python selenium - 利用excel实现参数化
2017-12-03 19:33
627 查看
前言
在进行软件测试或设计自动化测试框架时,一个比可避免的过程就是: 参数化,在利用python进行自动化测试开发时,通常会使用excel来做数据管理,利用xlrd、xlwt开源包来读写excel。
首先在命令行下安装xlrd、xlwt
pip install xlrd
pip install xlwt
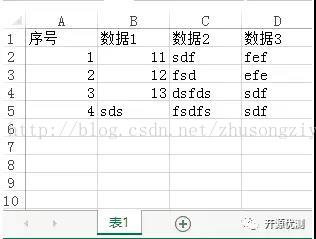
让我们先看一个简单的excel读写示例,示例代码功能,从表1中读取数据。
excel数据表如图所示
demo.xlsx
1、读取代码示例
#_*_ coding:utf-8 _*_
__author__ = '苦叶子'
import xlrd
if __name__ == '__main__':
# excel文件全路径
xlPath = "C:\\Users\\lyy\\Desktop\\demo.xlsx"
# 用于读取excel
xlBook = xlrd.open_workbook(xlPath)
# 获取excel工作簿数
count = len(xlBook.sheets())
print u"工作簿数为: ", count
# 获取 表 数据的行列数
table = xlBook.sheets()[0]
nrows = table.nrows
ncols = table.ncols
print u"表数据行列为(%d, %d)" % (nrows, ncols)
# 循环读取数据
for i in xrange(0, nrows):
rowValues = table.row_values(i) # 按行读取数据
# 输出读取的数据
for data in rowValues:
print data, " ",
print ""
运行效果如图
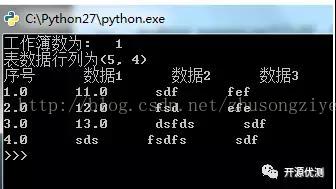
运行结果
2、写excel示例代码
#_*_ coding:utf-8 _*_
__author__ = '苦叶子'
import xlwt
import random
if __name__ == '__main__':
# 注意这里的excel文件的后缀是xls 如果是xlsx打开是会提示无效
newPath = unicode("C:\\Users\\lyy\\Desktop\\demo_new.xls", "utf8")
wtBook = xlwt.Workbook()
# 新增一个sheet
sheet = wtBook.add_sheet("sheet1", cell_overwrite_ok=True)
# 写入数据头
headList = [u'序号', u'数据1', u'数据2', u'数据3']
rowIndex = 0
col = 0
# 循环写
for head in headList:
sheet.write(rowIndex, col, head)
col = col + 1
# 写入10行 0-99的随机数据
for index in xrange(1, 11):
for col in xrange(1, 4):
data = random.randint(0,99)
sheet.write(index, 0, index) # 写序号
sheet.write(index, col, data) # 写数据
print u"写第[%d]行数据" % index
# 保存
wtBook.save(newPath)
运行结果如图
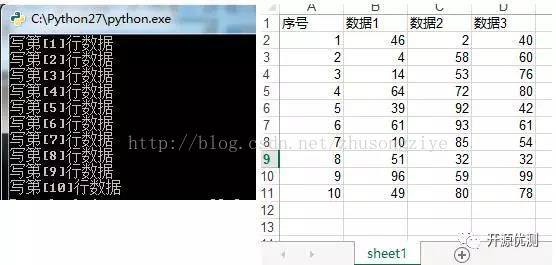
写excel结果
这里只是简单的对xlrd、xlwt模块的应用演示,对于实际做自动化测试过程中,需要封装一个通用的excel解析类,以便提高复用性和降低维护成本。
在实际应用中,我们通常需要对表格进行合并、样式设置等等系列动作,请参考官方文档,进行更深入的学习研究
python excel官网: http://www.python-excel.org/
在进行软件测试或设计自动化测试框架时,一个比可避免的过程就是: 参数化,在利用python进行自动化测试开发时,通常会使用excel来做数据管理,利用xlrd、xlwt开源包来读写excel。
环境安装
首先在命令行下安装xlrd、xlwtpip install xlrd
pip install xlwt
一个简单的读写示例
让我们先看一个简单的excel读写示例,示例代码功能,从表1中读取数据。excel数据表如图所示
demo.xlsx
1、读取代码示例
#_*_ coding:utf-8 _*_
__author__ = '苦叶子'
import xlrd
if __name__ == '__main__':
# excel文件全路径
xlPath = "C:\\Users\\lyy\\Desktop\\demo.xlsx"
# 用于读取excel
xlBook = xlrd.open_workbook(xlPath)
# 获取excel工作簿数
count = len(xlBook.sheets())
print u"工作簿数为: ", count
# 获取 表 数据的行列数
table = xlBook.sheets()[0]
nrows = table.nrows
ncols = table.ncols
print u"表数据行列为(%d, %d)" % (nrows, ncols)
# 循环读取数据
for i in xrange(0, nrows):
rowValues = table.row_values(i) # 按行读取数据
# 输出读取的数据
for data in rowValues:
print data, " ",
print ""
运行效果如图
运行结果
2、写excel示例代码
#_*_ coding:utf-8 _*_
__author__ = '苦叶子'
import xlwt
import random
if __name__ == '__main__':
# 注意这里的excel文件的后缀是xls 如果是xlsx打开是会提示无效
newPath = unicode("C:\\Users\\lyy\\Desktop\\demo_new.xls", "utf8")
wtBook = xlwt.Workbook()
# 新增一个sheet
sheet = wtBook.add_sheet("sheet1", cell_overwrite_ok=True)
# 写入数据头
headList = [u'序号', u'数据1', u'数据2', u'数据3']
rowIndex = 0
col = 0
# 循环写
for head in headList:
sheet.write(rowIndex, col, head)
col = col + 1
# 写入10行 0-99的随机数据
for index in xrange(1, 11):
for col in xrange(1, 4):
data = random.randint(0,99)
sheet.write(index, 0, index) # 写序号
sheet.write(index, col, data) # 写数据
print u"写第[%d]行数据" % index
# 保存
wtBook.save(newPath)
运行结果如图
写excel结果
结束语
这里只是简单的对xlrd、xlwt模块的应用演示,对于实际做自动化测试过程中,需要封装一个通用的excel解析类,以便提高复用性和降低维护成本。在实际应用中,我们通常需要对表格进行合并、样式设置等等系列动作,请参考官方文档,进行更深入的学习研究
python excel官网: http://www.python-excel.org/

相关文章推荐
- Selenium——selenium之利用excel实现参数化
- Selenium之利用Excel实现参数化
- Selenium之利用Excel实现参数化
- selenium自动化测试中,采用jxl实现参数化(从Excel中读取数据)
- selenium2 python自动化测试之利用AutoIt工具实现本地文件上传
- 利用selenium 3.7和python3添加cookie模拟登陆的实现
- 【提问答疑】Selenium + Python的Excel数据参数化
- python利用selenium获取cookie实现免登陆
- 利用xlrd模块实现Python读取Excel文档
- Selenium+excel实现参数化自动化测试
- selenium2 python自动化测试之利用AutoIt工具实现本地文件上传
- Selenium + Python的Excel数据参数化
- selenium利用Excel进行参数化(简单示例)
- Selenium学习三——利用Python爬取网页表格数据并存到excel
- 利用Python实现:将图片转化为Excel并保存
- Selenium学习四——利用Python爬取网页多个页面的表格数据并存到已有的excel中
- 人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
- python 利用win32com操作excel
- java操作Excel之POI(5)利用POI实现使用模板批量导出数据
- 利用Python开发实现简单的记事本