企业级搜索elasticsearch应用04-集群和常用插件安装
2017-12-11 17:29
579 查看
一。配置集群
一个 Elasticsearch 集群至少包括一个节点和一个索引。或者它 可能有一百个数据节点、三个单独的主节点,以及一小打客户端节点——这些共同操作一千个索引(以及上万个分片)。
1》配置集群名称
Elasticsearch 默认启动的集群名字叫 elasticsearch 。 你最好给你的生产环境的集群改个名字,
改名字的目的很简单, 就是防止某人的笔记本电脑加入了集群这种意外。简单修改成 elasticsearch_production 会很省心
以在你的 elasticsearch.yml 文件中修改:
同样,最好也修改你的节点名字。就像你现在可能发现的那样, Elasticsearch 会在你的节点启动的时候随机给它指定一个名字。你可能会觉得这很有趣,
但是当凌晨 3 点钟的时候, 你还在尝试回忆哪台物理机是 Tagak the Leopard Lord 的时候,你就不觉得有趣了。
更重要的是,这些名字是在启动的时候产生的,每次启动节点, 它都会得到一个新的名字。这会使日志变得很混乱,因为所有节点的名称都是不断变化的。
这可能会让你觉得厌烦,我们建议给每个节点设置一个有意义的、清楚的、描述性的名字,同样你可以在 elasticsearch.yml 中配置:
3》配置常用存放目录
默认情况下, Elasticsearch 会把插件、日志以及你最重要的数据放在安装目录下。这会带来不幸的事故,
如果你重新安装 Elasticsearch 的时候不小心把安装目录覆盖了。如果你不小心,你就可能把你的全部数据删掉了。
最好的选择就是把你的数据目录配置到安装目录以外的地方, 同样你也可以选择转移你的插件和日志目录。
以更改如下:
每个集群中 主节点负责保存数据节点的元数据和索引分发 所以同一时刻只能出现一个主节点 配置文件中配置的所有主节点会自动进行选举
选出真正的主节点 假设2个节点选举 发生脑裂互相无法连接 都有可能成为主节点 所以必须要所有配置的master节点中 必须要有一半以上的
节点确认并且选举出来的节点才是真正的主节点
你可以在你的 elasticsearch.yml 文件中这样配置:
如果动态的添加了主节点个数 无需修改配置重启 可以通过rest来永久保存一下配置
》》master节点(主节点)
配置的所有master节点都是候选节点 master作用 用于控制索引的分片 复制等策略 配置为
所有数据节点用于存储索引数据
》》Ingest node(管道节点)
用于处理管道(参考http://blog.csdn.net/liaomin416100569/article/details/78769425)
用于控制什么样的文档处理请求 分发到哪个集群中处理
5》集群恢复配置
想象一下假设你有 10 个节点,每个节点只保存一个分片,这个分片是一个主分片或者是一个副本分片,或者说有一个有 5 个主分片/1 个副本分片的索引。有时你需要为整个集群做离线维护(比如,为了安装一个新的驱动程序), 当你重启你的集群,恰巧出现了 5 个节点已经启动,还有 5 个还没启动的场景。
假设其它 5 个节点出问题,或者他们根本没有收到立即重启的命令。不管什么原因,你有 5 个节点在线上,这五个节点会相互通信,选出一个 master,从而形成一个集群。 他们注意到数据不再均匀分布,因为有 5 个节点在集群中丢失了,所以他们之间会立即启动分片复制。
最后,你的其它 5 个节点打开加入了集群。这些节点会发现 它们 的数据正在被复制到其他节点,所以他们删除本地数据(因为这份数据要么是多余的,要么是过时的)。 然后整个集群重新进行平衡,因为集群的大小已经从 5 变成了 10。
在整个过程中,你的节点会消耗磁盘和网络带宽,来回移动数据,因为没有更好的办法。对于有 TB 数据的大集群, 这种无用的数据传输需要 很长时间 。如果等待所有的节点重启好了,整个集群再上线,所有的本地的数据都不需要移动。
现在我们知道问题的所在了,我们可以修改一些设置来缓解它。 首先我们要给 ELasticsearch 一个严格的限制:
现在我们要告诉 Elasticsearch 集群中 应该 有多少个节点,以及我们愿意为这些节点等待多长时间:
等待集群至少存在 8 个节点
等待 5 分钟,或者10 个节点上线后,才进行数据恢复,这取决于哪个条件先达到。
这三个设置可以在集群重启的时候避免过多的分片交换。这可能会让数据恢复从数个小时缩短为几秒钟。
注意:这些配置只能设置在 config/elasticsearch.yml 文件中或者是在命令行里(它们不能动态更新)它们只在整个集群重启的时候有实质性作用。
6》最好使用单播代替组播
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。
虽然组播仍然 作为插件提供, 但它应该永远不被使用在生产环境了,否在你得到的结果就是一个节点意外的加入到了你的生产环境,仅仅是因为他们收到了一个错误的组播信号。 对于组播 本身 并没有错,组播会导致一些愚蠢的问题,并且导致集群变的脆弱(比如,一个网络工程师正在捣鼓网络,而没有告诉你,你会发现所有的节点突然发现不了对方了)。
