通过不断重置学习率来逃离局部极值点
2017-12-10 22:46
148 查看
/* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/
黄通文 张俊林( 2016年12月)
注:这篇文章的思路以及本文是我们在2016年底左右做自动发现探索网络结构过程中做的,当时做完发现ICLR 2017有类似论文提出相似的方法,所以没有做更多实验并就把这篇东西搁置了。今天偶然翻到,感觉还是有一定价值,所以现在发出来。
对于神经网络目标函数优化来说,在参数寻优过程中最常用的算法是梯度下降,目前也出现了很多基于SGD基础上的改进算法,比如带动量的SGD,Adadelta,Adagrad,Adam,RMSProp等梯度下降改进方法,这些算法大多都是针对基础更新公式进行改进:
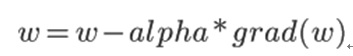
其中,w是训练过程中的当前参数值,alpha是学习率,grad(w)是此刻的梯度方向。目前的改进算法要么修正学习率alpha要么修正梯度计算方法grad(w),要么两者都修正,比如Adagrad/Adam动态调整学习率,Adam动态调整梯度的更新量或者有些算法加入动量部分。
一般深度神经网络由于很深的深度以及非线性函数这两个主要因素,导致目标的损失函数是非凸函数,该损失函数曲面中包含许多的驻点,驻点可能是以下三类关键点中的一种:鞍点,局部极小值,全局极小值,其中全局极小值是我们期望训练算法能够找到的,而其它两类是期望能够避免的。一个示意性的损失函数曲面如下图所示:
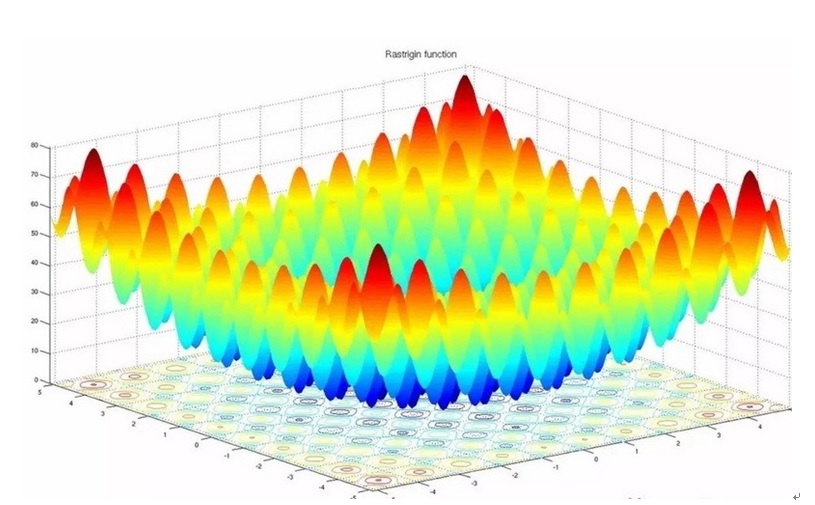
不少学习算法在训练过程中,随着误差的减少,迭代次数的增加,步长变化越来越小,训练误差越来越小直到变为零,局部探索到一个驻点,如果这个点是误差曲面的鞍点,即不是最大值也不是最小值的平滑曲面,那么一般结果表现为性能比较差;如果这个驻点是局部极小值,那么表现为性能较好,但不是全局最优值。目前大多数训练算法在碰到无论是鞍点还是局部极值点的时候,因为此刻学习率已经变得非常小,所以会陷入非全局最优值不能自拔。这其实就是目前采用SGD类似的一阶导数方法训练机器学习系统面临的一个很重要的问题。
目前来看,没有方法能够保证找到非凸函数优化过程中的全局最小值,也就是说,不论你怎么调参将性能调到你能做到的最好,仍然大概率获得了优化过程中的一个鞍点或者局部极小值,那么一个很自然的想法就是:能否在优化过程的末尾,就是已经大概率陷入某个局部极小值或者鞍点的时候,放大学习率,强行让训练算法跳出当前的局部最小值或者鞍点,所谓“世界这么大,我想去看看”,继续寻找可能效果会更好的极值点,这样多次跳出优化过程中的局部最小值,然后比较其中性能最好的极小值,并以那个时刻的参数作为模型参数。当然,这仍然没有办法保证找到全局最小值,只是说多比较一些极值点,矮子里面拔将军的意思。这个思路是去年我们在利用人工生命和遗传算法探索自动生成神经网络结构的不断优化网络性能过程中产生的,当时是看到了SNAPSHOT ENSEMBLES : TRAIN 1,GET M FOR FREE这篇论文受到启发动了这个念头,于是单独测试了一下这个思路,结果表明一般情况下,这种方法是能够有效提升优化效果的,不过提升幅度不算太大(后来看到了这篇论文:SGDR: STOCHASTIC GRADIENT DESCENT RESTARTS 发现基本思路是有点类似的)。
一.两种跳出驻点的方法
