Python3.6爬虫练习之爬取全国大学省份数据
2017-12-11 19:03
471 查看
分析网页结构
目标网页:http://www.huaue.com/gxmd.htm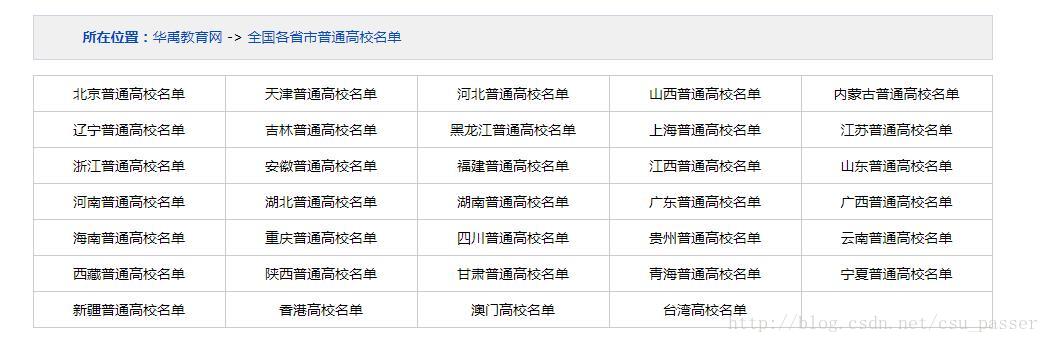
经过F12分析网页结构分析,如图:
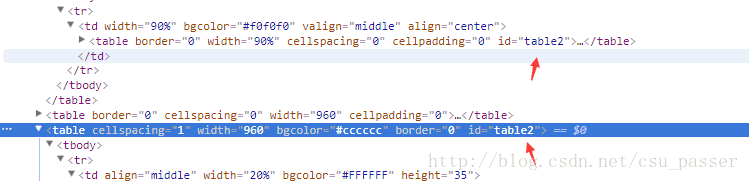
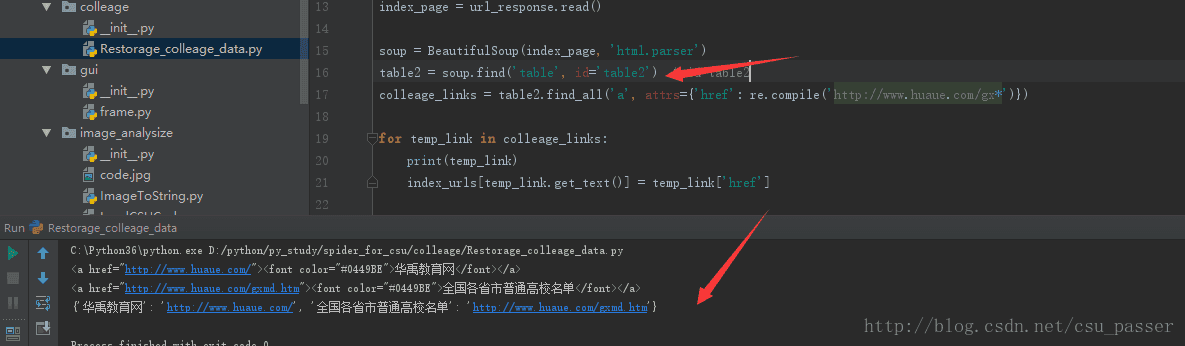
吐槽一下这里,这个网页的前端写的有毒,竟然会有两个相同的id…导致我在写爬虫程序的时候想了好久为什么一直爬取不到数据…如下图
编写小爬虫程序
Python3.6版本中可以直接使用urllib库来抓取GET请求到的网页数据,这里为了方便重用,使用了一个函数:def load_page_content(link): url_request = urllib.request.Request(link) url_response = urllib.request.urlopen(url_request) return url_response.read()
为了方便对网页数据进行分析,我们可以使用BeautifulSoup库。而Python3.6中的pip安装BeautifulSoup库会遇到语法错误,控制台显示如下:
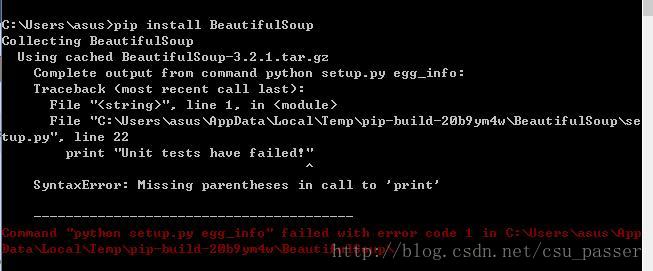
显然是python版本问题…错误代码是python2版本的。
鉴于这种情况,我们可以这样安装:
pip install bs4
在python程序这样引用:
from bs4 import BeautifulSoup
使用方法也很简单,调用BeautifulSoup方法解析网页数据成树形结构,接下来就是遍历,具体操作可以参见文档说明
soup = BeautifulSoup(load_page_content(index_url), 'html.parser')
table2 = soup.find_all('table', id='table2') # id table2
colleage_links = table2[1].find_all('a', attrs={'href': re.compile('http://www.huaue.com/gx*')}) # 正则匹配数据库操作
使用pip安装pymysql模块pip install pymysql
为了更好的复用这些代码,我们可以学习Java中JDBC的使用方法制作一个Util类
# mysql驱动连接
import pymysql
class DBUtil(object):
def __init__(self, db):
self.host = '127.0.0.1'
self.port = 3306
self.user = 'root'
self.password = 'root'
self.db = db
def connect(self):
try:
self.connect = pymysql.connect(host=self.host, port=self.port, user=self.user, passwd=self.password,
db=self.db, charset='utf8')
print('获取connect')
self.cursor = self.connect.cursor() # 获取游标
except:
print('error in connect to mysql')
def save_to_index(self, content, url):
sql = "INSERT INTO `index`(name,url) VALUES('%s', '%s')" % (content, url)
