hadoop学习(二)----HDFS简介及原理
2017-11-27 11:06
393 查看
前面简单介绍了hadoop生态圈,大致了解hadoop是什么、能做什么。带着这些目的我们深入的去学习他。今天一起看一下hadoop的基石—-文件存储。因为hadoop是运行与集群之上,处于分布式环境之中,所以他的文件存储也不同与普通的本地存储,而是分布式存储系统,HDFS(The Hadoop Distributed File System)。
因为数据量越来越大,一台机器管理的磁盘数量是有限的,所有的数据由很多台机器管理。那么对于这么多台机器管理的数据如何进行协调处理呢?这个时候分布式文件管理系统就出现了。分布式文件系统是一种允许文件通过网络在多台主机上分享的 文件的系统,可让多机器上的多用户分享文件和存储空间。现有的分布式文件系统种类很多:CEPH,glusterfs,moosefs,mogilefs ,fastDFS(国人在mogileds基础上改写的),Lustre等等。我们今天要学的HDFS只是分布式文件管理系统的一种,触类旁通,学会了一种其余的都好解除。HDFS的使用场景:适用于一次写入、多次查询的情况,不支持并发写情况,小文件不合适。因为小文件也占用一个块,小文件越多(1000个1k文件)块越 多,NameNode压力越大。
我们借用官方的HDFS结构图:
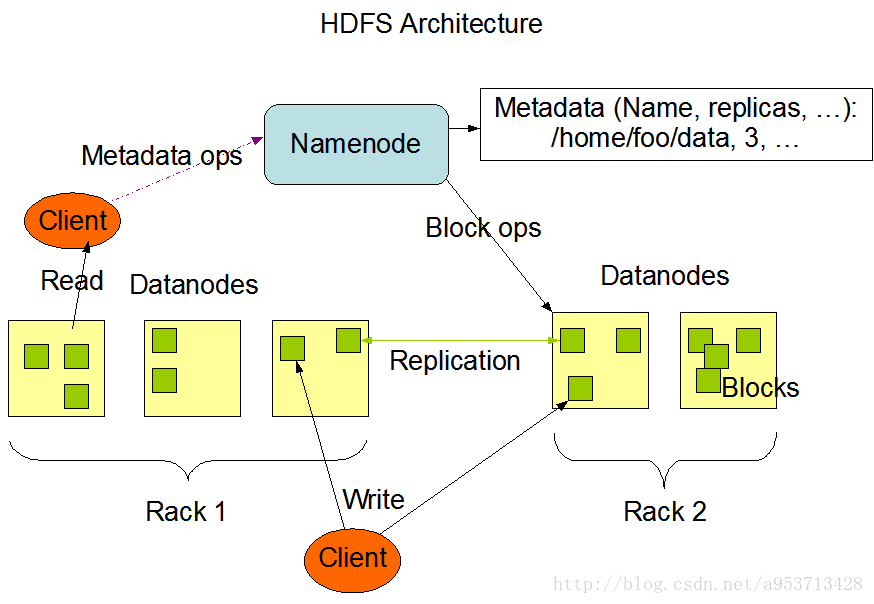
(解释一下图中的一些词:
Rack 是指机柜的意思,一个block的三个副本通常会保存到两个或者两个以上的机柜中(当然是机柜中的服务器),这样做的目的是做防灾容错,因为发生一个机柜掉电或者一个机柜的交换机挂了的概率还是蛮高的。
数据块(block):HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。从上图中看,一个文件被分成一个或多个Block,存储在一组Datanode上)
HDFS主要由三个部分组成:namenode,datanode,secondaryNamenode.
这三者的关系简单理解就是:
namenode是主人,颐指气使;
datanode是丫鬟们,为主子服务;
secondarynamenode就是那个天天跟着主人后面的太监为主子发号命令的;
下面我们分别介绍三者。
一套 是文件 目录与数据块之间的关系
另一套 是 数据块与节点之间的关系 。
前一套 数据是 静态的 ,是存放在磁盘上的, 通过fsimage和edits文件来维护 ;
后一套 数据是 动态的 ,不持久放到到磁盘的,每当集群启动的时候,会自动建立这些信息,所以一般都放在内存中。
内存的数据主要是一些元数据信息,元数据信息就像是一个索引信息,通过索引可以轻松的找到需求的数据的位置包括副本位置;元数据的存在主要是为了便于读取hdfs中的数据。
硬盘中的数据比较多,最新格式化的namenode会生成以下文件目录结构:
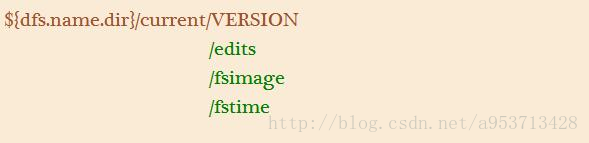
VERSION 记载了一些namenode的基础信息,其中有一个namespaceID,这是这个namenode的唯一标示。edits是hdfs的日志文件,这里记录着namenode上的一些读写操作,这是namenode储存的第一个重要的信息,它记录了近期的所有操作记录以及操作状态和操作内容.fsimage是namenode的存在内存中的元数据在硬盘上的镜像文件,但镜像文件并不是与matadata(元数据)同步的,在达到一定条件fsimage会执行更新操作来保持和内存中的元数据信息保持一致,而执行这个镜像同步操作的凭据就是edits。stime,镜像生成或者修改时间.
