Java多线程之并发容器(五)
2017-12-04 15:42
363 查看
1.hashtable和vector
它们是支持并发操作的并发容器,hashtable只不过是在hashmap的基础上,所有的方法上都加上synchronized关键字,vector在ArrayList的基础上,所有的方法上都加上synchronized关键字来达到同步的目的。
2.Collections中的方法

这些方法实现起来也非常简单,就是包装类,把集合包装起来,重写每个方法,在每个重写方法中加入一层锁,达到同步的目的,这算不上是什么高超的技巧。
3.ConcurrentHashMap
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁。
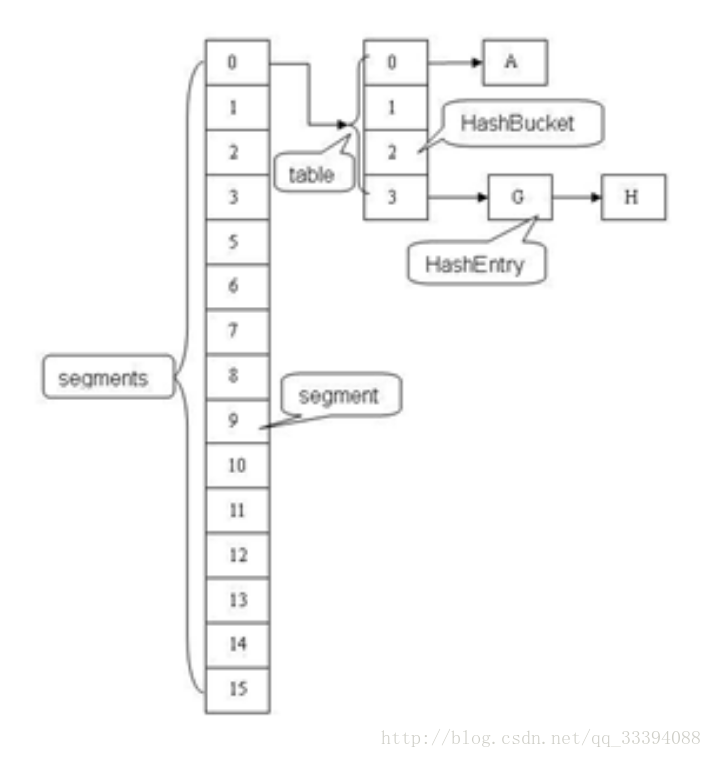
ConcurrentHashMap是由Segment数组和HashEntry数组组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。
一个ConcurrentHashMap里包含一个Segment数组,是一种链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素。
每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
应用场景
当有一个大数组时需要在多个线程共享时就可以考虑是否把它给分层多个节点了,避免大锁。并可以考虑通过hash算法进行一些模块定位。4.CopyOnWrite容器
CopyOnWrite容器也叫cow容器。如英文,它是一个写是复制的容器。当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
JDK中并没有提供CopyOnWriteMap,我们可以参考CopyOnWriteArrayList来实现一个:
import java.util.Collection;
import java.util.Map;
import java.util.Set;
public class CopyOnWriteMap<K, V> implements Map<K, V>, Cloneable {
private volatile Map<K, V> internalMap;
public CopyOnWriteMap() {
internalMap = new HashMap<K, V>();
}
public V put(K key, V value) {
synchronized (this) {
Map<K, V> newMap = new HashMap<K, V>(internalMap);
V val = newMap.put(key, value);
internalMap = newMap;
return val;
}
}
public V get(Object key) {
return internalMap.get(key);
}
public void putAll(Map<? extends K, ? extends V> newData) {
synchronized (this) {
Map<K, V> newMap = new HashMap<K, V>(internalMap);
newMap.putAll(newData);
internalMap = newMap;
}
}
}实现很简单,只要了解了CopyOnWrite机制,我们可以实现各种CopyOnWrite容器,并且在不同的应用场景中使用。

相关文章推荐
- Java多线程之并发容器:CopyOnWrite到底干啥用的
- Java 7之多线程并发容器 - ArrayBlockingQueue
- Java多线程-并发容器
- Java多线程之同步类容器与并发容器
- Java学习笔记—多线程(同步容器和并发容器)
- Java 7之多线程并发容器 - LinkedBlockingQueue
- Java 7之多线程并发容器 - ConcurrentHashMap
- Java 7之多线程并发容器 - ConcurrentHashMap
- 【多线程】Java并发编程:并发容器之CopyOnWriteArrayList(转载)
- JAVA 多线程随笔 (三) 多线程用到的并发容器 (ConcurrentHashMap,CopyOnWriteArrayList, CopyOnWriteArraySet)
- Java多线程之并发容器:CopyOnWrite到底干啥用的
- Java 7之多线程并发容器 - CopyOnWriteArrayList
- Java 7之多线程并发容器 - CopyOnWriteArrayList
- Java 容器源码分析之HashMap多线程并发问题分析
- java多线程解说【拾壹】_并发容器
- Java多线程之同步容器与并发容器
- C#转Java之路之三:多线程并发容器即线程安全的容器
- 张孝祥_Java多线程与并发库高级应用02
- Java 多线程 并发编程
- Java高并发和多线程系列 - 1. 线程基本概念