Caffe 工程的一些编译错误以及解决方案
2017-12-04 18:31
453 查看
以SSD代码为例,
1.主要文件夹的用途
examples/ssd/,存放了训练,测试的脚本,是主要操作的脚本
data/,存放了训练、验证和测试所需的数据和代码
python/caffe/model_libs.py,存放了生成网络主体的代码
models/,存放了Proto文件,是由 examples/ssd/中的脚本生成
jobs/,存放了训练、测试文件,是由 examples/ssd/中的脚本生成
2.
编译遇到的问题:
1. SSD代码用到protoc 3.4.0,而服务器安装caffe用的protoc 2.6.1,因此编译时不加source /home/dsp/.bashrc 命令。否则会一直出现各种 No such file or directory 错误。
2. # Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
可以通过命令 export PYTHONPATH=$CAFFE_ROOT/python:$PYTHONPATH 实现。 ($CAFFE_ROOT为该代码当前所在路径)
设置PYTHON路径方法
查看路径
3. learning@learning-virtual-machine:~/caffe$ make all 时出现问题:
learning@learning-virtual-machine:~/caffe$ make all
PROTOC src/caffe/proto/caffe.proto
CXX .build_release/src/caffe/proto/caffe.pb.cc
CXX src/caffe/data_transformer.cpp
CXX src/caffe/common.cpp
CXX src/caffe/internal_thread.cpp
CXX src/caffe/blob.cpp
CXX src/caffe/data_reader.cpp
CXX src/caffe/parallel.cpp
CXX src/caffe/util/hdf5.cpp
In file included from src/caffe/util/hdf5.cpp:1:0:
./include/caffe/util/hdf5.hpp:6:18: fatal error: hdf5.h: No such file or directory
compilation terminated.
Makefile:572: recipe for target '.build_release/src/caffe/util/hdf5.o' failed
make: *** [.build_release/src/caffe/util/hdf5.o] Error 1
learning@learning-virtual-machine:~/caffe$ 1
解决:
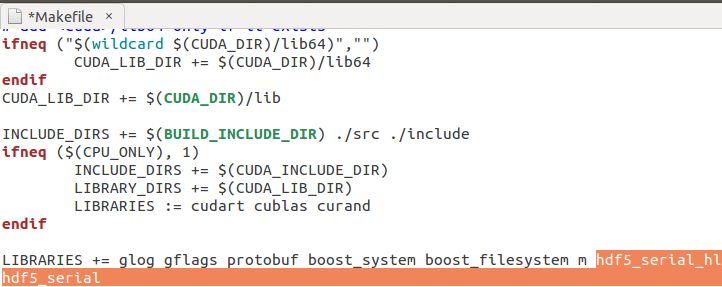
在Makefile.config文件中,
修改INCLUDE_DIRS
,添加路径 /usr/include/hdf5/serial/
在Makefile
文件中,
修改LIBRARIES
,hdf5_hl hdf5 改为 hdf5_serial_hl hdf5_serial

4. 问题:
2
3
4
5
6
7
8
9
10
首先,我是已经配置过了opencv的,可以这样查询安装版本:
因为编译好了,理所当然,输出结果是
所以出现上面的错误,应该是
2
3
二、针对VOC数据集的训练
预训练模型下载
下载地址:
链接:
在caffe/models文件夹下新建文件夹,命名为VGGNet,将刚刚下载下来的文件放入这个VGGNet文件夹当中;
下载VOC2007和VOC2012
在主文件夹下(即/home/**(服务器的名字)/)新建文件夹,命名为data;
终端输入:
2
3
4
5
解压文件:
2
3
4
5
生成训练所需的LMDB文件:
2
3
4
若出现no module named caffe或者是no module named caffe.proto,则在终端输入:
2
3. 训练与测试
- 训练:
打开caffe-ssd/examples/ssd/ssd_pascal.py这个文件,找到gpus=’0,1,2,3’这一行,如果您的服务器有一块显卡,则将123删去,如果有两个显卡,则删去23,以此类推。如果您服务器没有gpu支持,则注销以下几行,程序会以cpu形式训练。(这个是解决问题cudasuccess(10vs0)的方法)
2
3
4
5
6
7
8
9
10
11
如果出现问题cudasuccess(2vs0)则说明您的显卡计算量有限,再次打开caffe/examples/ssd/ssd_pascal.py这个文件,找到batch_size =32这一行,修改数字32,可以修改为16,或者8,甚至为4,保存后再次终端运行python examples/ssd/ssd_pascal.py。
测试
终端输入:
2
三、利用自己的数据集训练检测模型
1. 将数据集做成VOC2007格式,可参考博文(http://blog.csdn.net/ yudiemiaomiao/article/details/71635257)假定数据集名称为MyDataSet,则在MyDataSet目录下需包含Annotations、ImageSets、JPEGImages三个文件夹:

ImageSet目录下包含Main文件下,在ImageSets\Main里有四个txt文件:test.txt train.txt trainval.txt val.txt;

txt文件中的内容为图片名字(无后缀)。
在caffe-ssd/data目录下创建一个自己的文件夹MyDataSet:
2
3
把data/VOC0712目录下的create_list.sh 、create_data.sh、labelmap_voc.prototxt 这三个文件拷贝到MyDataSet下:
2
3
4
在/home/**(服务器的名字)/data目录下创建MyDataSet, 并放入自己的数据集;
在caffe-ssd/examples下创建MyDataSet文件夹:
2
用于存放后续生成的lmdb文件;
修改labelmap_voc.prototxt文件(改成自己的类别),以及create_list.sh和create_data.sh文件中的相关路径;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
运行命令:
2
3
此时,在examples/mydataset/文件夹下可以看到两个子文件夹, mydataset_trainval_lmdb, mydataset_test_lmdb;里面均包含data.dmb和lock.dmb;
到此为止,我们的数据集就做好了。接下来就开始训练了。训练程序为/examples/ssd/ssd_pascal.py,运行之前,我们需要修改相关路径代码,ssd_pascal.py作如下修改:
2
3
4
5
6
7
另外, 如果你只有一个GPU, 需要修改285行: gpus=”0,1,2,3” ===> 改为”0”
否则,训练的时候会出错。
修改完后运行
2
四、出现的错误总结
在训练的过程中,从迭代开始一直显示 mbox_loss = 0 (* 1 = 0 loss);
原因是数据集制作错误,如果使用VOC作为参考,需要严格按照其格式,包括数据类型,例如bndbox:
2
3
4
5
6
7
解决方法:
bndbox参数必须为整数,如果是小数60.0,运行时不会报错,但是训练模型不会成功,持续是loss=0。
1.主要文件夹的用途
examples/ssd/,存放了训练,测试的脚本,是主要操作的脚本
data/,存放了训练、验证和测试所需的数据和代码
python/caffe/model_libs.py,存放了生成网络主体的代码
models/,存放了Proto文件,是由 examples/ssd/中的脚本生成
jobs/,存放了训练、测试文件,是由 examples/ssd/中的脚本生成
2.
# Modify Makefile.config according to your Caffe installation. cp Makefile.config.example Makefile.config make -j8 # Make sure to include $CAFFE_ROOT/python to your PYTHONPATH. make py make test -j8 make runtest -j8
编译遇到的问题:
1. SSD代码用到protoc 3.4.0,而服务器安装caffe用的protoc 2.6.1,因此编译时不加source /home/dsp/.bashrc 命令。否则会一直出现各种 No such file or directory 错误。
2. # Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
可以通过命令 export PYTHONPATH=$CAFFE_ROOT/python:$PYTHONPATH 实现。 ($CAFFE_ROOT为该代码当前所在路径)
设置PYTHON路径方法
export PYTHONPATH=/home/username/caffe/python
查看路径
echo $PYTHONPATH
3. learning@learning-virtual-machine:~/caffe$ make all 时出现问题:
learning@learning-virtual-machine:~/caffe$ make all
PROTOC src/caffe/proto/caffe.proto
CXX .build_release/src/caffe/proto/caffe.pb.cc
CXX src/caffe/data_transformer.cpp
CXX src/caffe/common.cpp
CXX src/caffe/internal_thread.cpp
CXX src/caffe/blob.cpp
CXX src/caffe/data_reader.cpp
CXX src/caffe/parallel.cpp
CXX src/caffe/util/hdf5.cpp
In file included from src/caffe/util/hdf5.cpp:1:0:
./include/caffe/util/hdf5.hpp:6:18: fatal error: hdf5.h: No such file or directory
compilation terminated.