上面说了基本思路,其实思路很朴实也很简单:常见的训练方法在刚开始的时候学习率设置的比较大,这样可以大幅度快步向极值点迈进,加快收敛速度,随着越来越接近极值点,逐步将学习率调小,这样避免步子太大跳过极值点或者造成优化过程震荡结果不稳定。当优化到性能无法再提升的时候,此时大概率陷入了鞍点或者局部极小值,表现为梯度接近于0而且一般此时学习率已经调整到非常小的程度了。跳出驻点的思路就是说:此时可以重新把已经调整的很小的学习率数值放大,强行逼迫优化算法跳出此刻找到的鞍点或者极值点,在上述示意的损失函数曲面上等于当前在某个山谷的谷底(或者某个平台上,即鞍点),此时迈出一大步跳到比较远的地方,然后继续常规的优化过程,就是不断调小学习率,期望找到附近的另外一个山谷谷底,如此往复若干次,然后找出这些谷底哪个谷底更深,然后采取这个最深的谷底对应的参数作为模型参数。
所以这里的关键是在优化进行不下去的时候重新调大学习率跳出当前的山谷,根据起跳点的不同,可以有两种不同的方法:
方法1:随机漫步起跳法 这个方法比较简单,就是说当前优化走到哪个山谷谷底,就从当前位置起跳,直接调大学习率即可,因为这样类似于走到哪里走不下去就从哪里开始跳到附近的远处,走到哪算哪,所以称之为“随机漫步起跳法”。
方法2:历史最优起跳法上面说过,在这种优化方法过程中,会不断进入某个谷底,那么假设在训练集上优化历史上已经经过K个谷底,在验证集上其对应参数的模型性能是可以知道的,分别为P1,P2……Pk。随机漫步起跳法就是从Pk作为起跳点进行起跳。而历史最优起跳法则从P1,P2……Pk中性能最优的那个山谷谷底开始起跳,假设Pi=Max(P1,P2……Pk),那么从第i个山谷开始起跳,如果跳出后发现第j个山谷的性能Pj要优于Pi,则后面从Pj的位置开始起跳,当从Pi跳过K次都没有发现比Pi性能更好的山谷,此时可以终止优化算法。这个有点像是Pi性能的“一山望着一山高”,然后不断从历史最高峰跳到更高的高山上,可以保证性能应该越来越好。从道理上讲感觉这种历史最优起跳法要好于随机漫步起跳法,但是实验结果表明两种不同的起跳方法性能是差不多的,有时候这个稍好点,有时候那个稍好点,没有哪个方法确定性的比另外一个好。
二.相关的实验及其结果
为了检验上述跳出驻点的思路是否有效,我们选择了若干深层CNN模型来测试,这里列出其中某个模型的结果,这个模型结构可能看上去有点奇怪,前面说过这个思路是我们去年在做网络最优结构自动探索任务中产生的,所以这两个比较奇怪的结构是从自动生成的网络结构里面随机选出的,性能比较好。分类数据是cifar10图片分类数据,选择带动量的SGD算法作为基准方法来进行相关实验的验证。
2.1模型结构及参数配置
CNN模型结构如下图所示:
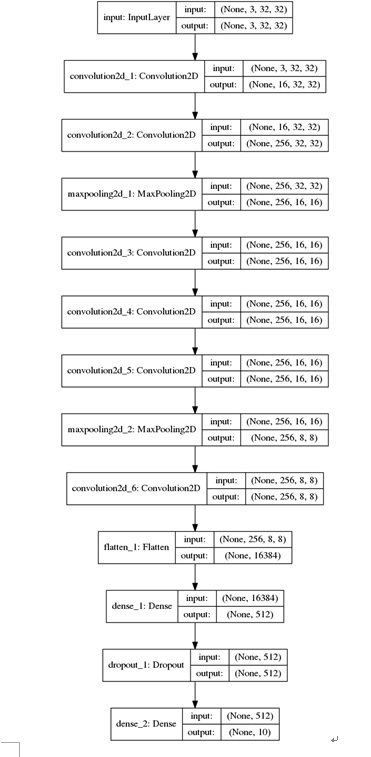
其模型结构为:model structure:('init-29', [('conv', [('nb_filter', 16)]), ('conv',[('nb_filter', 256)]), ('maxp', [('pool_size', 2)]), ('conv', [('nb_filter',256)]), ('conv', [('nb_filter', 256)]), ('conv', [('nb_filter', 256)]),('maxp', [('pool_size', 2)]), ('conv', [('nb_filter', 256)])])")
后面部分接上fc(512,relu)+dropout(0.2)+fc(10,softmax)的分类层;
学习算法设置的参数为: 选择使用Nesterov的带动量的随机梯度下降法,初始学习率为0.01,衰减因子为1e-6,momentum因子为0.9。
