根据电影名称(支持电视剧名称),获取下载链接。
2017-12-06 13:43
513 查看
做个笔记
(python 3.6,django 2.0)
用django展现在页面效果如下:
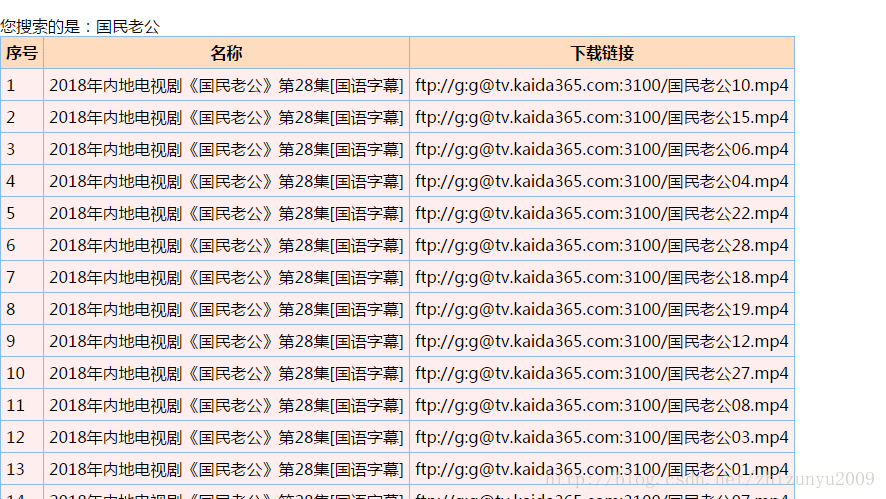
另一个网站的
(python 3.6,django 2.0)
# -*- coding: utf-8 -*-
import urllib
from bs4 import BeautifulSoup
import re
#访问url,返回html页面
def get_html(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0')
response = urllib.request.urlopen(url)
html = response.read()
return html
def get_movie_url(movie_name):#根据电影名称,生成搜索结果的URL
host_url = 'http://s.dydytt.net/plus/search.php?kwtype=0&keyword='
movie_sign = urllib.parse.quote(movie_name.encode('GBK'))
search_url = host_url + movie_sign
return search_url
#从搜索结果页面,提取电影的详情页面链接,存入列表返回
def get_movie_list(url):
m_list = []
html = get_html(url)
soup = BeautifulSoup(html,'html.parser')
fixed_html = soup.prettify()
a_urls = soup.find_all('a')
host = "http://www.ygdy8.com"
for a_url in a_urls:
m_url = a_url.get('href')
m_url = str(m_url)
if re.search(r'\d{8}',m_url) and (host not in m_url):
m_list.append(host + m_url)
return m_list
#从电影详情页面中获取电影标题
def get_movie_title(html):
soup=BeautifulSoup(html,'html.parser')
fixed_html=soup.prettify()
title=soup.find('h1')
title=title.string
return title
#从电影详情页面中获取此页面所有的的下载链接
def get_movie_download_url(html):
soup = BeautifulSoup(html,'html.parser')
fixed_html = soup.prettify()
td = soup.find_all('td',attrs={'style':'WORD-WRAP: break-word'})
down_urls = []
for t in td:
down_urls.append(t.a.get('href'))
return down_urls
#传入电影列表,获取每个电影的下载地址
def get_movie(movie_list):
movie_dict = {}
for i in range(0,len(movie_list)):
html = get_html(movie_list[i])
html = html.decode('GBK','ignore') #忽略编码错误
m_title = get_movie_title(html)
if u'游戏' not in m_title: #过滤游戏
if u'动画' not in m_title: #过滤动画片
m_url_list = get_movie_download_url(html)
for m_url in m_url_list:
movie_dict[m_url] = m_title
return movie_dict用django展现在页面效果如下:
另一个网站的
# -*- coding: utf-8 -*-
from xpinyin import Pinyin
from bs4 import BeautifulSoup
from urllib import request,error
import time,re
import ssl
ssl._create_default_https_context = ssl._create_unverified_context #关闭https协议验证证书
def get_html(url): #访问url,返回html页面,如果url错误,则返回状态码,一般是404
req = request.Request(url)
req.add_header('User-Agent','Mozilla/5.0')
try:
response = request.urlopen(url)
html = response.read()
return html
except error.HTTPError as e:
return e.code
def get_m_html(movie_name):#根据电影名称,返回正确的电影html
pin = Pinyin()
pinyin_movie_name = pin.get_pinyin(movie_name,"")#不使用分隔符,默认是-
movie_type = {
"Sciencefiction":"科幻片",
"Horror" :"恐怖片",
"Drama" :"剧情片",
"Action" :"动作片",
"Comedy" :"喜剧片",
"Love" :"爱情片",
"War" :"战争片"
}
host = "https://www.kankanwu.com"
for k,v in movie_type.items():
movie_url = host + "/" + k + "/" + pinyin_movie_name + "/"
html = get_html(movie_url)
if isinstance(html,int):
time.sleep(10)
else:
return html
def get_dload_url(html): #从电影html页面中获取下载地址
movie_dict = {}
soup = BeautifulSoup(html,'lxml')
fixed_html = soup.prettify()
a_urls = soup.find_all(href=re.compile("thunder"))#找到含有thunder链接的href
for url in a_urls:
m_title = url.get('title')
m_url = url.get('href')
movie_dict[m_title] = m_url
return movie_dict

相关文章推荐
- 使用Tornado框架写了一个用于获取电影下载链接的API接口,欢迎大家使用 :-)
- 根据文件下载链接地址获取文件的大小
- Python多线程爬虫获取电影下载链接
- 使用Python3获取360影视首页上电影的名称,年份,评价,播放链接并保存为txt文本
- Java 根据下载链接获取文件名
- java 获取网络文件获取流下载,支持IE火狐 直接下载而不直接打开
- Linux上配置Apache支持中文名称文件下载
- 根据数据库名获取所有表及视图名称
- [置顶] 【python 下载器】python下载电影&视频&电视剧
- 使文件下载的自定义连接支持 FlashGet 的断点续传多线程链接下载! C#/ASP.Net 实现!
- 根据经纬度获取地点名称
- Java爬虫实战(二):抓取一个视频网站上2015年所有电影的下载链接
- 使文件下载的自定义连接支持 FlashGet 的断点续传多线程链接下载! C#/ASP.Net 实现!
- 如何在只知道自己应用Apple ID和项目名称的情况下推出自己的应用在AppStore的下载链接
- dedeCMS5.7在任意栏目获取顶级栏目名称及链接的方法
- JavaScript根据Cookie名称获取Cookie值
- WordPress: 根据分类别名获取分类链接
- java爬虫框架——jsoup的简单使用(爬取电影天堂的所有电影的信息,包括下载的链接)
- [Objc]_[获取Mac下的字体库支持的所有字体名称]
- Java爬虫实战(二):抓取一个视频网站上2015年所有电影的下载链接