使用单播,你可以为 Elasticsearch 提供一些它应该去尝试连接的节点列表。 当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master 节点,并加入集群。
这意味着你的单播列表不需要包含你的集群中的所有节点, 它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了。如果你使用 master 候选节点作为单播列表,你只要列出三个就可以了。 这个配置在 elasticsearch.yml 文件中:(一般配置的是候选master列表)
模拟环境
设置内核参数和ulimit参考 文章01
注意一点是 elasticsearch根目录下的data目录需要清除 因为有之前147的单机数据 否则无法连接的
查看所有节点数
http://192.168.58.150:9200/_cat/nodes?v 可以看到147被选举成了master
查看集群状态
http://192.168.58.147:9200/_cluster/health
打印json
如果部署多个集群 并且需要跨集群搜索 参考官网(https://www.elastic.co/guide/en/elasticsearch/reference/5.6/modules-cross-cluster-search.html)
二。监控插件X-pack安装
X-Pack是一个Elastic Stack的扩展,将安全,警报,监控,报告和图形功能包含在一个易于安装的软件包中 licence是收费的 所以目前来说
找任意一台机器(这里使用 58.147)安装kabana(监控图形界面) 下载的版本和elasticsearch对应
一个 Elasticsearch 集群至少包括一个节点和一个索引。或者它 可能有一百个数据节点、三个单独的主节点,以及一小打客户端节点——这些共同操作一千个索引(以及上万个分片)。
1》配置集群名称
Elasticsearch 默认启动的集群名字叫 elasticsearch 。 你最好给你的生产环境的集群改个名字,
改名字的目的很简单, 就是防止某人的笔记本电脑加入了集群这种意外。简单修改成 elasticsearch_production 会很省心
以在你的 elasticsearch.yml 文件中修改:
cluster.name: elasticsearch_production2》配置节点名称
同样,最好也修改你的节点名字。就像你现在可能发现的那样, Elasticsearch 会在你的节点启动的时候随机给它指定一个名字。你可能会觉得这很有趣,
但是当凌晨 3 点钟的时候, 你还在尝试回忆哪台物理机是 Tagak the Leopard Lord 的时候,你就不觉得有趣了。
更重要的是,这些名字是在启动的时候产生的,每次启动节点, 它都会得到一个新的名字。这会使日志变得很混乱,因为所有节点的名称都是不断变化的。
这可能会让你觉得厌烦,我们建议给每个节点设置一个有意义的、清楚的、描述性的名字,同样你可以在 elasticsearch.yml 中配置:
node.name: elasticsearch_005_data
3》配置常用存放目录
默认情况下, Elasticsearch 会把插件、日志以及你最重要的数据放在安装目录下。这会带来不幸的事故,
如果你重新安装 Elasticsearch 的时候不小心把安装目录覆盖了。如果你不小心,你就可能把你的全部数据删掉了。
最好的选择就是把你的数据目录配置到安装目录以外的地方, 同样你也可以选择转移你的插件和日志目录。
以更改如下:
#数据文件目录 建议设置到多个目录 实现raid0备份 path.data: /path/to/data1,/path/to/data2 # 日志文件目录 path.logs: /path/to/logs # 插件安装目录 path.plugins: /path/to/plugins4》配置最小节点数
每个集群中 主节点负责保存数据节点的元数据和索引分发 所以同一时刻只能出现一个主节点 配置文件中配置的所有主节点会自动进行选举
选出真正的主节点 假设2个节点选举 发生脑裂互相无法连接 都有可能成为主节点 所以必须要所有配置的master节点中 必须要有一半以上的
节点确认并且选举出来的节点才是真正的主节点
你可以在你的 elasticsearch.yml 文件中这样配置:
discovery.zen.minimum_master_nodes: 2此设置应该始终被配置为 master 候选节点的法定个数。法定个数就是 ( master 候选节点个数 / 2) + 1 。 这里有几个例
如果你有 10 个节点(能保存数据,同时能成为 master),法定数就是 6 。 如果你有 3 个候选 master 节点,和 100 个 data 节点,法定数就是 2 ,你只要数数那些可以做 master 的节点数就可以了。 如果你有两个节点,你遇到难题了。法定数当然是 2 ,但是这意味着如果有一个节点挂掉,你整个集群就不可用了。 设置成 1 可以保证集群的功能,但是就无法保证集群脑裂了,像这样的情况,你最好至少保证有 3 个节点。
