**决策树基础以及Python代码实现**
2017-12-12 16:18
591 查看
一、一些定义:
1. 信息: 西瓜有好瓜和坏瓜,好瓜的信息为l(xi)=−log2p(xi)p(xi)为好瓜的概率,根据-log函数的图像,如果好瓜的概率越大,信息会趋近于0,也就是从一堆瓜里选出好瓜所需要的信息量越少。
2. 信息熵:熵是信息的期望值Ent(D)=−∑k=1npklog2pkD是西瓜数据集,Ent(D)的值越小,D的纯度越高。
在西瓜只分为好瓜和坏瓜的情况下,p(x1)是好瓜的概率,p(x2)为坏瓜的概率,p(x1)+p(x2)=1,这时候信息熵在它们均为0.5时达到最大,若是纯度较高,即好瓜的概率较大,则信息熵比较小。
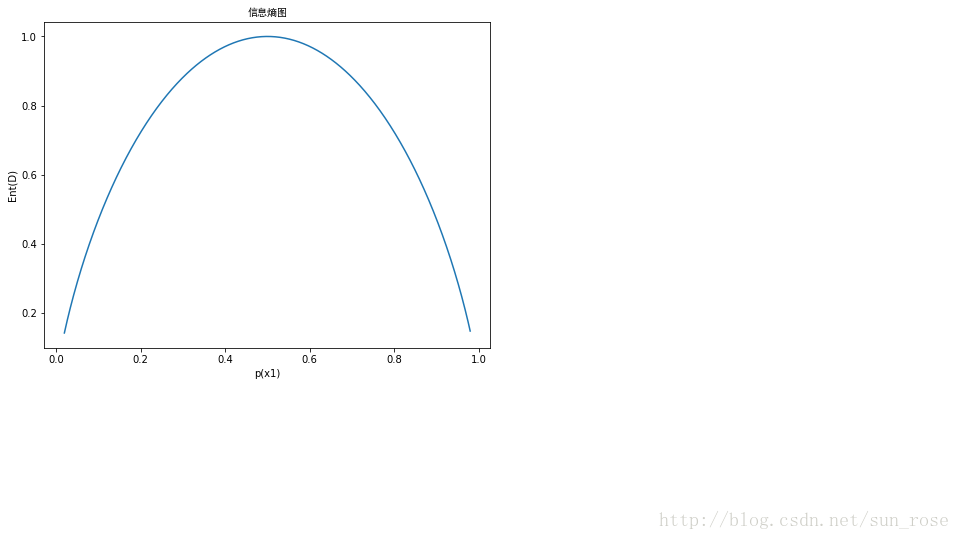
3.信息增益:假定离散属性a有V个可能的取值,若使用属性a对样本集D进行划分,则会有V个分支节点,第v个分支节点上的样本Dv,Dv中也有好瓜和坏瓜,可以计算出Dv的信息熵,信息增益的公式为:Gain(D,a)=Ent(D)−∑v=1V|DV||D|Ent(Dv)|Dv|为Dv中的样本个数,|D|为D中的样本个数。一般而言,信息增益越大,意味着通过属性a划分所获得的“纯度提升”越大。
4.增益率:一般而言,选择的属性可取值数目越多,信息增益会越大,所以为了减少这种不利影响,C4.5不直接用信息增益,而是用‘增益率’(gain ratio)来选择划分最优属性。Gain.ratio(D,a)=Gain(D,a)IV(a)
其中IV(a)=−∑v=1V|Dv||D|log2|Dv||D|
IV(a)是属性a的信息熵,一般属性a的可能取值数目越多,IV(a)通常会越大。C4.5算法不是直接选择增益率最大的划分属性,因为增益率准则对可取值数目较小的属性有所偏好,C4.5是先从候选划分属性中找出信息增益率高于平均水平的属性,再从中选择增益率最高的。(折中选择)
5.基尼系数:基尼值:Gini(D)=∑k=1n∑k′≠kpkpk′=1−∑k=1np2k不难看出,Gini越小,则数据集D的纯度越高。和信息熵的作用是一样的。属性a的基尼指数:Gini.index(D,a)=∑v=1n|Dv||D|Gini(Dv)选择基尼指数最小的属性作为最优划分属性,基尼指数与信息增益的方法一样,只是测量数据集的纯度公式不一样。CART决策树就是用基尼系数准则。
二、决策树算法
1.ID3算法:应用信息增益准则,选择信息增益最大的属性。
2.C4.5算法:信息增益准则偏好可取值数目多的属性,而增益率偏好可取值数目少的属性,因此C4.5算法综合了信息增益准则和增益率准则,首先从候选属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3.CART决策树:使用基尼指数来划分属性,选择基尼指数最小的属性作为最优属性划分,和ID3算法殊途同归,只是衡量数据集纯度的方法不一样。
三、Python代码:
1.计算给定数据集的信息熵
2.按照给定特征划分数据集
3.选择最好的数据集划分方式
1. 信息: 西瓜有好瓜和坏瓜,好瓜的信息为l(xi)=−log2p(xi)p(xi)为好瓜的概率,根据-log函数的图像,如果好瓜的概率越大,信息会趋近于0,也就是从一堆瓜里选出好瓜所需要的信息量越少。
2. 信息熵:熵是信息的期望值Ent(D)=−∑k=1npklog2pkD是西瓜数据集,Ent(D)的值越小,D的纯度越高。
在西瓜只分为好瓜和坏瓜的情况下,p(x1)是好瓜的概率,p(x2)为坏瓜的概率,p(x1)+p(x2)=1,这时候信息熵在它们均为0.5时达到最大,若是纯度较高,即好瓜的概率较大,则信息熵比较小。
3.信息增益:假定离散属性a有V个可能的取值,若使用属性a对样本集D进行划分,则会有V个分支节点,第v个分支节点上的样本Dv,Dv中也有好瓜和坏瓜,可以计算出Dv的信息熵,信息增益的公式为:Gain(D,a)=Ent(D)−∑v=1V|DV||D|Ent(Dv)|Dv|为Dv中的样本个数,|D|为D中的样本个数。一般而言,信息增益越大,意味着通过属性a划分所获得的“纯度提升”越大。
4.增益率:一般而言,选择的属性可取值数目越多,信息增益会越大,所以为了减少这种不利影响,C4.5不直接用信息增益,而是用‘增益率’(gain ratio)来选择划分最优属性。Gain.ratio(D,a)=Gain(D,a)IV(a)
其中IV(a)=−∑v=1V|Dv||D|log2|Dv||D|
IV(a)是属性a的信息熵,一般属性a的可能取值数目越多,IV(a)通常会越大。C4.5算法不是直接选择增益率最大的划分属性,因为增益率准则对可取值数目较小的属性有所偏好,C4.5是先从候选划分属性中找出信息增益率高于平均水平的属性,再从中选择增益率最高的。(折中选择)
5.基尼系数:基尼值:Gini(D)=∑k=1n∑k′≠kpkpk′=1−∑k=1np2k不难看出,Gini越小,则数据集D的纯度越高。和信息熵的作用是一样的。属性a的基尼指数:Gini.index(D,a)=∑v=1n|Dv||D|Gini(Dv)选择基尼指数最小的属性作为最优划分属性,基尼指数与信息增益的方法一样,只是测量数据集的纯度公式不一样。CART决策树就是用基尼系数准则。
二、决策树算法
