Dl4j-fit(DataSetIterator iterator)源码阅读(一)
2017-12-01 16:46
387 查看
fit(DataSetIterator iterator)源码阅读
1 网络模型
//Create the network int numInput = 1; int numOutputs = 1; int nHidden = 2; MultiLayerNetwork net = new MultiLayerNetwork(new NeuralNetConfiguration.Builder() .seed(seed) .iterations(iterations) .optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT) .learningRate(learningRate) .weightInit(WeightInit.XAVIER) .updater(Updater.SGD) //To configure: .updater(new Nesterovs(0.9)) .list() .layer(0, new DenseLayer.Builder().nIn(numInput).nOut(nHidden) .activation(Activation.RELU).dropOut(0.5) .build()) .layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.MSE) .activation(Activation.IDENTITY) .nIn(numInput).nOut(numOutputs).build()) .pretrain(false).backprop(true).build() );
调用
net.fit(iterator);对源码进行单步阅读。
2 fit(DataSetIterator iterator)
@Override
public void fit(DataSetIterator iterator) {
DataSetIterator iter;
// we're wrapping all iterators into AsyncDataSetIterator to provide background prefetch - where appropriate
if (iterator.asyncSupported()) {
iter = new AsyncDataSetIterator(iterator, 2);
} else {
iter = iterator;
}
if (trainingListeners.size() > 0) {
for (TrainingListener tl : trainingListeners) {
tl.onEpochStart(this);
}
}
if (layerWiseConfigurations.isPretrain()) {
pretrain(iter);
if (iter.resetSupported()) {
iter.reset();
}
}
if (layerWiseConfigurations.isBackprop()) {
update(TaskUtils.buildTask(iter));
if (!iter.hasNext() && iter.resetSupported()) {
iter.reset();
}
while (iter.hasNext()) {
DataSet next = iter.next();
if (next.getFeatureMatrix() == null || next.getLabels() == null)
break;
boolean hasMaskArrays = next.hasMaskArrays();
if (layerWiseConfigurations.getBackpropType() == BackpropType.TruncatedBPTT) {
doTruncatedBPTT(next.getFeatureMatrix(), next.getLabels(), next.getFeaturesMaskArray(),
next.getLabelsMaskArray());
} else {
if (hasMaskArrays)
setLayerMaskArrays(next.getFeaturesMaskArray(), next.getLabelsMaskArray());
setInput(next.getFeatureMatrix());
setLabels(next.getLabels());
if (solver == null) {
solver = new Solver.Builder().configure(conf()).listeners(getListeners()).model(this).build();
}
solver.optimize();
}
if (hasMaskArrays)
clearLayerMaskArrays();
Nd4j.getMemoryManager().invokeGcOccasionally();
}
} else if (layerWiseConfigurations.isPretrain()) {
log.warn("Warning: finetune is not applied.");
}
if (trainingListeners.size() > 0) {
for (TrainingListener tl : trainingListeners) {
tl.onEpochEnd(this);
}
}
}2.1 iterator.asyncSupported()
if (iterator.asyncSupported()) {
iter = new AsyncDataSetIterator(iterator, 2);
} else {
iter = iterator;
}这里主要判断所给的迭代器是否支持异步,如果支持异步则生成异步迭代器。一般自己实现iterator的时候,对于