如果动态的添加了主节点个数 无需修改配置重启 可以通过rest来永久保存一下配置
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 2
}
}在elastic配置中有以下几种节点(https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html)》》master节点(主节点)
配置的所有master节点都是候选节点 master作用 用于控制索引的分片 复制等策略 配置为
node.master: true node.data: false node.ingest: false search.remote.connect: false》》data节点(数据节点)
所有数据节点用于存储索引数据
node.master: false node.data: true node.ingest: false search.remote.connect: false
》》Ingest node(管道节点)
用于处理管道(参考http://blog.csdn.net/liaomin416100569/article/details/78769425)
node.master: false node.data: false node.ingest: true search.remote.connect: false》》Tribe node(客户端节点)
用于控制什么样的文档处理请求 分发到哪个集群中处理
node.master: false node.data: false node.ingest: false search.remote.connect: false
5》集群恢复配置
想象一下假设你有 10 个节点,每个节点只保存一个分片,这个分片是一个主分片或者是一个副本分片,或者说有一个有 5 个主分片/1 个副本分片的索引。有时你需要为整个集群做离线维护(比如,为了安装一个新的驱动程序), 当你重启你的集群,恰巧出现了 5 个节点已经启动,还有 5 个还没启动的场景。
假设其它 5 个节点出问题,或者他们根本没有收到立即重启的命令。不管什么原因,你有 5 个节点在线上,这五个节点会相互通信,选出一个 master,从而形成一个集群。 他们注意到数据不再均匀分布,因为有 5 个节点在集群中丢失了,所以他们之间会立即启动分片复制。
最后,你的其它 5 个节点打开加入了集群。这些节点会发现 它们 的数据正在被复制到其他节点,所以他们删除本地数据(因为这份数据要么是多余的,要么是过时的)。 然后整个集群重新进行平衡,因为集群的大小已经从 5 变成了 10。
在整个过程中,你的节点会消耗磁盘和网络带宽,来回移动数据,因为没有更好的办法。对于有 TB 数据的大集群, 这种无用的数据传输需要 很长时间 。如果等待所有的节点重启好了,整个集群再上线,所有的本地的数据都不需要移动。
现在我们知道问题的所在了,我们可以修改一些设置来缓解它。 首先我们要给 ELasticsearch 一个严格的限制:
gateway.recover_after_nodes: 8这将阻止 Elasticsearch 在存在至少 8 个节点(数据节点或者 master 节点)之前进行数据恢复。 这个值的设定取决于个人喜好:整个集群提供服务之前你希望有多少个节点在线?这种情况下,我们设置为 8,这意味着至少要有 8 个节点,该集群才可用。
现在我们要告诉 Elasticsearch 集群中 应该 有多少个节点,以及我们愿意为这些节点等待多长时间:
gateway.expected_nodes: 10 gateway.recover_after_time: 5m这意味着 Elasticsearch 会采取如下操作:
等待集群至少存在 8 个节点
等待 5 分钟,或者10 个节点上线后,才进行数据恢复,这取决于哪个条件先达到。
这三个设置可以在集群重启的时候避免过多的分片交换。这可能会让数据恢复从数个小时缩短为几秒钟。
注意:这些配置只能设置在 config/elasticsearch.yml 文件中或者是在命令行里(它们不能动态更新)它们只在整个集群重启的时候有实质性作用。
6》最好使用单播代替组播
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。
虽然组播仍然 作为插件提供, 但它应该永远不被使用在生产环境了,否在你得到的结果就是一个节点意外的加入到了你的生产环境,仅仅是因为他们收到了一个错误的组播信号。 对于组播 本身 并没有错,组播会导致一些愚蠢的问题,并且导致集群变的脆弱(比如,一个网络工程师正在捣鼓网络,而没有告诉你,你会发现所有的节点突然发现不了对方了)。
使用单播,你可以为 Elasticsearch 提供一些它应该去尝试连接的节点列表。 当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master 节点,并加入集群。