1.ID3算法:应用信息增益准则,选择信息增益最大的属性。
2.C4.5算法:信息增益准则偏好可取值数目多的属性,而增益率偏好可取值数目少的属性,因此C4.5算法综合了信息增益准则和增益率准则,首先从候选属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3.CART决策树:使用基尼指数来划分属性,选择基尼指数最小的属性作为最优属性划分,和ID3算法殊途同归,只是衡量数据集纯度的方法不一样。
三、Python代码:
1.计算给定数据集的信息熵
from math import log from pandas import DataFrame from collections import Counter def ShannonEnt(dataSet): #自定义一个函数 data = DataFrame(data = dataSet) #把列表转化为表格型数据 num = len(data) #data的行数 labelCounts = Counter(data[3])#对相应列的不同元素计数,这是第四列 shannonEnt = 0.0 #初始化信息熵的值 for key in labelCounts: #遍历labelCounts中的关键字 prob = float(labelCounts[key])/num #计算第四列不同元素出现的概率 shannonEnt -= prob*log(prob,2) #shannonEnt = shannonEnt-prob*log(prob,2) return shannonEnt
2.按照给定特征划分数据集
def splitDataSet(dataSet, axis, value): retDataSet = [] #初始化数据集 for featVec in dataSet: #遍历列表中的每一行 if featVec[axis] == value: #如果该行的第axis+1(给定特征的列)值=value reducedFeatVec = featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) #该行去掉给定特征的列 retDataSet.append(reducedFeatVec)#扩充满足条件的行 return retDataSet
3.选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0])-1 #第一行的个数-1 baseEntropy = ShannonEnt(dataSet) bestInfoGain = 0.0 bestFeature = -1 for i in range(numFeatures): #[i for i in range(3)]->[0,1,2] featList = [example[i] for example in dataSet] #选取dataSet的第i+1列 uniqueVals = set(featList) #去掉重复值 newEntropy = 0.0 for value in uniqueVals: #遍历uniqueVals中的每个值 subDataSet = splitDataSet(dataSet,i,value) #根据第i个特征划分数据集 prob = len(subDataSet)/float(len(dataSet)) newEntropy += prob * ShannonEnt(subDataSet) infoGain = baseEntropy - newEntropy #信息增益公式 if(infoGain > bestInfoGain): bestInfoGain = infoGain bestFeature = i #选取信息增益最大的特征值 return bestFeature

相关文章推荐
- 决策树基本理论学习以及Python代码实现和详细注释
- salesforce 零基础学习(三十六)通过Process Builder以及Apex代码实现锁定记录( Lock Record)
- JAVA 基础语法——开发环境以及J2SE代码实现
- 决策树(CART)、随机森林、GBDT(GBRT)新手导读及资料推荐,附加python实现代码
- 决策树ID3算法python实现代码及详细注释
- 一致性hash以及python代码实现
- IO流基础以及文件流的代码实现
- ID3决策树的Python代码实现
- python爬虫时http协议以及实现代码
- 决策树笔算和python代码实现
- 基于gensim的Doc2Vec简析,以及用python 实现简要代码
- Jquery Ajax客户端跨域请求 以及服务端Python代码实现
- 深度学习基础-决策树应用(python实现)
- 决策树的python代码实现
- 机器学习之决策树(Decision Tree)及其Python代码实现
- Redis订阅&发布以及python代码实现
- 决策树的Python代码实现与分析
- python之文件的读写和文件目录以及文件夹的操作实现代码
- 矩阵分解在推荐系统的应用以及python代码的实现
- python之文件的读写和文件目录以及文件夹的操作实现代码