asyncSupported的实现都是
return false;。
2.2 trainingListeners.size() > 0
if (trainingListeners.size() > 0) {
for (TrainingListener tl : trainingListeners) {
tl.onEpochStart(this);
}
}这个
trainingListeners字段在API文档和对应源码中没有找到对应的解释,从字面意思上是训练监听器。通常使用情况下,不涉及到这个字段
2.3 layerWiseConfigurations.isBackprop()
接下来判断神经网络是否使用Backprop,这个在神经网络的通常情况下,默认值为true。
if (layerWiseConfigurations.isBackprop()) {
update(TaskUtils.buildTask(iter));
//如果iter没有下一个元素,且iter支持reset操作
if (!iter.hasNext() && iter.resetSupported()) {
//则调用一个reset,重置迭代器。
iter.reset();
}
//当迭代器拥有元素的时候
while (iter.hasNext()) {
//调用next获取下一个批次需要训练的数据
DataSet next = iter.next();
//如果next中的特征矩阵或者标签矩阵为空的时候,则结束训练过程
if (next.getFeatureMatrix() == null || next.getLabels() == null)
break;
//判断当选训练集合是否拥有掩码(掩码通常在RNN中使用,因为RNN可能会处理非等长序列,需要使用掩码-即填0操作,使得非等长序列等长)
boolean hasMaskArrays = next.hasMaskArrays();
//这里用于判断网络架构的反向传播类型。(TruncatedBPTT这个是RNN常用的方法,截断式反向传播,BPTT- backprop through time, 主要用于解决梯度消失的问题)
if (layerWiseConfigurations.getBackpropType() == BackpropType.TruncatedBPTT) {
doTruncatedBPTT(next.getFeatureMatrix(), next.getLabels(), next.getFeaturesMaskArray(),
next.getLabelsMaskArray());
} else {
//判断掩码
if (hasMaskArrays)
setLayerMaskArrays(next.getFeaturesMaskArray(), next.getLabelsMaskArray());
//设置特征矩阵
setInput(next.getFeatureMatrix());
//设置标签
setLabels(next.getLabels());
//初始化Solver
//Sovle的类标注是Generic purpose solver。简单理解为
if (solver == null) {
//根据网络架构构造Sovler
solver = new Solver.Builder().configure(conf()).listeners(getListeners()).model(this).build();
}
solver.optimize();
}
if (hasMaskArrays)
clearLayerMaskArrays();
Nd4j.getMemoryManager().invokeGcOccasionally();
}
} else if (layerWiseConfigurations.isPretrain()) {
log.warn("Warning: finetune is not applied.");
}2.3.1 update(TaskUtils.buildTask(iter));
接下来执行update(TaskUtils.buildTask(iter));
语句。根据后面源码的阅读,这个task的建立是根据当前的网络模型对训练任务目标的确立。
首先根据传入的iter进行Task的建立。所调用的函数为
public static Task buildTask(DataSetIterator dataSetIterator) {
return new Task();
}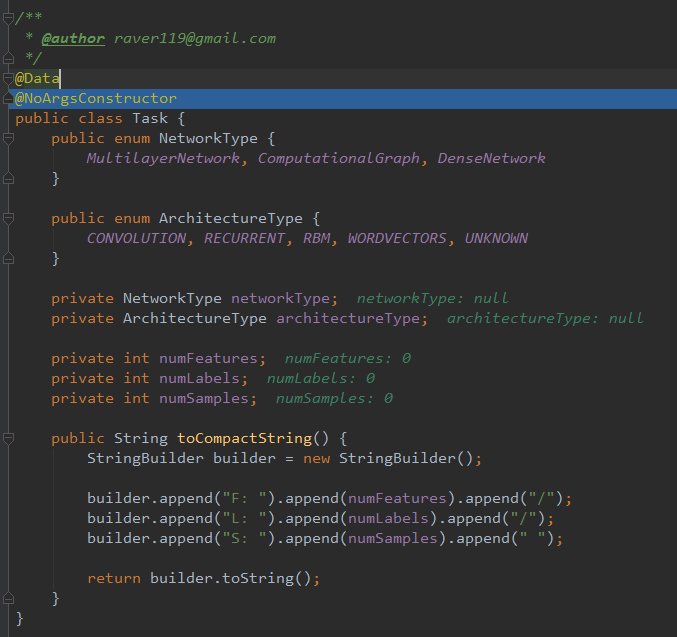
这里使用
lombok的两个注解
@Data、
@NoArgsConstructor对这个类进行标注
这时候获取的类的样式如下
Task(networkType=null, architectureType=null, numFeatures=0, numLabels=0, numSamples=0)
执行update函数
private void update(Task task) {
if (!initDone) {
//因为`initDone`初始为false,到此时,`initDone`字段改变,标识网络模型的构造完成。
initDone = true;
Heartbeat heartbeat = Heartbeat.getInstance();
//根据网络模型架构填充task类
task = ModelSerializer.taskByModel(this);
Environment env = EnvironmentUtils.buildEnvironment();
heartbeat.reportEvent(Event.STANDALONE, env, task);
}
}这里用于展开
ModelSerializer.taskByModel(this);函数,这个函数主要是根据所传入的
model的架构类型对
Task进行字段的填充。
public static Task taskByModel(Model model) {
Task task = new Task();
