Python搜索引擎实现原理和方法
2017-11-28 09:43
417 查看
这篇文章主要介绍了Python搜索引擎实现原理和方法,并对大数据分析做了详细解释,喜欢的朋友参考一下。
如何在庞大的数据中高效的检索自己需要的东西?本篇内容介绍了Python做出一个大数据搜索引擎的原理和方法,以及中间进行数据分析的原理也给大家做了详细介绍。
布隆过滤器 (Bloom Filter)
第一步我们先要实现一个布隆过滤器。
布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素。也就是说如果一个要搜索的词并不存在与我的数据中,那么它可以以很快的速度返回目标不存在。
让我们看看以下布隆过滤器的代码:
?
基本的数据结构是个数组(实际上是个位图,用1/0来记录数据是否存在),初始化是没有任何内容,所以全部置False。实际的使用当中,该数组的长度是非常大的,以保证效率。
利用哈希算法来决定数据应该存在哪一位,也就是数组的索引
当一个数据被加入到布隆过滤器的时候,计算它的哈希值然后把相应的位置为True
当检查一个数据是否已经存在或者说被索引过的时候,只要检查对应的哈希值所在的位的True/Fasle
看到这里,大家应该可以看出,如果布隆过滤器返回False,那么数据一定是没有索引过的,然而如果返回True,那也不能说数据一定就已经被索引过。在搜索过程中使用布隆过滤器可以使得很多没有命中的搜索提前返回来提高效率。
我们看看这段 code是如何运行的:
?
结果:
?
首先创建了一个容量为10的的布隆过滤器

然后分别加入 ‘dog',‘fish',‘cat'三个对象,这时的布隆过滤器的内容如下:
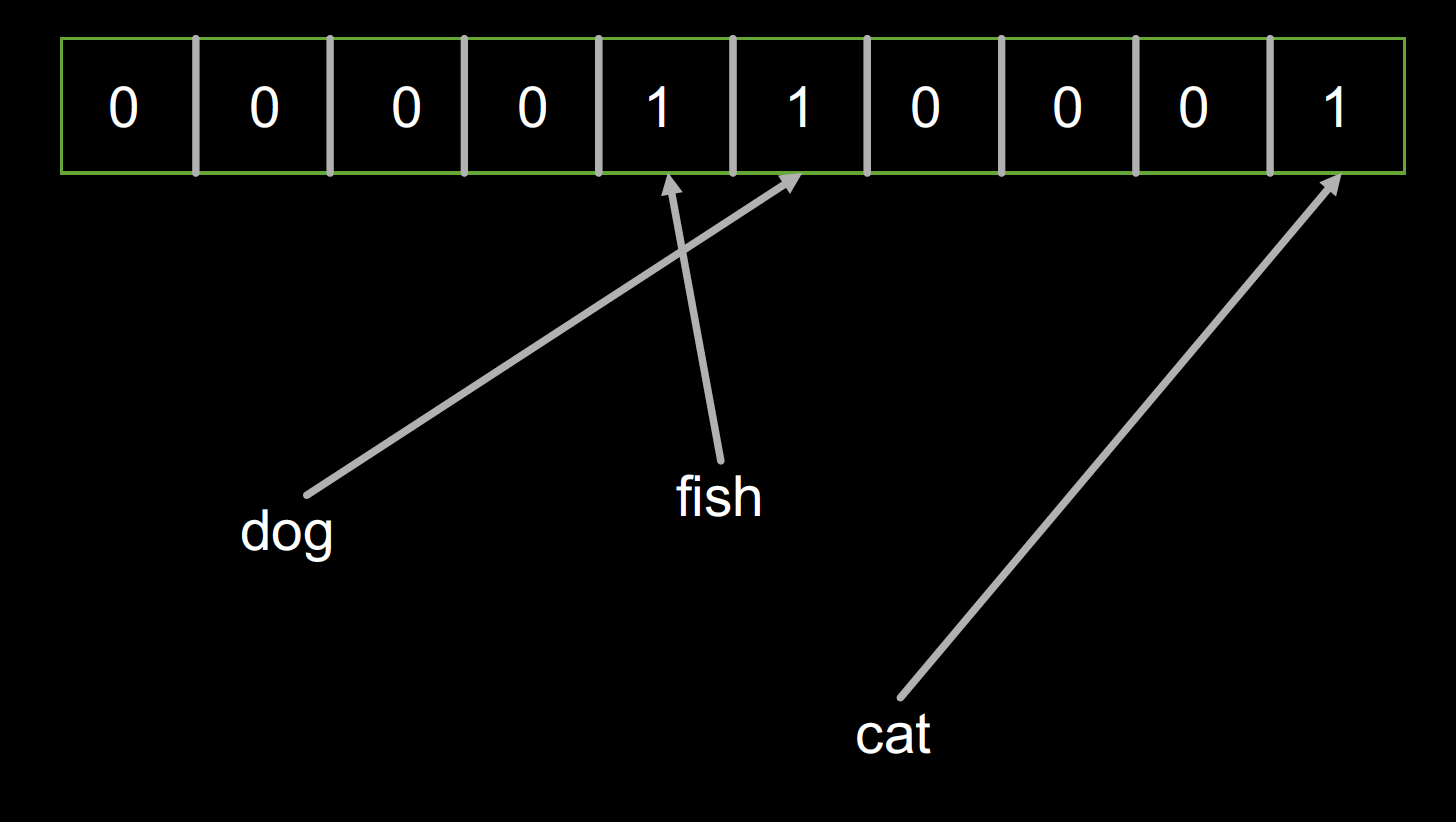
然后加入‘bird'对象,布隆过滤器的内容并没有改变,因为‘bird'和‘fish'恰好拥有相同的哈希。
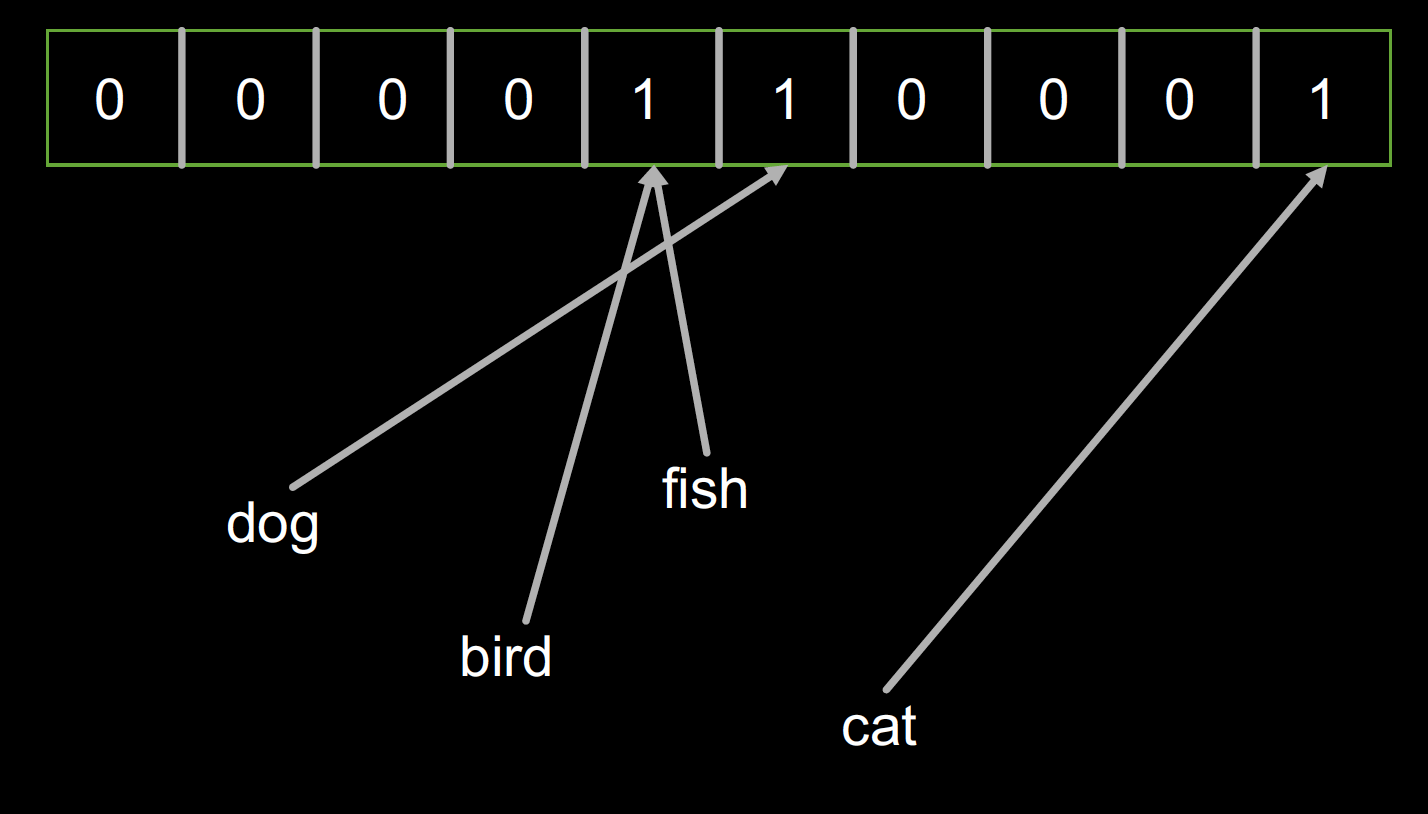
最后我们检查一堆对象('dog', ‘fish', ‘cat', ‘bird', ‘duck', 'emu')是不是已经被索引了。结果发现‘duck'返回True,2而‘emu'返回False。因为‘duck'的哈希恰好和‘dog'是一样的。

分词
下面一步我们要实现分词。 分词的目的是要把我们的文本数据分割成可搜索的最小单元,也就是词。这里我们主要针对英语,因为中文的分词涉及到自然语言处理,比较复杂,而英文基本只要用标点符号就好了。厦门叉车
下面我们看看分词的代码:
?
主要分割
主要分割使用空格来分词,实际的分词逻辑中,还会有其它的分隔符。例如Splunk的缺省分割符包括以下这些,用户也可以定义自己的分割符。
] < >( ) { } | ! ; , ‘ ” * \n \r \s \t & ? + %21 %26 %2526 %3B %7C %20 %2B %3D — %2520 %5D %5B %3A %0A %2C %28 %29
?
次要分割
次要分割和主要分割的逻辑类似,只是还会把从开始部分到当前分割的结果加入。例如“1.2.3.4”的次要分割会有1,2,3,4,1.2,1.2.3
?
分词的逻辑就是对文本先进行主要分割,对每一个主要分割在进行次要分割。然后把所有分出来的词返回。
我们看看这段 code是如何运行的:
?
?
搜索
好了,有个分词和布隆过滤器这两个利器的支撑后,我们就可以来实现搜索的功能了。