Makefile:572: recipe for target '.build_release/src/caffe/util/hdf5.o' failed
make: *** [.build_release/src/caffe/util/hdf5.o] Error 1
learning@learning-virtual-machine:~/caffe$ 1
解决:
在Makefile.config文件中,
修改INCLUDE_DIRS
,添加路径 /usr/include/hdf5/serial/
在Makefile
文件中,
修改LIBRARIES
,hdf5_hl hdf5 改为 hdf5_serial_hl hdf5_serial
4. 问题:
... CXX/LD -o .build_release/tools/convert_imageset.bin .build_release/lib/libcaffe.so: undefined reference to cv::imread(cv::String const&, int)’ .build_release/lib/libcaffe.so: undefined reference tocv::imencode(cv::String const&, cv::_InputArray const&, std::vector >&, std::vector > const&)’ .build_release/lib/libcaffe.so: undefined reference to `cv::imdecode(cv::_InputArray const&, int)’ collect2: error: ld returned 1 exit status make: * [.build_release/tools/convert_imageset.bin] Error 1 ...1
2
3
4
5
6
7
8
9
10
首先,我是已经配置过了opencv的,可以这样查询安装版本:
$ pkg-config --modversion opencv1
因为编译好了,理所当然,输出结果是
3.1.0
所以出现上面的错误,应该是
opencv_imgcodecs链接的问题,比较有效的解决方案是,把opencv需要的lib添加到
Makefile文件中,找到
LIBRARIES(在
PYTHON_LIBRARIES := boost_python python2.7前一行)并修改为:
LIBRARIES += glog gflags protobuf leveldb snappy \ lmdb boost_system hdf5_hl hdf5 m \ opencv_core opencv_highgui opencv_imgproc opencv_imgcodecs1
2
3
5. 问题:undefined reference tocv::VideoCapture::get(int) const’
解决:adding opencv_videoio to LIBRARIES in the Makefile
3 make
二、针对VOC数据集的训练预训练模型下载
下载地址:
链接:
http://pan.baidu.com/s/1slpaEO9密码:loxo
在caffe/models文件夹下新建文件夹,命名为VGGNet,将刚刚下载下来的文件放入这个VGGNet文件夹当中;
下载VOC2007和VOC2012
在主文件夹下(即/home/**(服务器的名字)/)新建文件夹,命名为data;
终端输入:
cd /home/**(服务器的名字)/data wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar1
2
3
4
5
解压文件:
cd /home/**(服务器的名字)/data tar -xvf VOCtrainval_11-May-2012.tar tar -xvf VOCtrainval_06-Nov-2007.tar tar -xvf VOCtest_06-Nov-2007.tar1
2
3
4
5
生成训练所需的LMDB文件:
cd /home/**(服务器的名字)/caffe-ssd ./data/VOC0712/create_list.sh ./data/VOC0712/create_data.sh1
2
3
4
若出现no module named caffe或者是no module named caffe.proto,则在终端输入:
export PYTHONPATH=$PYTHONPATH:/home/**(服务器的名字)/caffe-ssd/Python1
2
3. 训练与测试
- 训练:
打开caffe-ssd/examples/ssd/ssd_pascal.py这个文件,找到gpus=’0,1,2,3’这一行,如果您的服务器有一块显卡,则将123删去,如果有两个显卡,则删去23,以此类推。如果您服务器没有gpu支持,则注销以下几行,程序会以cpu形式训练。(这个是解决问题cudasuccess(10vs0)的方法)
#Ifnum_gpus >0: #batch_size_per_device =int(math.ceil(float(batch_size) / num_gpus)) #iter_size =int(math.ceil(float(accum_batch_size) / (batch_size_per_device * num_gpus))) #solver_mode =P.Solver.GPU #device_id =int(gpulist[0]) 保存后终端运行: cd /home/**(服务器的名字)/caffe python examples/ssd/ssd_pascal.py1
2
3
4
5
6
7
8
9
10
11
如果出现问题cudasuccess(2vs0)则说明您的显卡计算量有限,再次打开caffe/examples/ssd/ssd_pascal.py这个文件,找到batch_size =32这一行,修改数字32,可以修改为16,或者8,甚至为4,保存后再次终端运行python examples/ssd/ssd_pascal.py。
测试
终端输入:
python examples/ssd/score_ssd_pascal.py(演示detection的训练结果,数值在0.718左右)1
2
三、利用自己的数据集训练检测模型
1. 将数据集做成VOC2007格式,可参考博文(http://blog.csdn.net/ yudiemiaomiao/article/details/71635257)假定数据集名称为MyDataSet,则在MyDataSet目录下需包含Annotations、ImageSets、JPEGImages三个文件夹:
ImageSet目录下包含Main文件下,在ImageSets\Main里有四个txt文件:test.txt train.txt trainval.txt val.txt;
txt文件中的内容为图片名字(无后缀)。
在caffe-ssd/data目录下创建一个自己的文件夹MyDataSet:
cd data mkdir MyDataSet1
2
3
把data/VOC0712目录下的create_list.sh 、create_data.sh、labelmap_voc.prototxt 这三个文件拷贝到MyDataSet下:
cp VOC0712/create_list.sh MyDataSet/ cp VOC0712/create_data.sh MyDataSet/ cp VOC0712/labelmap_voc.prototxt MyDataSet/1
2
3
4
在/home/**(服务器的名字)/data目录下创建MyDataSet, 并放入自己的数据集;
在caffe-ssd/examples下创建MyDataSet文件夹:
mkdir MyDateSet1
2
用于存放后续生成的lmdb文件;
修改labelmap_voc.prototxt文件(改成自己的类别),以及create_list.sh和create_data.sh文件中的相关路径;
#labelmap_voc.prototxt需修改:
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "aeroplane"
label: 1
display_name: "person"
}
#create_list.sh需修改:
root_dir=/home/yi_miao/data/Mydataset/
...