namenode主要涉及到的就是读和写操作,其中都比较简单(相对),写则会有一个过程,我们先看读:
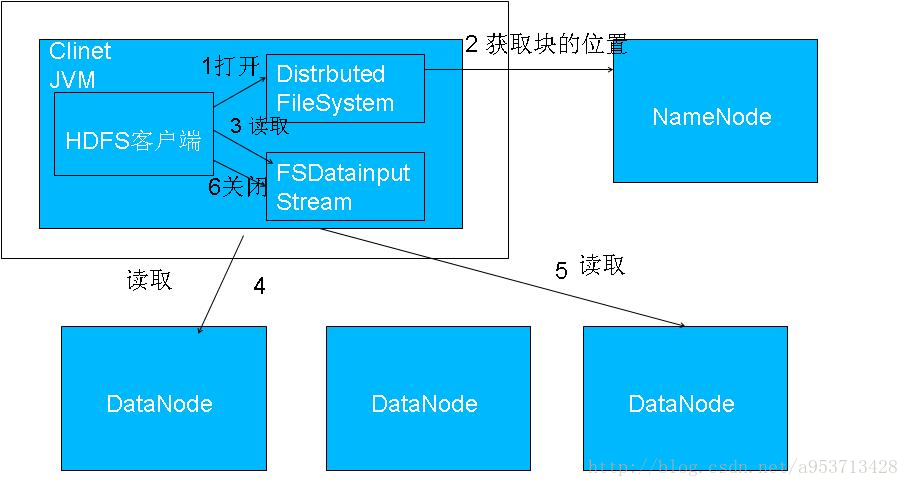
读文件过程:
1.客户端(Client)用FileSystem的open()函数打开文件。
2.DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。
对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
3.DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
4.客户端调用stream的read()函数开始读取数据。
5.DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
6.Data从数据节点读到客户端(client)
7.当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
8.当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
失败的数据节点将被记录,以后不再连接。
看来看写文件:
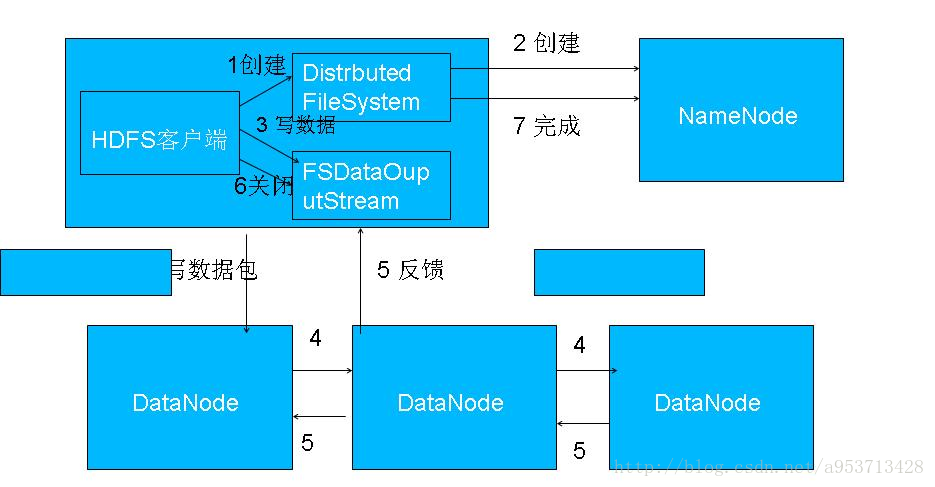
1.客户端调用create()来创建文件
2.DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
3.元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
4.DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
5.客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
6.Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
7.Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
8.DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
如果数据节点在写入的过程中失败:
1.关闭pipeline,将ack queue中的数据块放入data queue的开始。
2.当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
3.失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
4.元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
5.当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
当一个 Datanode 启动时,它会扫描本地文件系统,产生一个这些本地文件对应 的所有 HDFS 数据块的列表,然后作为报告发送到 Namenode ,这个报告就是块状态 报告。
。他的主要功能只是定期合并日志, 防止日志文件变得过大
。合并过后的镜像文件在NameNode上也会保存一份。
secondaryname作为一个附庸,其实它也一直在工作,他的工作就是解决matadata和fsimage之间的不和谐(不一致),这里为神马会使用到secondarynamenode来帮助namenode来管理namenode,原因是因为namenode不断的写,会产生大量的日志,若namenode重启,那么加载这些日志文件就会消耗大量的时间,而采用secondarynamenode处理过edits和faimage后,edits的大小始终保持一个比较小的水平,那么naemnode就算重启也可以快速启动而且保持前面的状态。
我们来看一下secondaryNameNode是如何工作的:
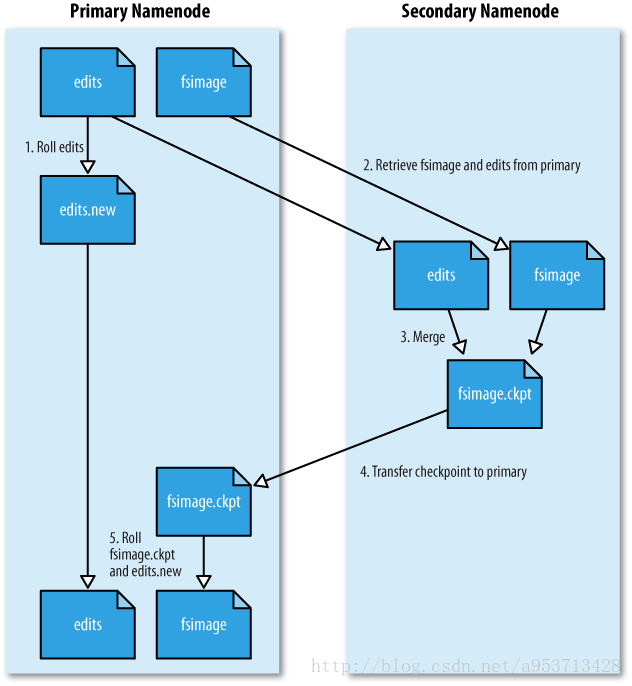
namenode 响应 Secondary namenode 请求,将 edit log 推送给 Secondary namenode , 开始重新写一个新的 edit log
Secondary namenode 收到来自 namenode 的 fsimage 文件和 edit log
Secondary namenode 将 fsimage 加载到内存,应用 edit log , 并生成一 个新的 fsimage 文件
Secondary namenode 将新的 fsimage 推送给 Namenode
Namenode 用新的 fsimage 取代旧的 fsimage , 在 fstime 文件中记下检查 点发生的时
关于hdfs的机制我们先简单介绍这么多,用多少先学多少等到后面接触的时候我们继续深入学习。
因为数据量越来越大,一台机器管理的磁盘数量是有限的,所有的数据由很多台机器管理。那么对于这么多台机器管理的数据如何进行协调处理呢?这个时候分布式文件管理系统就出现了。分布式文件系统是一种允许文件通过网络在多台主机上分享的 文件的系统,可让多机器上的多用户分享文件和存储空间。现有的分布式文件系统种类很多:CEPH,glusterfs,moosefs,mogilefs ,fastDFS(国人在mogileds基础上改写的),Lustre等等。我们今天要学的HDFS只是分布式文件管理系统的一种,触类旁通,学会了一种其余的都好解除。HDFS的使用场景:适用于一次写入、多次查询的情况,不支持并发写情况,小文件不合适。因为小文件也占用一个块,小文件越多(1000个1k文件)块越 多,NameNode压力越大。
我们借用官方的HDFS结构图:
(解释一下图中的一些词:
Rack 是指机柜的意思,一个block的三个副本通常会保存到两个或者两个以上的机柜中(当然是机柜中的服务器),这样做的目的是做防灾容错,因为发生一个机柜掉电或者一个机柜的交换机挂了的概率还是蛮高的。
数据块(block):HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。从上图中看,一个文件被分成一个或多个Block,存储在一组Datanode上)
HDFS主要由三个部分组成:namenode,datanode,secondaryNamenode.
这三者的关系简单理解就是:
namenode是主人,颐指气使;
datanode是丫鬟们,为主子服务;
secondarynamenode就是那个天天跟着主人后面的太监为主子发号命令的;
下面我们分别介绍三者。
1 namenode
NameNode的作用是 管理文件目录结构,接受用户的操作请求,是管理数据节点的。名字节点维护两套数据:一套 是文件 目录与数据块之间的关系
另一套 是 数据块与节点之间的关系 。
前一套 数据是 静态的 ,是存放在磁盘上的, 通过fsimage和edits文件来维护 ;
后一套 数据是 动态的 ,不持久放到到磁盘的,每当集群启动的时候,会自动建立这些信息,所以一般都放在内存中。
内存的数据主要是一些元数据信息,元数据信息就像是一个索引信息,通过索引可以轻松的找到需求的数据的位置包括副本位置;元数据的存在主要是为了便于读取hdfs中的数据。
硬盘中的数据比较多,最新格式化的namenode会生成以下文件目录结构:
VERSION 记载了一些namenode的基础信息,其中有一个namespaceID,这是这个namenode的唯一标示。edits是hdfs的日志文件,这里记录着namenode上的一些读写操作,这是namenode储存的第一个重要的信息,它记录了近期的所有操作记录以及操作状态和操作内容.fsimage是namenode的存在内存中的元数据在硬盘上的镜像文件,但镜像文件并不是与matadata(元数据)同步的,在达到一定条件fsimage会执行更新操作来保持和内存中的元数据信息保持一致,而执行这个镜像同步操作的凭据就是edits。stime,镜像生成或者修改时间.