这意味着你的单播列表不需要包含你的集群中的所有节点, 它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了。如果你使用 master 候选节点作为单播列表,你只要列出三个就可以了。 这个配置在 elasticsearch.yml 文件中:(一般配置的是候选master列表)
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]7》实战配置
模拟环境
192.168.58.147 master 192.168.58.149 master data 192.168.58.150 master data 192.168.58.151 data ingest添加账号
groupadd es; useradd es -g es; passwd es之前 147已经安装 (http://blog.csdn.net/liaomin416100569/article/details/78716175)
scp -r ./elasticsearch-5.6.4 root@192.168.58.149:/home/es scp -r ./elasticsearch-5.6.4 root@192.168.58.150:/home/es scp -r ./elasticsearch-5.6.4 root@192.168.58.151:/home/es147配置
cluster.name: my_cluster_name149配置
node.name: node_147
network.host: 192.168.58.147
http.port: 9200
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 4
discovery.zen.ping.unicast.hosts: ["192.168.58.147", "192.168.58.149", "192.168.58.150"]
node.master: true node.data: false node.ingest: false search.remote.connect: false
cluster.name: my_cluster_name node.name: node_149 network.host: 192.168.58.149 http.port: 9200 discovery.zen.minimum_master_nodes: 2 gateway.recover_after_nodes: 4 discovery.zen.ping.unicast.hosts: ["192.168.58.147", "192.168.58.149", "192.168.58.150"] node.master: true node.data: true node.ingest: false search.remote.connect: false150配置
cluster.name: my_cluster_name node.name: node_150 network.host: 192.168.58.150 http.port: 9200 discovery.zen.minimum_master_nodes: 2 gateway.recover_after_nodes: 4 discovery.zen.ping.unicast.hosts: ["192.168.58.147", "192.168.58.149", "192.168.58.150"] node.master: true node.data: true node.ingest: false search.remote.connect: false151配置
cluster.name: my_cluster_name node.name: node_151 network.host: 192.168.58.151 http.port: 9200 discovery.zen.minimum_master_nodes: 2 gateway.recover_after_nodes: 4 discovery.zen.ping.unicast.hosts: ["192.168.58.147", "192.168.58.149", "192.168.58.150", "192.168.58.151"] node.master: false node.data: true node.ingest: true search.remote.connect: false所有主机进入bin 执行启动命令 ./elasticsearch 147上报错
[2017-12-10T19:53:31,079][WARN ][o.e.d.z.ZenDiscovery ] [my_node_name] not enough master nodes discovered during pinging (found [[Candidate{node={my_node_name}{jRy-sXoCRP6bywdHcptjcA}{9uIaSSb7SEWx4AP6R_crTw}{192.168.58.147}{192.168.58.147:9300}, clusterStateVersion=-1}]], but needed [2]), pinging again因为忘记设置 149-151上所有资源限制的所有 必须要有4个节点ping通才能启动设置内核参数和ulimit参考 文章01