try {
//先对网络架构设置一个默认值。如当前网络的架构是DenseLayer不满足下列任意一个网络模型,此时就拥有一个默认的网络架构类型。
task.setArchitectureType(Task.ArchitectureType.RECURRENT);
//如果传入的model是一个自定义的计算图模型
if (model instanceof ComputationGraph) {
//设置网络结构类型
task.setNetworkType(Task.NetworkType.ComputationalGraph);
ComputationGraph network = (ComputationGraph) model;
try {
//如果网络层数大于0
if (network.getLayers() != null && network.getLayers().length > 0) {
//遍历网络层
for (Layer layer : network.getLayers()) {
//如果是RBM(受限玻尔兹曼机)
if (layer instanceof RBM
|| layer instanceof org.deeplearning4j.nn.layers.feedforward.rbm.RBM) {
task.setArchitectureType(Task.ArchitectureType.RBM);
break;
}
if (layer.type().equals(Layer.Type.CONVOLUTIONAL)) {
//如果是卷积
task.setArchitectureType(Task.ArchitectureType.CONVOLUTION);
break;
} else if (layer.type().equals(Layer.Type.RECURRENT)
|| layer.type().equals(Layer.Type.RECURSIVE)) {
//如果是循环神经网络
task.setArchitectureType(Task.ArchitectureType.RECURRENT);
break;
}
}
} else
task.setArchitectureType(Task.ArchitectureType.UNKNOWN);
} catch (Exception e) {
// do nothing here
}
} else if (model instanceof MultiLayerNetwork) {
//如果是多层网络
task.setNetworkType(Task.NetworkType.MultilayerNetwork);
MultiLayerNetwork network = (MultiLayerNetwork) model;
try {
if (network.getLayers() != null && network.getLayers().length > 0) {
for (Layer layer : network.getLayers()) {
if (layer instanceof RBM
|| layer instanceof org.deeplearning4j.nn.layers.feedforward.rbm.RBM) {
task.setArchitectureType(Task.ArchitectureType.RBM);
break;
}
if (layer.type().equals(Layer.Type.CONVOLUTIONAL)) {
task.setArchitectureType(Task.ArchitectureType.CONVOLUTION);
break;
} else if (layer.type().equals(Layer.Type.RECURRENT)
|| layer.type().equals(Layer.Type.RECURSIVE)) {
task.setArchitectureType(Task.ArchitectureType.RECURRENT);
break;
}
}
} else
task.setArchitectureType(Task.ArchitectureType.UNKNOWN);
} catch (Exception e) {
// do nothing here
}
}
return task;
} catch (Exception e) {
task.setArchitectureType(Task.ArchitectureType.UNKNOWN);
task.setNetworkType(Task.NetworkType.DenseNetwork);
return task;
}
}注:
initDone字段是
MultiLayerNetwork的一个字段。且初始值为false。
@Setter protected boolean initDone = false;
2.3.2 Solver
/**
3. Generic purpose solver
4. @author Adam Gibson
*/
public class Solver {
private NeuralNetConfiguration conf;
private Collection<IterationListener> listeners;
private Model model;
private ConvexOptimizer optimizer;
private StepFunction stepFunction;
public void optimize() {
if (optimizer == null)
optimizer = getOptimizer();
optimizer.optimize();
}
public ConvexOptimizer getOptimizer() {
if (optimizer != null)
return optimizer;
switch (conf.getOptimizationAlgo()) {
case LBFGS:
optimizer = new LBFGS(conf, stepFunction, listeners, model);
break;
case LINE_GRADIENT_DESCENT:
optimizer = new LineGradientDescent(conf, stepFunction, listeners, model);
break;
case CONJUGATE_GRADIENT:
optimizer = new ConjugateGradient(conf, stepFunction, listeners, model);
break;
case STOCHASTIC_GRADIENT_DESCENT:
optimizer = new StochasticGradientDescent(conf, stepFunction, listeners, model);
break;
default:
throw new IllegalStateException("No optimizer found");
}
return optimizer;
}
public void setListeners(Collection<IterationListener> listeners) {
this.listeners = listeners;
if (optimizer != null)
optimizer.setListeners(listeners);
}
public static class Builder {
private NeuralNetConfiguration conf;
private Model model;
private List<IterationListener> listeners = new ArrayList<>();
public Builder configure(NeuralNetConfiguration conf) {
this.conf = conf;
return this;
}
public Builder listener(IterationListener... listeners) {
this.listeners.addAll(Arrays.asList(listeners));
return this;
}
public Builder listeners(Collection<IterationListener> listeners) {
this.listeners.addAll(listeners);
return this;
}
public Builder model(Model model) {
this.model = model;
return this;
}
public Solver build() {
Solver solver = new Solver();
solver.conf = conf;
solver.stepFunction = StepFunctions.createStepFunction(conf.getStepFunction());
solver.model = model;
solver.listeners = listeners;
return solver;
}
}
}以上是对
Solver这个类的源码,接下来查看源码执行部分
solver = new Solver.Builder().configure(conf()).listeners(getListeners()).model(this).build();
首先调用
configure()、
listeners()、
model()等方法获取
MultiLayerNetwork类的配置,然后再调用
build()方法根据各种配置实例化对象
除上述之外,主要观察
stepFunction这个属性的配置。这里单步因为第一次调用的时候
conf.getStepFunction()为null, 所以
stepFunction也为null。
之后就要执行
solver.optimize()方法。

相关文章推荐
- Dl4j-fit(DataSetIterator iterator)源码阅读(七) 损失函数得分计算
- Dl4j-fit(DataSetIterator iterator)源码阅读(三)
- Dl4j-fit(DataSetIterator iterator)源码阅读(八) 根据参数更新梯度
- Dl4j-fit(DataSetIterator iterator)源码阅读(九) 利用梯度更新参数
- Dl4j-fit(DataSetIterator iterator)源码阅读(六) 反向传播部分
- Dl4j-fit(DataSetIterator iterator)源码阅读(四)dropout
- Dl4j-fit(DataSetIterator iterator)源码阅读(五)正向传播
- Dl4j-fit(DataSetIterator iterator)源码阅读(二)
- 【SeaJS】【3】seajs.data相关的源码阅读
- [hadoop源码阅读][8]-datanode-FSDataset
- Android 源码阅读第一编 AccessibilityServic包下的AccessibilityService 和 AccessibilityServiceInfo<meta-data
- [hadoop源码阅读][8]-datanode-FSDataset
- 源码阅读—Iterator接口和LIstIterator接口
- DataFrame write().jdbc实现细节(源码阅读)
- [hadoop源码阅读][8]-datanode-DataXceiver
- Java8 Iterator接口源码阅读
- [hadoop源码阅读][8]-datanode-BlockSender,BlockReceiver
- Apache mahout 源码阅读笔记--DataModel之FileDataModel
- DL4J源码阅读(六):LSTM信号前传处理流程
- Apache mahout 源码阅读笔记-DataModel之UserBaseRecommender