菜鸟日记——每天一个小实验(day1)
2017-12-04 21:27
58 查看
用R做了几天的数据分析,觉得处理数据的想法是无限的,而处理数据的手法是唯一的——always for循环(ε=(´ο`*)))唉),这样将大量的时间花费在构建循环上就会有些本末倒置,因此专门花费时间整合R语言中处理数据的利器,请让我脱离永远的for循环!!!!!!!!!!!!(本文实验是借鉴实验楼的)
强大的apply家族
R中对于复合数据的数据类型的子集进行处理的时候有它自己封装好的一套数据处理函数(apply,tapply,lapply,sapply,其中最原始的函数是apply)
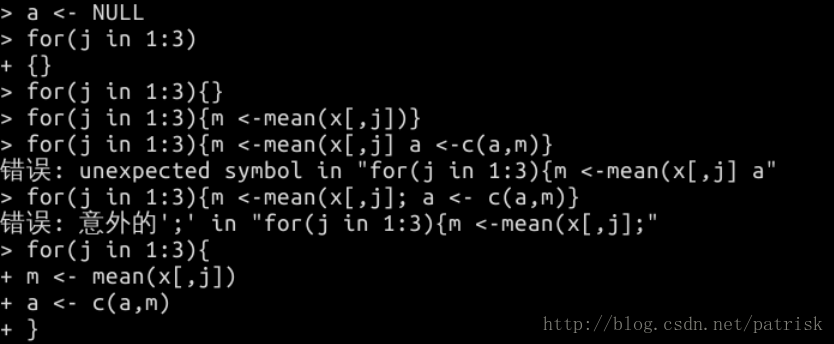
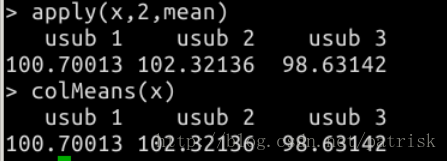
元祖函数——apply(X, MARGIN, FUN, …)经常可以用这个函数代替for和while循环:
返回通过将函数应用于数组或矩阵的边界而获得的矢量或数组或值列表。
x:待处理的数据集
MARGIN:给出函数将被应用的下标的向量。 例如,对于矩阵1表示行,2表示列,c(1,2)表示行和列。 其中X命名了dimnames,它可以是一个选择维度名称的字符向量
FUN:将要应用的函数(eg:mean(求平均),sum(求和))
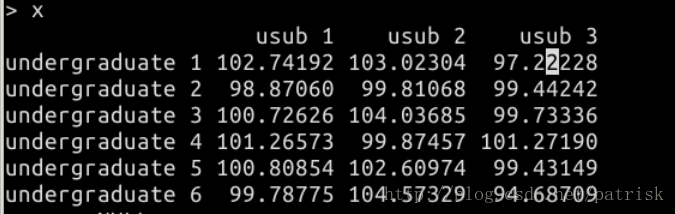
运行示例(内容来自实验楼实验截图):
实验目的是对生成的矩阵做每一列求平均值

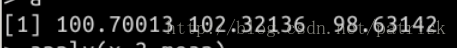
apply2.0 ——lapply(X, FUN, simplify,USE.NAMES,FUN.VALUE,n,expr,x,higher)对同一list和向量中的不同矩阵做apply
lapply返回与处理对象相同长度的列表,其中每个元素都是将FUN应用到X的对应元素的结果。lapply的包装默认返回一个vector或矩阵,或者如果simplify =“array”,则返回一个数组(如果适用的话)
X:待处理的数据集(要求一个向量(原子或列表)或一个表达式对象。 其他对象(包括分类对象)将被强制转换成list型)
FUN:要应用于X的每个元素的函数
simplify:逻辑变量,用于确定返回的数据类型,默认为true返回的是向量或者矩阵
USE.NAMES: 逻辑变量,用于确定返回的数据名称
higher:逻辑变量 如果为true,则simplify2array()将在适当的时候生成(“更高级别”)数组,而higher = FALSE将仅返回矩阵(或向量)。 这两种情况分别对应于sapply(*,simplify =“array”)或simplify = TRUE。