for name in yourownset
...
#if [[ $dataset == "test" && $name == "VOC2012" ]]
# then
# continue
# fi
#create_data.sh需修改:
root_dir=/home/yi_miao/caffe-ssd
data_root_dir="/home/yi_miao/data/Mydataset"
dataset_name="Mydataset"12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
运行命令:
./data/mydataset/create_list.sh ./data/mydataset/create_data.sh1
2
3
此时,在examples/mydataset/文件夹下可以看到两个子文件夹, mydataset_trainval_lmdb, mydataset_test_lmdb;里面均包含data.dmb和lock.dmb;
到此为止,我们的数据集就做好了。接下来就开始训练了。训练程序为/examples/ssd/ssd_pascal.py,运行之前,我们需要修改相关路径代码,ssd_pascal.py作如下修改:
82行:train_data路径; 84行:test_data路径; 237-246行:model_name、save_dir、snapshot_dir、job_dir、output_result_dir路径; 259-263行:name_size_file、label_map_file路径; 266行:num_classes修改为1 + 类别数; 360行:num_test_image:测试集图片数目1
2
3
4
5
6
7
另外, 如果你只有一个GPU, 需要修改285行: gpus=”0,1,2,3” ===> 改为”0”
否则,训练的时候会出错。
修改完后运行
python ./examples/ssd/ssd_pascal.py1
2
四、出现的错误总结
在训练的过程中,从迭代开始一直显示 mbox_loss = 0 (* 1 = 0 loss);
原因是数据集制作错误,如果使用VOC作为参考,需要严格按照其格式,包括数据类型,例如bndbox:
<bndbox> <xmin>60</xmin> <ymin>27</ymin> <xmax>385</xmax> <ymax>331</ymax> </bndbox>1
2
3
4
5
6
7
解决方法:
bndbox参数必须为整数,如果是小数60.0,运行时不会报错,但是训练模型不会成功,持续是loss=0。

相关文章推荐
- Caffe 工程的一些编译错误以及解决方案
- Caffe 工程的一些编译错误以及解决方案
- Caffe 工程的一些编译错误以及解决方案(undefined reference to cv::imread)
- Caffe 工程的一些编译错误以及解决方案
- caffe安装过程中碰到的一些问题以及解决方案
- Android4.0源码编译方法以及错误解决方案
- 编译glibc(gcc)以及过程中遇到的一些错误
- [3D-Caffe]Anaconda2+CUDA8+cuDNN5+OpenCV3编译3D-Caffe中遇到各种错误的解决方案
- Qt5.7以及5.8在cmake工程中使用C++14编译遇到的问题及解决方案
- VS一些设置及编译时候的一些问题以及解决方案
- Android4.0源码编译方法以及错误解决方案
- linux系统下编译的一些有用的选项以及错误
- 汇编语言中 编译 连接 构建时的一些错误以及错误的修正方法(不断积累中...)
- R语言学习遇到的一些错误以及解决方案
- ubuntu安装anaconda各种错误和解决方案以及一些科普
- Cython的安装以及编译错误的解决方案
- 安装python caffe过程中遇到的一些问题以及对应的解决方案
- Ubuntu上编译Caffe和拓展应用(faster-rcnn, pvanet)的错误及解决方案
- caffe中编译python一些错误及其解决方法
- linux 下python3的安装与编译,以及scrapy出现sqlite3错误的解决方案