注意一点是 elasticsearch根目录下的data目录需要清除 因为有之前147的单机数据 否则无法连接的
查看所有节点数
http://192.168.58.150:9200/_cat/nodes?v 可以看到147被选举成了master
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 192.168.58.150 3 96 0 0.05 0.35 0.48 md - node_150 192.168.58.149 3 96 0 0.10 0.32 0.43 md - node_149 192.168.58.147 4 96 3 0.09 0.32 0.39 m * my_node_name 192.168.58.151 3 97 0 0.00 0.26 0.36 di - node_151
查看集群状态
http://192.168.58.147:9200/_cluster/health
打印json
{"cluster_name":"my_cluster_name","status":"green","timed_out":false,"number_of_nodes":4,"number_of_data_nodes":3,"active_primary_shards":0,"active_shards":0,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":0,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":100.0}监控命令 参考(https://www.elastic.co/guide/cn/elasticsearch/guide/current/_cluster_health.html)如果部署多个集群 并且需要跨集群搜索 参考官网(https://www.elastic.co/guide/en/elasticsearch/reference/5.6/modules-cross-cluster-search.html)
二。监控插件X-pack安装
X-Pack是一个Elastic Stack的扩展,将安全,警报,监控,报告和图形功能包含在一个易于安装的软件包中 licence是收费的 所以目前来说
找任意一台机器(这里使用 58.147)安装kabana(监控图形界面) 下载的版本和elasticsearch对应
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.6.4-linux-x86_64.tar.gz[/code]切换到es账户下 解压到根目录 /home/es下
kabana安装x-pack插件 用于收集集群的性能信息bin/kibana-plugin install x-pack100多M 可以先window下载下载传上去 (安装过程比较慢)wget https://artifacts.elastic.co/downloads/kibana-plugins/x-pack/x-pack-5.6.4.zip bin/kibana-plugin install file://home/es/x-pack-5.6.4.zip修改kibana的config目录下kibana.yml文件 设置对应监听端口的ip和性能监控的es的http地址server.host: "192.168.58.147" elasticsearch.url: "http://192.168.58.147:9200"elasticsearch需要安装x-pack插件用于收集性能信息
4台es机器安装 x-pack(参考https://www.elastic.co/guide/en/elasticsearch/reference/current/installing-xpack-es.html)./elasticsearch-plugin install x-pack --batch安装过程提示如下[es@node2 bin]$ ./elasticsearch-plugin install x-pack --batch -> Downloading x-pack from elastic [=================================================] 100% @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: plugin requires additional permissions @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ * java.io.FilePermission \\.