namenode主要涉及到的就是读和写操作,其中都比较简单(相对),写则会有一个过程,我们先看读:
读文件过程:
1.客户端(Client)用FileSystem的open()函数打开文件。
2.DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。
对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
3.DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
4.客户端调用stream的read()函数开始读取数据。
5.DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
6.Data从数据节点读到客户端(client)
7.当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
8.当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
失败的数据节点将被记录,以后不再连接。
看来看写文件:
1.客户端调用create()来创建文件
2.DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
3.元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
4.DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
5.客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
6.Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
7.Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
8.DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
如果数据节点在写入的过程中失败:
1.关闭pipeline,将ack queue中的数据块放入data queue的开始。
2.当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
3.失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
4.元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
5.当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
2 DataNode
Datanode 将 HDFS 数据以文件的形式存储在本地的文件系统中,它并不知道有 关 HDFS 文件的信息。它把每个 HDFS 数据块存储在本地文件系统的一个单独的文件 中。 Datanode 并不在同一个目录创建所有的文件,实际上,它用试探的方法来确定 每个目录的最佳文件数目,并且在适当的时候创建子目录。在同一个目录中创建所 有的本地文件并不是最优的选择,这是因为本地文件系统可能无法高效地在单个目 录中支持大量的文件。当一个 Datanode 启动时,它会扫描本地文件系统,产生一个这些本地文件对应 的所有 HDFS 数据块的列表,然后作为报告发送到 Namenode ,这个报告就是块状态 报告。
3 Secondary NameNode
SecondaryNameNode不是说NameNode挂了的备用节点。他的主要功能只是定期合并日志, 防止日志文件变得过大
。合并过后的镜像文件在NameNode上也会保存一份。
secondaryname作为一个附庸,其实它也一直在工作,他的工作就是解决matadata和fsimage之间的不和谐(不一致),这里为神马会使用到secondarynamenode来帮助namenode来管理namenode,原因是因为namenode不断的写,会产生大量的日志,若namenode重启,那么加载这些日志文件就会消耗大量的时间,而采用secondarynamenode处理过edits和faimage后,edits的大小始终保持一个比较小的水平,那么naemnode就算重启也可以快速启动而且保持前面的状态。
我们来看一下secondaryNameNode是如何工作的:
namenode 响应 Secondary namenode 请求,将 edit log 推送给 Secondary namenode , 开始重新写一个新的 edit log
Secondary namenode 收到来自 namenode 的 fsimage 文件和 edit log
Secondary namenode 将 fsimage 加载到内存,应用 edit log , 并生成一 个新的 fsimage 文件
Secondary namenode 将新的 fsimage 推送给 Namenode
Namenode 用新的 fsimage 取代旧的 fsimage , 在 fstime 文件中记下检查 点发生的时
关于hdfs的机制我们先简单介绍这么多,用多少先学多少等到后面接触的时候我们继续深入学习。

相关文章推荐
- Hadoop 学习总结之一:HDFS简介
- Hadoop 学习总结之一:HDFS简介
- 数据、进程-云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战-by小雨
- 云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- hadoop学习记(2)--HDFS+yarn+MapReduce关系与原理
- hadoop基础学习-hdfs原理
- Hadoop 学习总结之一:HDFS简介
- 云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- Hadoop学习笔记-HDFS结构及原理
- hadoop学习笔记-HDFS原理
- 云计算学习笔记004---hadoop的简介,以及安装,用命令实现对hdfs系统进行文件的上传下载
- Hadoop 学习总结之一:HDFS简介
- Hadoop 学习总结之一:HDFS简介
- hadoop学习笔记-HDFS原理
- Hadoop 学习总结之一:HDFS简介
- Hadoop学习笔记(6)-简述分布式文件系统HDFS原理
- hadoop学习笔记-HDFS原理
- 学习Hadoop第七课(HDFS架构原理)
- 大数据学习篇:hadoop深入浅出系列之HDFS(一)——HDFS简介和优缺点
- Hadoop 学习总结之一:HDFS简介(转载)