上代码:
?
Splunk代表一个拥有搜索功能的索引集合
每一个集合中包含一个布隆过滤器,一个倒排词表(字典),和一个存储所有事件的数组
当一个事件被加入到索引的时候,会做以下的逻辑
为每一个事件生成一个unqie id,这里就是序号
对事件进行分词,把每一个词加入到倒排词表,也就是每一个词对应的事件的id的映射结构,注意,一个词可能对应多个事件,所以倒排表的的值是一个Set。倒排表是绝大部分搜索引擎的核心功能。
当一个词被搜索的时候,会做以下的逻辑
检查布隆过滤器,如果为假,直接返回
检查词表,如果被搜索单词不在词表中,直接返回
在倒排表中找到所有对应的事件id,然后返回事件的内容
我们运行下看看把:
?
?
是不是很赞!
更复杂的搜索
更进一步,在搜索过程中,我们想用And和Or来实现更复杂的搜索逻辑。
上代码:
?
利用Python集合的intersection和union操作,可以很方便的支持And(求交集)和Or(求合集)的操作。
运行结果如下:
?
?
原文链接:https://www.cnblogs.com/xyou/p/7902807.html
如何在庞大的数据中高效的检索自己需要的东西?本篇内容介绍了Python做出一个大数据搜索引擎的原理和方法,以及中间进行数据分析的原理也给大家做了详细介绍。
布隆过滤器 (Bloom Filter)
第一步我们先要实现一个布隆过滤器。
布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素。也就是说如果一个要搜索的词并不存在与我的数据中,那么它可以以很快的速度返回目标不存在。
让我们看看以下布隆过滤器的代码:
?