\pipe\* read,write * java.lang.RuntimePermission accessClassInPackage.com.sun.activation.registries * java.lang.RuntimePermission getClassLoader * java.lang.RuntimePermission setContextClassLoader * java.lang.RuntimePermission setFactory * java.security.SecurityPermission createPolicy.JavaPolicy * java.security.SecurityPermission getPolicy * java.security.SecurityPermission putProviderProperty.BC * java.security.SecurityPermission setPolicy * java.util.PropertyPermission * read,write * java.util.PropertyPermission sun.nio.ch.bugLevel write * javax.net.ssl.SSLPermission setHostnameVerifier See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html for descriptions of what these permissions allow and the associated risks. @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: plugin forks a native controller @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ This plugin launches a native controller that is not subject to the Java security manager nor to system call filters. -> Installed x-pack重启 elastic集群中四台主机
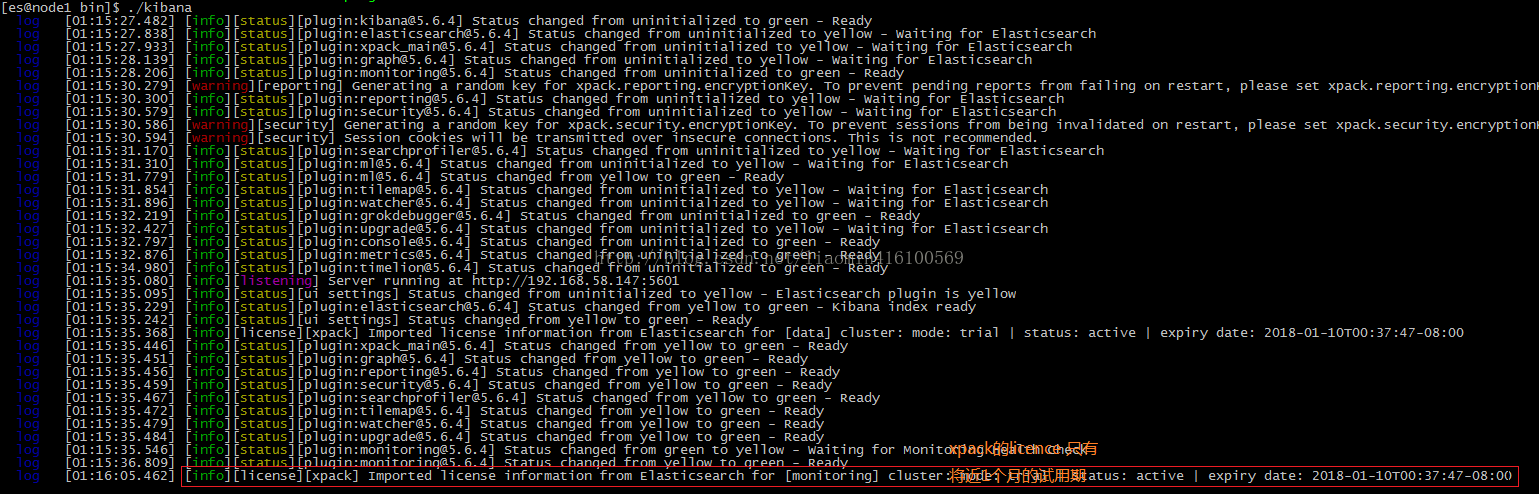
147上启动 kibanabin\kibana浏览器访问 http://192.168.58.147:5601 输入默认用户名(elastic)和密码(changeme)
点击左侧 菜单Monitoring
点击Node4进入就可以看到具体节点信息 可以cpu内存监控
kabana使用es存储监控信息系统 查看es集群的索引库[root@node1 ~]# curl -uelastic:changeme -XGET http://192.168.58.147:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .watcher-history-6-2017.12.12 g5kAtzgCQL2TZ0QJSltepQ 1 1 32 0 241.4kb 192.4kb green open .triggered_watches crH-qGoIQRWs4piJb_9NXw 1 1 0 0 324b 162b green open .monitoring-kibana-6-2017.12.11 kxUeQrmvQx6HyPHgT3tynw 1 1 101 0 189.9kb 94.9kb green open .watcher-history-6-2017.12.11 IrahxNKQT-WzCIqTtZOnMw 1 1 212 0 505.1kb 252.5kb green open .monitoring-es-6-2017.12.12 o2rvrPpMReOg6IloNksZnQ 1 1 982 0 1.6mb 909.9kb green open .kibana lry-GKJXTQ6TYuKv7iOZKg 1 1 1 0 7.7kb 3.8kb green open .monitoring-es-6-2017.12.11 orcNrMt8ReqX6kD2MKAvJg 1 1 3783 0 5.5mb 2.7mb green open .watches q5HpuApsQpmyESJwoZaKjw 1 1 4 0 61.7kb 30.8kbxpack默认的licence只有1个月的试用期 查看kabana启动日志