运行示例(截图来自实验楼实验)
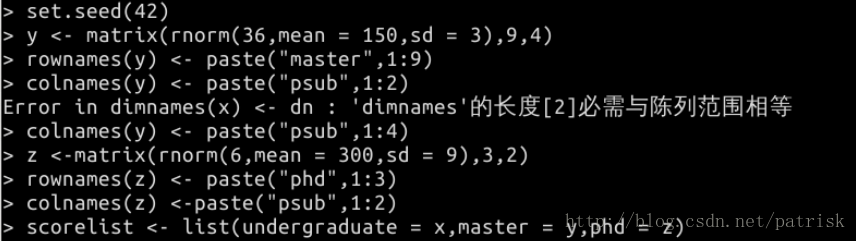
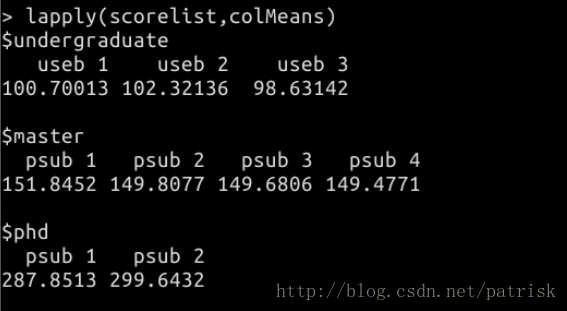
输出更简洁的sapply ——对lapply输出的结果更简洁(如果想要分组统计结果更简单的形式选它一定没错)
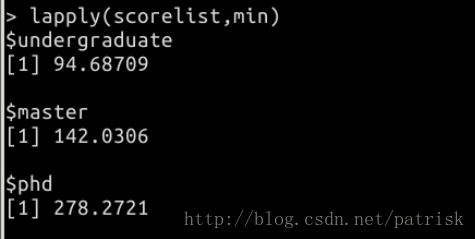

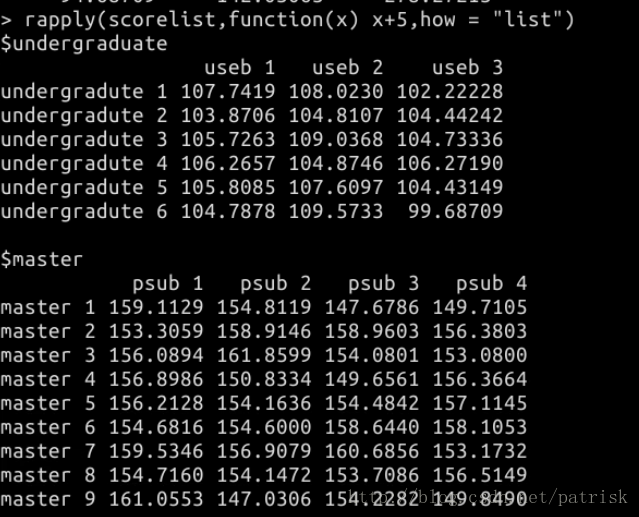
rapply是lapply的递归版本。(可以对分组中每个成员做操作,更贴心的操作照顾每个元素的感受(^▽^))
rapply(object, f, classes = “ANY”, deflt = NULL, how = c(“unlist”, “replace”, “list”), …)
object :数据类型为列表
f:一个参数的函数(即想要对数据处理的函数,一个参数是重点)
deflt:一般为默认值除非how = replace时
how:这个功能有两个基本模式。 如果how =“replace”,那么列表中不是列表的每个元素都有一个包含在类中的类被替换为将元素应用到f的结果。如果模式是how =“list”或how =“unlist”,则复制该列表,将具有类中包括的类的所有非列表元素替换为将元素应用于f的结果,并将所有其他元素替换为DEFLT。 最后,如果how =“unlist”,则在结果上调用unlist(recursive = TRUE)。
运行示例(截图来自实验楼实验结果)
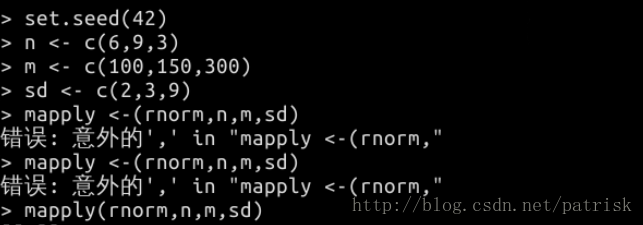
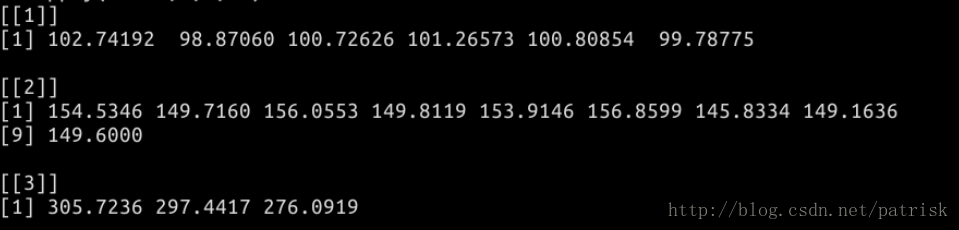
mapply——数据处理的再一次升华,可以设置处理函数的多个参数(R语言就是有这些大神的不停开发才变得如此简单,所以老用for循环是不是太不争气了)
运行示例(截图来自实验楼)
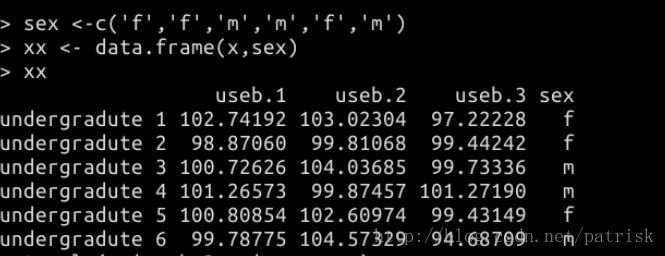
tapply——对待处理的数据按照某一列的数据进行分组,然后在分组上进行函数操作
将男女的成绩分组统计

2.1. 管道的应用
%>%(左边的值管道输出为右边函数的第一个参数)
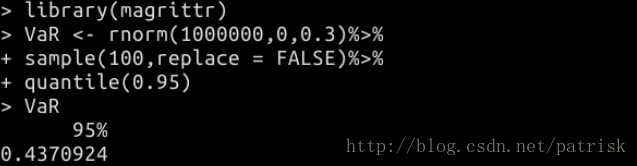
%>>%(想把前面的结果赋给后面函数的第二、三个参数或者同时赋给多个参数)
等同于
强大的apply家族
R中对于复合数据的数据类型的子集进行处理的时候有它自己封装好的一套数据处理函数(apply,tapply,lapply,sapply,其中最原始的函数是apply)
元祖函数——apply(X, MARGIN, FUN, …)经常可以用这个函数代替for和while循环:
返回通过将函数应用于数组或矩阵的边界而获得的矢量或数组或值列表。
x:待处理的数据集
MARGIN:给出函数将被应用的下标的向量。 例如,对于矩阵1表示行,2表示列,c(1,2)表示行和列。 其中X命名了dimnames,它可以是一个选择维度名称的字符向量
FUN:将要应用的函数(eg:mean(求平均),sum(求和))
运行示例(内容来自实验楼实验截图):
实验目的是对生成的矩阵做每一列求平均值
apply2.0 ——lapply(X, FUN, simplify,USE.NAMES,FUN.VALUE,n,expr,x,higher)对同一list和向量中的不同矩阵做apply
lapply返回与处理对象相同长度的列表,其中每个元素都是将FUN应用到X的对应元素的结果。lapply的包装默认返回一个vector或矩阵,或者如果simplify =“array”,则返回一个数组(如果适用的话)
X:待处理的数据集(要求一个向量(原子或列表)或一个表达式对象。 其他对象(包括分类对象)将被强制转换成list型)
FUN:要应用于X的每个元素的函数
simplify:逻辑变量,用于确定返回的数据类型,默认为true返回的是向量或者矩阵
USE.NAMES: 逻辑变量,用于确定返回的数据名称
higher:逻辑变量 如果为true,则simplify2array()将在适当的时候生成(“更高级别”)数组,而higher = FALSE将仅返回矩阵(或向量)。 这两种情况分别对应于sapply(*,simplify =“array”)或simplify = TRUE。
运行示例(截图来自实验楼实验)
输出更简洁的sapply ——对lapply输出的结果更简洁(如果想要分组统计结果更简单的形式选它一定没错)
rapply是lapply的递归版本。(可以对分组中每个成员做操作,更贴心的操作照顾每个元素的感受(^▽^))
rapply(object, f, classes = “ANY”, deflt = NULL, how = c(“unlist”, “replace”, “list”), …)
object :数据类型为列表
f:一个参数的函数(即想要对数据处理的函数,一个参数是重点)
deflt:一般为默认值除非how = replace时
how:这个功能有两个基本模式。 如果how =“replace”,那么列表中不是列表的每个元素都有一个包含在类中的类被替换为将元素应用到f的结果。如果模式是how =“list”或how =“unlist”,则复制该列表,将具有类中包括的类的所有非列表元素替换为将元素应用于f的结果,并将所有其他元素替换为DEFLT。 最后,如果how =“unlist”,则在结果上调用unlist(recursive = TRUE)。
