Python 爬虫项目示例
2017-11-28 23:59
316 查看
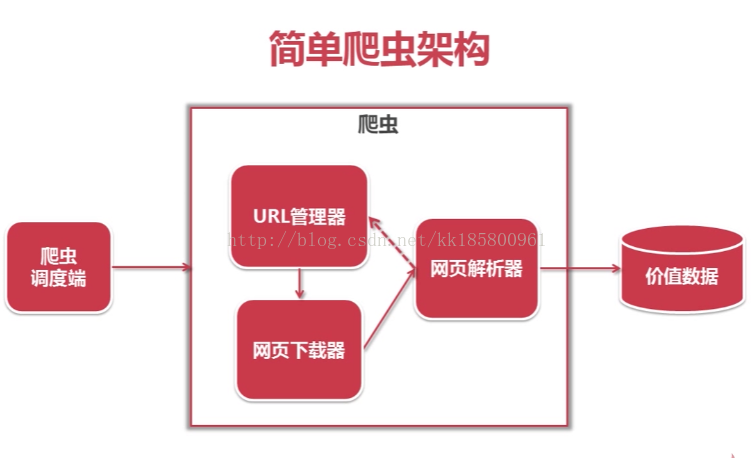
创建 python 爬虫项目,从上图左至右,创建5个类:
主类:SpiderMain
URL管理类:UrlManager
网页下载类:HtmlDownloader
网页解析类:HtmlParser
输出类:HtmlOutputer
主类:SpiderMain
# coding:utf8
from baike_spider import url_manager, html_downloader, html_parser,html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" %(count, new_url))
html_cont = self.downloader.download(new_url)
new_url, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_url)
self.outputer.collect_data(new_data)
if count == 1000:
break
count = count + 1
except:
print("craw failed")
self.outputer.output_html()
if __name__=="__main__":
root_url = "https://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
URL管理类:UrlManager
# coding:utf8
class UrlManager(object):
def __init__(self):
self.new_urls = set() #待爬取url集合
self.old_urls = set() #已爬取url集合
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载类:HtmlDownloader
# coding:utf8
import urllib.request
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
网页解析类:HtmlParser
# coding:utf8
import re
from bs4 import BeautifulSoup
import urllib.parse as urlparse
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /item/%E9%9B%86%E6%88%90%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83
links = soup.find_all('a',href=re.compile(r"/item/.*"))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_date(self, page_url, soup):
res_data = {}
#url
res_data['url'] = page_url
#<dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1>
title_node = soup.find('dd' ,class_="lemmaWgt-lemmaTitle-title").find('h1')
res_data['title'] = title_node.get_text()
#<div class="lemma-summary" label-module="lemmaSummary">
summary_node = soup.find('div' ,class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self,page_url,html_cout):
if page_url is None or html_cout is None:
return
soup = BeautifulSoup(html_cout,'html.parser')
new_urls = self._get_new_urls(page_url,soup) #当前页面的所有网址
new_data = self._get_new_date(page_url,soup) #当前页面的 title、summary
return new_urls, new_data
输出类:HtmlOutputer
# coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open('output.html','w')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data['url'])
fout.write("<td>%s</td>" % data['title'].encode('utf-8'))
fout.write("<td>%s</td>" % data['summary'].encode('utf-8'))
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")原视频教程:Python开发简单爬虫

相关文章推荐
- Python实现可获取网易页面所有文本信息的网易网络爬虫功能示例
- Python之多线程爬虫抓取网页图片的示例代码
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- Python3实现的爬虫爬取数据并存入mysql数据库操作示例
- 资源整理 |19个Python爬虫项目让你一次吃到撑
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- Python爬虫小项目(1):抓取转转网西安二手商品的详细信息并导入mongo,绘制图表,慢更
- Python开发中爬虫使用代理proxy抓取网页的方法示例
- python爬虫小项目:爬取百度贴吧图片
- [python]书籍信息爬虫示例
- python 爬虫初学项目一(80s电影网)
- python开源项目及示例代码
- Python即时网络爬虫项目启动说明详解
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(2)
- Python爬虫项目--爬取某宝男装信息
- Python爬虫开发与项目实战pdf
- Python 爬虫示例
- python爬虫框架scrapy实现模拟登录操作示例
- 基础爬虫框架及运行(选自范传辉Python爬虫开发与项目实战)