print(sql)
try:
self.cursor.execute(sql)
print('插入当前数据%s成功' % content)
self.connect.commit()
except Exception:
print("insert failed." + Exception)注意:
上面的插入操作一定要将connect对象提交,否则数据库无法正常保存数据
为了正常的使用sql语句操作字符串参数,这里使用了%s做替代符。其实也有另外一种方法,和JDBC一样使用?作为占位符,使用commit方法的时候按照参数顺序给?赋值
程序运行结果:
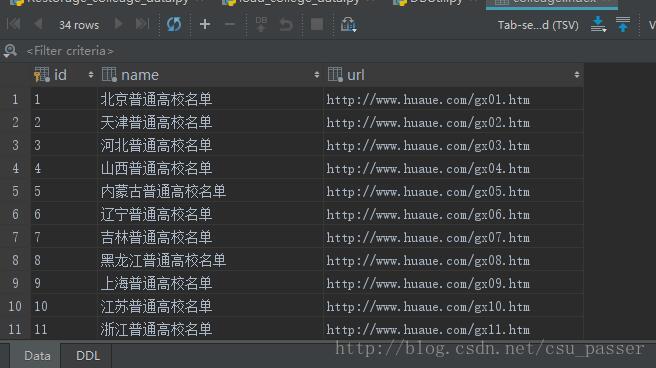
爬虫源码:
import re
import urllib.request
from bs4 import BeautifulSoup
# 储存全国大学数据
from spider_for_csu.colleage.DBUtil import DBUtil
index_url = 'http://www.huaue.com/gxmd.htm' # 源网页
def load_page_content(link): url_request = urllib.request.Request(link) url_response = urllib.request.urlopen(url_request) return url_response.read()
soup = BeautifulSoup(load_page_content(index_url), 'html.parser')
table2 = soup.find_all('table', id='table2') # id table2
colleage_links = table2[1].find_all('a', attrs={'href': re.compile('http://www.huaue.com/gx*')})
util = DBUtil('colleage')
util.connect() # 获取连接
for temp_link in colleage_links:
util.save_to_index(temp_link.get_text(), temp_link['href'])
OS:其实,我真的很在乎 QK

相关文章推荐
- python爬虫练习--爬取某城市历史气象数据(待优化)
- Python爬虫练习之一:抓取美团数据
- python3.x爬虫:爬取大学排名数据
- python 数据可视化练习(2)
- python 爬虫-京东用户评论数据和用户评分
- 【python爬虫】爬取网贷之家所有P2P平台基本数据并写入MYsql数据库
- python 爬虫练习 多线程的运用
- Python爬虫(入门+进阶)学习笔记 1-5 使用pandas保存豆瓣短评数据
- Python爬虫之爬取动态页面数据
- python从零开始写爬虫(5)-- 数据入库
- Python简单爬虫——淘宝数据
- Python爬虫框架Scrapy之爬取糗事百科大量段子数据
- 【爬虫】python selenium 爬取数据
- 操作 Python爬虫数据存储MySQL【3】爬取信息
- Python爬虫——城市公交、地铁站点和线路数据采集
- python爬虫爬取网页表格数据
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- 实践项目十:爬取百度百科Python词条相关1000个页面数据(慕课简单爬虫实战)
- Python爬虫-利用百度地图API接口爬取数据并保存至MySQL数据库