2.2 Nesterov+动量SGD(固定学习率)实验效果在上节所述的模型设置下,从结果看,最好的测试精度是0.9060,模型的误差和精度都变化地比较平滑
2.3学习率自适应减少进行训练的实验结果
其它配置类似于2.1.2所述,唯一的不同在于:使用常规策略对学习率进行缩小的改变。改变学习率的策略是如果误差10次不变化,那么学习率缩小为原来的0.1倍。 总迭代次数设置为100次。 训练误差、训练准确率、测试误差、测试准确率的变化曲线为:

从训练结果看,第47次学习率变化,性能上有一次大幅度的提高:
从训练和测试的结果看,测试精度最高的是在第80轮,达到了0.9144。此时的训练误差0.3921,训练准确率0.9926,测试误差0.3957,测试准确率0.9144。
由此可见,增加学习率的动态改变,在学习速度和质量上要比原始的学习率恒定的训练方法要好,这里性能上增加近一个百分点。 2.4随机漫步起跳法实验结果
从上面的两组实验结果过程的最后阶段可以看出,误差和准确率变化较小,很可能优化过程陷入一个局部最优值,可能是一个极值,也可能是一个鞍点,不管怎样称呼它,它就是一个驻点。(从结果看,应该是一个局部最优值)。在其它实验条件与2.1.3节所述相同情况下,采取上文所述的随机漫步起跳法强迫优化算法跳出当前局部最优,即在学习率比较低的时候,进行扩大学习率的方式(直接设置为0.1,后面再常规的逐步减少),让其在误差曲面的区域中去寻找更多的驻点。 具体做法是:如果当前发现经过三次学习率变小没有带来准确率的提升,那么在当前训练的点,将学习率恢复到初始的学习率即0.01。 迭代的效果如下训练误差、训练准确率、测试误差、测试准确率的变化曲线如下图为:
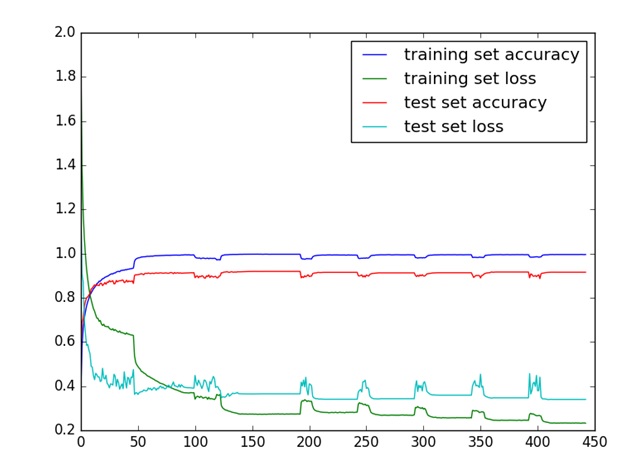
从训练过程看,从当前迭代的当前位置出发,采用学习率缩小和扩大相结合的方式,目前最高能在第153轮的准确率提高到0.9236,比之前最好的0.9144有一点提升,说明这样的学习率变大策略也是一种可行的思路。
另外,从图中看,由于我们变大学习率许多次,每次学习率变大都会呈现一个波动形式,故结果表现出锯齿状的波动趋势。
2.5历史最优起跳法实验结果 我们做了类似的实验,发现历史最优起跳法与随机漫步起跳法性能相当,有时这个好点有时那个好点,没有发现性能明显差异。 我们随机抽了其它几个最优网络结构自动探索出的深度神经网络结构,表现与上述网络结构类似,而如果基础网络结构本身性能越差,这个差别越大。
所以可以得出的结论是:优化过程中采用常规动态学习率调整效果要优于固定学习率的方法,而随机漫步起跳法效果略优于常规的动态学习率调整方法,但是历史最优起跳法相对常规动态学习率方法没有发现改善。 相关文献
SGDR: STOCHASTIC GRADIENT DESCENT RESTARTS .ICLR-2017
SNAPSHOT ENSEMBLES : TRAIN 1,GET M FOR FREE
黄通文 张俊林( 2016年12月)
注:这篇文章的思路以及本文是我们在2016年底左右做自动发现探索网络结构过程中做的,当时做完发现ICLR 2017有类似论文提出相似的方法,所以没有做更多实验并就把这篇东西搁置了。今天偶然翻到,感觉还是有一定价值,所以现在发出来。
对于神经网络目标函数优化来说,在参数寻优过程中最常用的算法是梯度下降,目前也出现了很多基于SGD基础上的改进算法,比如带动量的SGD,Adadelta,Adagrad,Adam,RMSProp等梯度下降改进方法,这些算法大多都是针对基础更新公式进行改进:
其中,w是训练过程中的当前参数值,alpha是学习率,grad(w)是此刻的梯度方向。目前的改进算法要么修正学习率alpha要么修正梯度计算方法grad(w),要么两者都修正,比如Adagrad/Adam动态调整学习率,Adam动态调整梯度的更新量或者有些算法加入动量部分。
一般深度神经网络由于很深的深度以及非线性函数这两个主要因素,导致目标的损失函数是非凸函数,该损失函数曲面中包含许多的驻点,驻点可能是以下三类关键点中的一种:鞍点,局部极小值,全局极小值,其中全局极小值是我们期望训练算法能够找到的,而其它两类是期望能够避免的。一个示意性的损失函数曲面如下图所示:
不少学习算法在训练过程中,随着误差的减少,迭代次数的增加,步长变化越来越小,训练误差越来越小直到变为零,局部探索到一个驻点,如果这个点是误差曲面的鞍点,即不是最大值也不是最小值的平滑曲面,那么一般结果表现为性能比较差;如果这个驻点是局部极小值,那么表现为性能较好,但不是全局最优值。目前大多数训练算法在碰到无论是鞍点还是局部极值点的时候,因为此刻学习率已经变得非常小,所以会陷入非全局最优值不能自拔。这其实就是目前采用SGD类似的一阶导数方法训练机器学习系统面临的一个很重要的问题。
目前来看,没有方法能够保证找到非凸函数优化过程中的全局最小值,也就是说,不论你怎么调参将性能调到你能做到的最好,仍然大概率获得了优化过程中的一个鞍点或者局部极小值,那么一个很自然的想法就是:能否在优化过程的末尾,就是已经大概率陷入某个局部极小值或者鞍点的时候,放大学习率,强行让训练算法跳出当前的局部最小值或者鞍点,所谓“世界这么大,我想去看看”,继续寻找可能效果会更好的极值点,这样多次跳出优化过程中的局部最小值,然后比较其中性能最好的极小值,并以那个时刻的参数作为模型参数。当然,这仍然没有办法保证找到全局最小值,只是说多比较一些极值点,矮子里面拔将军的意思。这个思路是去年我们在利用人工生命和遗传算法探索自动生成神经网络结构的不断优化网络性能过程中产生的,当时是看到了SNAPSHOT ENSEMBLES : TRAIN 1,GET M FOR FREE这篇论文受到启发动了这个念头,于是单独测试了一下这个思路,结果表明一般情况下,这种方法是能够有效提升优化效果的,不过提升幅度不算太大(后来看到了这篇论文:SGDR: STOCHASTIC GRADIENT DESCENT RESTARTS 发现基本思路是有点类似的)。
一.两种跳出驻点的方法
上面说了基本思路,其实思路很朴实也很简单:常见的训练方法在刚开始的时候学习率设置的比较大,这样可以大幅度快步向极值点迈进,加快收敛速度,随着越来越接近极值点,逐步将学习率调小,这样避免步子太大跳过极值点或者造成优化过程震荡结果不稳定。当优化到性能无法再提升的时候,此时大概率陷入了鞍点或者局部极小值,表现为梯度接近于0而且一般此时学习率已经调整到非常小的程度了。跳出驻点的思路就是说:此时可以重新把已经调整的很小的学习率数值放大,强行逼迫优化算法跳出此刻找到的鞍点或者极值点,在上述示意的损失函数曲面上等于当前在某个山谷的谷底(或者某个平台上,即鞍点),此时迈出一大步跳到比较远的地方,然后继续常规的优化过程,就是不断调小学习率,期望找到附近的另外一个山谷谷底,如此往复若干次,然后找出这些谷底哪个谷底更深,然后采取这个最深的谷底对应的参数作为模型参数。
所以这里的关键是在优化进行不下去的时候重新调大学习率跳出当前的山谷,根据起跳点的不同,可以有两种不同的方法:
方法1:随机漫步起跳法 这个方法比较简单,就是说当前优化走到哪个山谷谷底,就从当前位置起跳,直接调大学习率即可,因为这样类似于走到哪里走不下去就从哪里开始跳到附近的远处,走到哪算哪,所以称之为“随机漫步起跳法”。
方法2:历史最优起跳法上面说过,在这种优化方法过程中,会不断进入某个谷底,那么假设在训练集上优化历史上已经经过K个谷底,在验证集上其对应参数的模型性能是可以知道的,分别为P1,P2……Pk。随机漫步起跳法就是从Pk作为起跳点进行起跳。而历史最优起跳法则从P1,P2……Pk中性能最优的那个山谷谷底开始起跳,假设Pi=Max(P1,P2……Pk),那么从第i个山谷开始起跳,如果跳出后发现第j个山谷的性能Pj要优于Pi,则后面从Pj的位置开始起跳,当从Pi跳过K次都没有发现比Pi性能更好的山谷,此时可以终止优化算法。这个有点像是Pi性能的“一山望着一山高”,然后不断从历史最高峰跳到更高的高山上,可以保证性能应该越来越好。从道理上讲感觉这种历史最优起跳法要好于随机漫步起跳法,但是实验结果表明两种不同的起跳方法性能是差不多的,有时候这个稍好点,有时候那个稍好点,没有哪个方法确定性的比另外一个好。
二.相关的实验及其结果
为了检验上述跳出驻点的思路是否有效,我们选择了若干深层CNN模型来测试,这里列出其中某个模型的结果,这个模型结构可能看上去有点奇怪,前面说过这个思路是我们去年在做网络最优结构自动探索任务中产生的,所以这两个比较奇怪的结构是从自动生成的网络结构里面随机选出的,性能比较好。分类数据是cifar10图片分类数据,选择带动量的SGD算法作为基准方法来进行相关实验的验证。
2.1模型结构及参数配置
CNN模型结构如下图所示:
其模型结构为:model structure:('init-29', [('conv', [('nb_filter', 16)]), ('conv',[('nb_filter', 256)]), ('maxp', [('pool_size', 2)]), ('conv', [('nb_filter',256)]), ('conv', [('nb_filter', 256)]), ('conv', [('nb_filter', 256)]),('maxp', [('pool_size', 2)]), ('conv', [('nb_filter', 256)])])")
后面部分接上fc(512,relu)+dropout(0.2)+fc(10,softmax)的分类层;
学习算法设置的参数为: 选择使用Nesterov的带动量的随机梯度下降法,初始学习率为0.01,衰减因子为1e-6,momentum因子为0.9。
2.2 Nesterov+动量SGD(固定学习率)实验效果在上节所述的模型设置下,从结果看,最好的测试精度是0.9060,模型的误差和精度都变化地比较平滑
2.3学习率自适应减少进行训练的实验结果
其它配置类似于2.1.2所述,唯一的不同在于:使用常规策略对学习率进行缩小的改变。改变学习率的策略是如果误差10次不变化,那么学习率缩小为原来的0.1倍。 总迭代次数设置为100次。 训练误差、训练准确率、测试误差、测试准确率的变化曲线为:
从训练结果看,第47次学习率变化,性能上有一次大幅度的提高:
从训练和测试的结果看,测试精度最高的是在第80轮,达到了0.9144。此时的训练误差0.3921,训练准确率0.9926,测试误差0.3957,测试准确率0.9144。
由此可见,增加学习率的动态改变,在学习速度和质量上要比原始的学习率恒定的训练方法要好,这里性能上增加近一个百分点。 2.4随机漫步起跳法实验结果