查看elasticesearch (http://192.168.58.147:9200/_license)1月份就过期了 尝试反编译jar包破解{ "license" : { "status" : "active", "uid" : "b9e358e1-a296-488c-ae7a-b95bcd683ae7", "type" : "trial", "issue_date" : "2017-12-11T08:37:47.039Z", "issue_date_in_millis" : 1512981467039, "expiry_date" : "2018-01-10T08:37:47.039Z", "expiry_date_in_millis" : 1515573467039, "max_nodes" : 1000, "issued_to" : "my_cluster_name", "issuer" : "elasticsearch", "start_date_in_millis" : -1 } }
三。监控插件 elasticsearch-head安装
elasticsearch-head是一个web前端的es集群监控软件 开源代码位于https://github.com/mobz/elasticsearch-head
该插件不建议在es中直接使用插件安装 而是独立安装 使用nodejs开发 必须安装nodejs环境
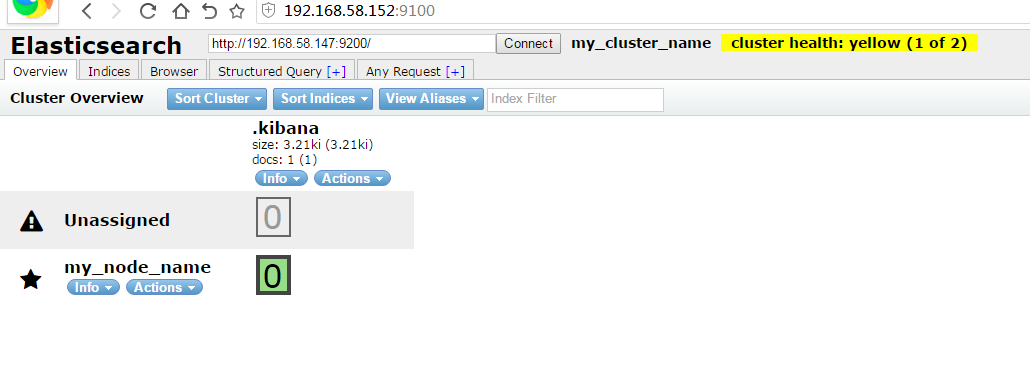
安装主机 (192.168.58.152)nodejs默认在epel仓库中 需要先安装epel库yum -y install epel-release.noarch安装nodejsyum -y install nodejs需要安装git下载head插件代码yum -y install git下载代码git clone git://github.com/mobz/elasticsearch-head.git进入目录使用npm安装(偶尔安装速度很慢 最好启动过墙软件)cd elasticsearch-head/ && npm install启动head(npm run start)[root@bogon elasticsearch-head]# npm run start > elasticsearch-head@0.0.0 start /root/elasticsearch-head > grunt server Running "connect:server" (connect) task Waiting forever... Started connect web server on http://localhost:9100[/code]此时可以使用浏览器访问 http://ip:9100
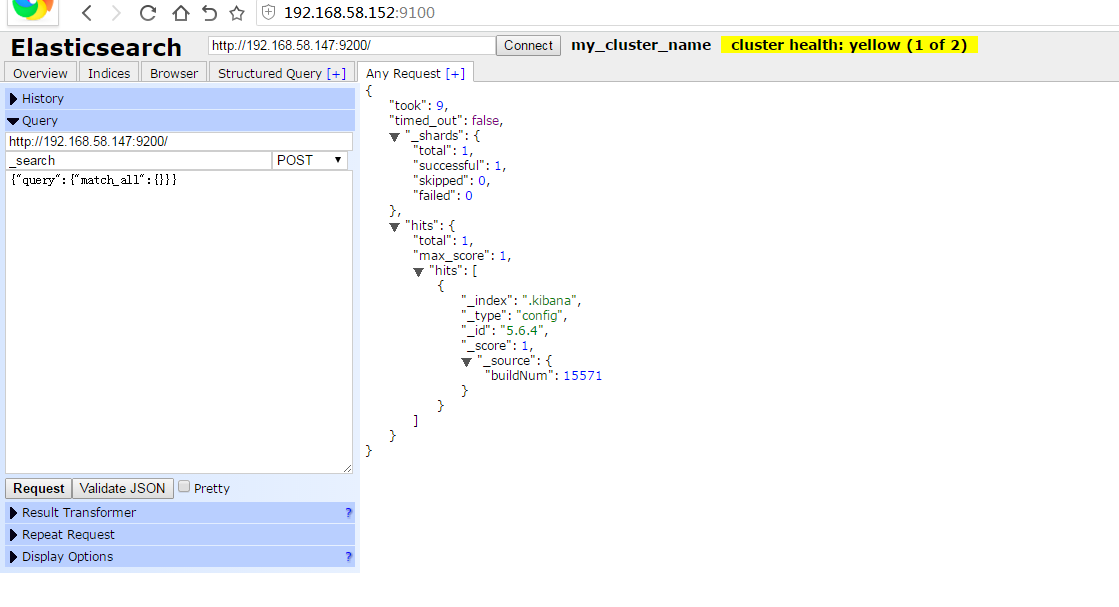
默认elasticsearch 最上面的文本框 连接的http://localhost:9200 我的es安装在147主机上 所以连接时浏览器console报错VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_nodes/stats. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_stats. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_nodes. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_cluster/state. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_cluster/health. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_stats. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_nodes/stats. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_all. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_cluster/state. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_nodes. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_cluster/health. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""} VM36:1 XMLHttpRequest cannot load http://192.168.58.147:9200/_all. Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://192.168.58.152:9100' is therefore not allowed access. app.js:1307 Object {XHR Error: "error", message: ""}分析原来是head使用的http的ajax跨域请求 所以必须让es的http协议允许跨域访问才能获取结果 修改elasticesearch配置文件添加http.cors.enabled: true http.cors.allow-origin: "*"重启elasticsearch 重新访问elasticsearch-head 在最上面的文本框添加http://192.168.58.147:9200即可访问 比如测试head上类似于sense的查询编辑器