运行示例(截图来自实验楼实验结果)
mapply——数据处理的再一次升华,可以设置处理函数的多个参数(R语言就是有这些大神的不停开发才变得如此简单,所以老用for循环是不是太不争气了)
运行示例(截图来自实验楼)
tapply——对待处理的数据按照某一列的数据进行分组,然后在分组上进行函数操作
将男女的成绩分组统计
2.1. 管道的应用
%>%(左边的值管道输出为右边函数的第一个参数)
%>>%(想把前面的结果赋给后面函数的第二、三个参数或者同时赋给多个参数)
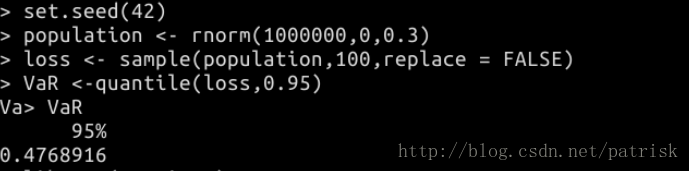
> set.seed(42) > ES <- rnorm(1000000,0,0.3)%>>% + sample(size = 100,replace = FALSE)%>>% + sort%>>% + (sum(.[length(.):round(0.95*length(.))])/(length(.)-round(0.95*length(.))))
等同于
> set.seed(42) > population <-rnorm(1000000,0,0.3) > loss <- sample(population,100,replace = FALSE) > sloss <- sort(loss) > n1 <- length(sloss) > n2 <- round(0.95*n1) > ES <- sum(sloss[n1:n2])/(n1-n2)

相关文章推荐
- 每天一个单片机小实验—LED流水灯
- 每天一个命令day1【diff 命令】(具体实例看下一节)
- 每天一个 Linux 命令(30): chown命令
- 每天一个 Linux 命令(26):用 SecureCRT 来上传和下载文件
- 每天一个小知识点8(jQuer总结二)
- 每天一个linux命令(37):date命令
- 每天一个 Linux 命令(48):watch命令
- 每天一个 Linux 命令(31): /etc/group文件详解
- log4j属性文件 每天产生一个日志文件
- 每天一个linux命令:vmstat命令
- 每天一个设计模式(5):工厂方法模式
- 每天一个linux命令:at命令
- 每天一个linux命令(54)--watch命令
- 每天一个linux命令:route命令
- 每天一个shell脚本之for&awk&less-2
- erlang中的一个List作为参数的实验记录
- 每天进步一点点------基础实验_01_多路复用器 :4通道8位带三态输出
- 每天一个 Linux 命令(32):gzip命令
- 每天一个linux命令(6):rmdir 命令
- 从HSPICE代码修改的PSPICE忆阻器仿真的一个简单实验