利用哈希算法来决定数据应该存在哪一位,也就是数组的索引
当一个数据被加入到布隆过滤器的时候,计算它的哈希值然后把相应的位置为True
当检查一个数据是否已经存在或者说被索引过的时候,只要检查对应的哈希值所在的位的True/Fasle
看到这里,大家应该可以看出,如果布隆过滤器返回False,那么数据一定是没有索引过的,然而如果返回True,那也不能说数据一定就已经被索引过。在搜索过程中使用布隆过滤器可以使得很多没有命中的搜索提前返回来提高效率。
我们看看这段 code是如何运行的:
?
?
然后分别加入 ‘dog',‘fish',‘cat'三个对象,这时的布隆过滤器的内容如下:
然后加入‘bird'对象,布隆过滤器的内容并没有改变,因为‘bird'和‘fish'恰好拥有相同的哈希。
最后我们检查一堆对象('dog', ‘fish', ‘cat', ‘bird', ‘duck', 'emu')是不是已经被索引了。结果发现‘duck'返回True,2而‘emu'返回False。因为‘duck'的哈希恰好和‘dog'是一样的。
分词
下面一步我们要实现分词。 分词的目的是要把我们的文本数据分割成可搜索的最小单元,也就是词。这里我们主要针对英语,因为中文的分词涉及到自然语言处理,比较复杂,而英文基本只要用标点符号就好了。厦门叉车
下面我们看看分词的代码:
?
主要分割使用空格来分词,实际的分词逻辑中,还会有其它的分隔符。例如Splunk的缺省分割符包括以下这些,用户也可以定义自己的分割符。
] < >( ) { } | ! ; , ‘ ” * \n \r \s \t & ? + %21 %26 %2526 %3B %7C %20 %2B %3D — %2520 %5D %5B %3A %0A %2C %28 %29
?
次要分割和主要分割的逻辑类似,只是还会把从开始部分到当前分割的结果加入。例如“1.2.3.4”的次要分割会有1,2,3,4,1.2,1.2.3
?
我们看看这段 code是如何运行的:
?
好了,有个分词和布隆过滤器这两个利器的支撑后,我们就可以来实现搜索的功能了。
上代码:
?
每一个集合中包含一个布隆过滤器,一个倒排词表(字典),和一个存储所有事件的数组
当一个事件被加入到索引的时候,会做以下的逻辑
为每一个事件生成一个unqie id,这里就是序号
对事件进行分词,把每一个词加入到倒排词表,也就是每一个词对应的事件的id的映射结构,注意,一个词可能对应多个事件,所以倒排表的的值是一个Set。倒排表是绝大部分搜索引擎的核心功能。
当一个词被搜索的时候,会做以下的逻辑
检查布隆过滤器,如果为假,直接返回
检查词表,如果被搜索单词不在词表中,直接返回
在倒排表中找到所有对应的事件id,然后返回事件的内容
我们运行下看看把:
?
更复杂的搜索
更进一步,在搜索过程中,我们想用And和Or来实现更复杂的搜索逻辑。
上代码:
?
运行结果如下:
?

相关文章推荐
- Python搜索引擎实现原理和方法
- paip.编程语言方法重载实现的原理及python,php,js中实现方法重载
- python基础之继承实现原理、子类调用父类的方法、封装
- python实现随机森林random forest的原理及方法
- 机器学习之KNN算法原理及Python实现方法详解
- 朴素贝叶斯分类算法原理与Python实现与使用方法案例
- 以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
- Python堆排序原理与实现方法详解
- 若干排序算法的Python实现方法及原理
- paip.编程语言方法重载实现的原理及python,php,js中实现方法重载
- [原创]一种基于Python爬虫和Lucene检索的垂直搜索引擎的实现方法介绍
- 蒙特.卡罗方法求解圆周率近似值原理与Python实现
- LRUCache的实现原理及利用python实现的方法
- Python封装原理与实现方法详解
- python3 defaultdict使用方法与实现原理
- Python开发基础-Day20继承实现原理、子类调用父类的方法、封装
- Log信息获取调用类和调用方法名的实现原理
- 了解MmMapIoSpace以及MmUnmapIoSpace函数的实现原理以及实现方法
- python 测试实现方法
- OGC Web Map Service标准的实现原理与方法(1)