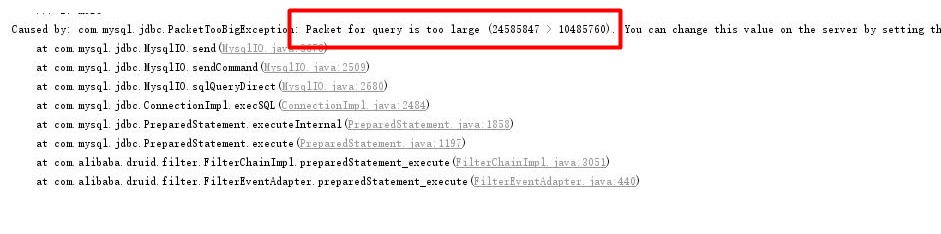
使用命令连接mysql,使用命令查看mysql的配置:show VARIABLES like '%max_allowed_packet%';发现太小,然后设置的大一点,设置为20M,set global max_allowed_packet = 2*1024*1024*10
将学号重复的校验去掉,其中会为每条数据设置UUID(业务需要),测试数据量是3W,结果是可以入库,数据量大小是4.8min左右.
1.实验条件
笔记本型号:戴尔,I3处理器,12G内存条2.项目框架
本项目为前后端分离。前端:Angular
后端:SSM+Dubbo+Mysql数据库
3.实验过程
插入数据库的是批量的插入,最后的sql语句类似于insert into t_test (cloumn_a,cloumn_b) values(1,2),(3,4),(5,6).①一次性批量插入数据库(四张表)
结果:dubbo超时,由于中间需要有其他的操作,例如,学号重复的校验,身份证号的校验等,导致还没有到插入数据库的一步就已经dubbo超时了,我们设置的dubbo超时时间是3s.②一次性批量插入数据库(单表插入)
我们将dubbo超时时间设置到保证不会超时,如10min,mysql报错,意思为传输的数据包太大了,超过了数据库配置的可接收的最大值.使用命令连接mysql,使用命令查看mysql的配置:show VARIABLES like '%max_allowed_packet%';发现太小,然后设置的大一点,设置为20M,set global max_allowed_packet = 2*1024*1024*10
将学号重复的校验去掉,其中会为每条数据设置UUID(业务需要),测试数据量是3W,结果是可以入库,数据量大小是4.8min左右.
③公共方法tool中分批次1000一批次(单表插入)
我们将dubbo超时时间设置到保证不会超时,如10min,将学号重复的校验去掉,其中会为每条数据设置UUID(业务需要),测试数据量是3W,结果是可以入库,数据量大小是4min左右.④除去入库和和学号校验,基础代码循环设置uuid
结果:1min⑤除去学号校验,入库4张表,基础代码循环设置uuid
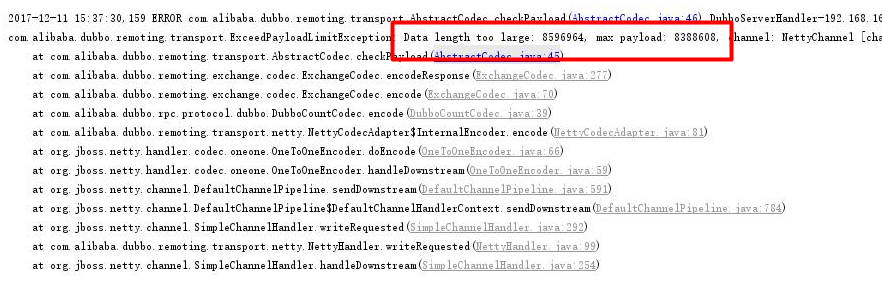
dubbo报错,dubbo不支持这么大的数据包4.解决方法
在自己业务处理的代码中同样分批处理,分批处理的代码如下:private static int batchCount=500; //500条数据一批次
@Override
@Transactional(rollbackFor = Exception.class)
public int insertAll(List<T> records) {
int result = 0;
if (records != null) {
int recCount = records.size();
if (recCount > 0 && recCount <= batchCount) {
for (T record : records) {
wrapBaseEntity(record);
}
result = getRealDao().insertAll(records);
}
if (recCount > batchCount) {
int times = recCount / batchCount;
int residue = recCount % batchCount;
if (residue > 0) {
times = times + 1;
}
for (int i = 0; i < times; i++) {
if (i == times - 1) {
for (T record : records.subList(batchCount * i, recCount)) {
wrapBaseEntity(record);
}
result = result + getRealDao().insertAll(records.subList(batchCount * i, recCount));
} else {
for (T record : records.subList(batchCount * i, batchCount * (i + 1))) {
wrapBaseEntity(record);
}
result = result + getRealDao().insertAll(records.subList(batchCount * i, batchCount * (i + 1)));
}
}
}
}
return result;
}5.总结
在这个实验过程中有两个因素,一:mysql可接收的最大包限制,二:dubbo的rpc传输允许的最大包限制,解决掉以上两个因素之后,分批次的执行时间和部分批次的执行时间是差不多的,为了节省带宽,提高效率,我们在业务处理和公共方法中都采用小批量入库方式,将大数据量分段处理。到目前为止,数据是可以正常入库了,但是性能上不如人意,需要尝试多线程实验,达到更高效的结果。
相关文章推荐
- mysql 一次性插入上万条数据测试专用
- mysql创建数据库,创建数据库表导入xlsx、txt文本,查询、删除、插入数据语句的使用
- [Php-Mysql]多条数据的循环插入和一次性插入的性能测试
- MySQL笔记(一)创建数据库并插入数据
- mysql分批次插入VS一次性插入
- mysql中向数据库中插入多条数据的方法
- 一次性把DataTable中的数据插入数据库 .
- Java 链接Mysql 数据库时使用变量插入数据方法
- java(功能篇) java(mysql)数据库 实现数据批量插入
- mysql 数据库字段为 call 数据无法插入
- MySQL 数据库怎样把一个表的数据插入到另一个表
- MySQL 数据库怎样把一个表的数据插入到另一个表
- mysql 一次性插入千万级数据
- Navicat for mysql 一次性插入多条数据乱码的问题
- C#一次性向数据库插入上万条数据的方法
- 【ITOO技术篇】——MySQL插入中文数据,存入数据库乱码的问题
- 在JAVA向Mysql的数据库中插入数据过大所遇到的问题
- Mysql 向数据库中插入时间类型数据,数据库中只有日期没有时分秒
- Java 批量插入数据到数据库(MySQL)中
- 修改mysql默认字符集的方法(插入数据库数据乱码)