从上面的两组实验结果过程的最后阶段可以看出,误差和准确率变化较小,很可能优化过程陷入一个局部最优值,可能是一个极值,也可能是一个鞍点,不管怎样称呼它,它就是一个驻点。(从结果看,应该是一个局部最优值)。在其它实验条件与2.1.3节所述相同情况下,采取上文所述的随机漫步起跳法强迫优化算法跳出当前局部最优,即在学习率比较低的时候,进行扩大学习率的方式(直接设置为0.1,后面再常规的逐步减少),让其在误差曲面的区域中去寻找更多的驻点。 具体做法是:如果当前发现经过三次学习率变小没有带来准确率的提升,那么在当前训练的点,将学习率恢复到初始的学习率即0.01。 迭代的效果如下训练误差、训练准确率、测试误差、测试准确率的变化曲线如下图为:
从训练过程看,从当前迭代的当前位置出发,采用学习率缩小和扩大相结合的方式,目前最高能在第153轮的准确率提高到0.9236,比之前最好的0.9144有一点提升,说明这样的学习率变大策略也是一种可行的思路。
另外,从图中看,由于我们变大学习率许多次,每次学习率变大都会呈现一个波动形式,故结果表现出锯齿状的波动趋势。
2.5历史最优起跳法实验结果 我们做了类似的实验,发现历史最优起跳法与随机漫步起跳法性能相当,有时这个好点有时那个好点,没有发现性能明显差异。 我们随机抽了其它几个最优网络结构自动探索出的深度神经网络结构,表现与上述网络结构类似,而如果基础网络结构本身性能越差,这个差别越大。
所以可以得出的结论是:优化过程中采用常规动态学习率调整效果要优于固定学习率的方法,而随机漫步起跳法效果略优于常规的动态学习率调整方法,但是历史最优起跳法相对常规动态学习率方法没有发现改善。 相关文献
SGDR: STOCHASTIC GRADIENT DESCENT RESTARTS .ICLR-2017
SNAPSHOT ENSEMBLES : TRAIN 1,GET M FOR FREE

相关文章推荐
- Linux指令中英文解——希望通过本文不断收集整理linux英文命令,让人见文知意
- 一般的病毒通过注册表自启动的方式不断完善中。。。。
- [转]asp.net中通过代码来重置sessionid
- php通过iframe实现局部刷新
- Linux之redhat通过脚本文件创建对照并重置虚拟机
- 通过jQuery实现Ajax局部刷新
- 通过.txt/.excel提供的数据对完整图像进行局部抠图
- Android手机重置之后通过file:///mnt/sdcard访问不了本地文件
- 不通过删除重建方式重置序列值得简单方式。
- 通过label标签重置input[radio]样式
- html通过js调用php实现局部更新
- Domino9下通过代理实现WEB方式重置Internet密码
- 通过代码实现web方式重置域密码及同步Domino密码
- 在进行嵌入式开发之前,首先要建立一个交叉编译环境,这是一套编译器、连接器和libc库等组成的开发环境。文章通过一个具体的例子说明了这些嵌入式交叉编译开发工具的制作过程。 随着消费类电子产品的大量开发和应用和Linux操作系统的不断健壮和强大,嵌入式系统越来
- 忘记root密码通过单用户模式重置过程
- win7密码忘了怎么办 通过U盘重置win7密码技巧图解
- [置顶] java web通过163邮箱重置登录密码
- LevelDb简单介绍和原理——本质:类似nedb,插入数据文件不断增长(快照),再通过删除老数据做更新
- 不通过form改用户的密码,直接在PL/SQL中重置用户密码
- 利用win10 启动盘,重置,删除win10系统本地账户(通过进入管理员账户实现):