类似的开源nodejs的监控插件还有kopf 具体安装参考github官网https://github.com/lmenezes/elasticsearch-kopf
四。SQL语法操作es插件Elasticsearch-SQL
如果熟悉结构数据库 发现json的index相当于表 documen类似于单行的数据 field相当于数据库的列 该插件地址(https://github.com/NLPchina/elasticsearch-sql)
安装的es版本是5.6.4 es-sql选择5.6.4版本 使用es的插件安装
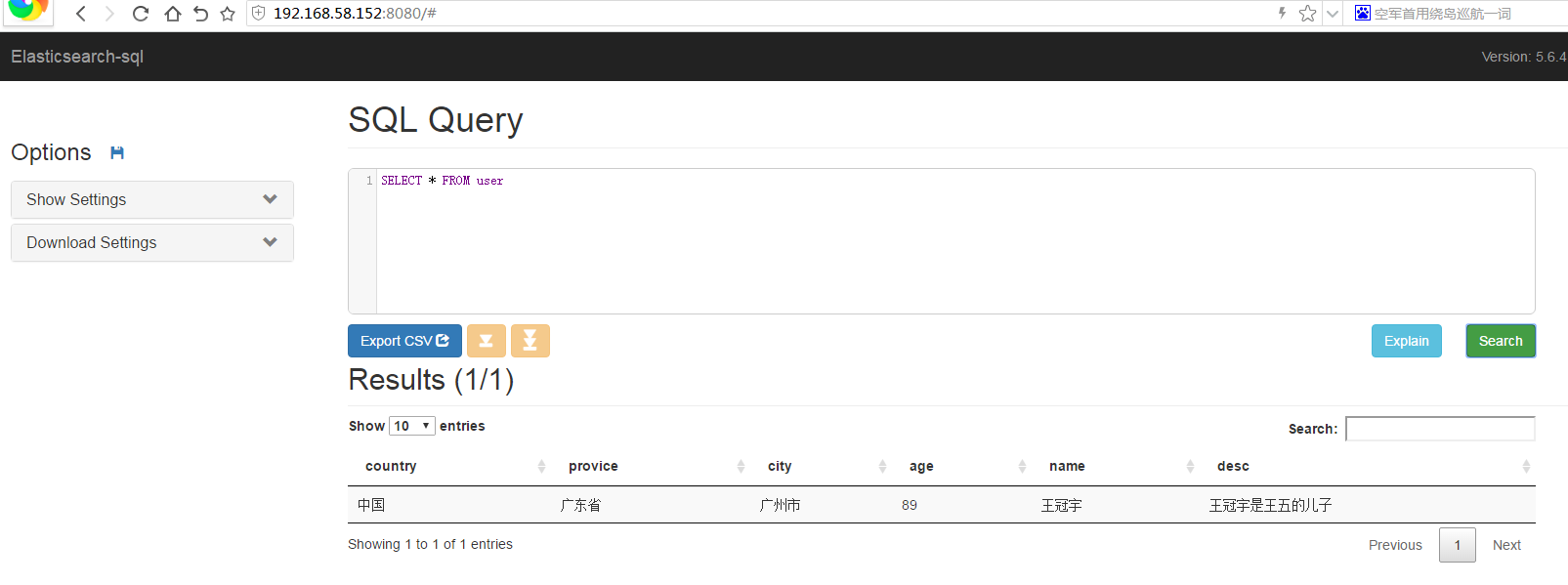
进入elasticsearch根目录./bin/elasticsearch-plugin install https://github.com/NLPchina/elasticsearch-sql/releases/download/5.6.4.0/elasticsearch-sql-5.6.4.0.zip[/code]添加测试数据curl -XPUT '192.168.58.147:9200/user/info/1' -d ' {"country":"中国","provice":"广东省","city":"广州市","age":"89","name":"王冠宇","desc":"王冠宇是王五的儿子"} ';使用命令行操作sql(select* from 索引)http://192.168.58.147:9200/_sql?sql=select * from user结果{"took":364,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":1,"max_score":1.0,"hits":[{"_index":"user","_type":"info","_id":"1","_score":1.0,"_source": {"country":"中国","provice":"广东省","city":"广州市","age":"89","name":"王冠宇","desc":"王冠宇是王五的儿子"} }]}}如果觉得在浏览器地址栏 敲入地址不方便 可以下载 es-sql web前端客户端 开始下载:wget https://github.com/NLPchina/elasticsearch-sql/releases/download/5.4.1.0/es-sql-site-standalone.zip[/code]解压unzip es-sql-site-standalone.zip安装过程 先安装nodejs 参考 章节三
编辑解压目录 _site/controller.js 将 localhost:9200 替换成你的es httpd地址 我的是 192.168.58.147:9200
进入site-server目录cd site-server安装启动npm install express --save node node-server.js默认开启了 8080端口 使用浏览器启动执行sql语句
其他sql语法参考github官网(https://github.com/NLPchina/elasticsearch-sql)



相关文章推荐
- 企业级搜索elasticsearch应用01-单机安装和索引文档操作
- ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决
- ElasticSearch集群搭建及插件安装
- centos7 部署Elasticsearch单机/集群并安装head插件实现ES集群的可视化管理
- 企业级搜索elasticsearch应用02-elasticsearch搜索
- ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决
- ElasticSearch集群搭建及插件安装
- ElasticSearch集群搭建及插件安装
- 分布式搜索ElasticSearch构建集群与简单搜索实例应用
- Elasticsearch常用插件安装
- ElasticSearch集群搭建及插件安装
- ElasticSearch集群搭建及插件安装
- Elasticsearch之marvel(集群管理、监控)插件安装之后的浏览详解
- ElasticSearch集群搭建及插件安装
- ElasticSearch集群搭建及插件安装
- ElasticSearch集群搭建及插件安装
- Elasticsearch集群监控工具bigdesk插件安装
- elasticsearch5.0集群+kibana5.0+head插件插件的安装
- elasticsearch集群安装配置_插件安装
- ElasticSearch及插件安装,集群安装