快速排序、堆排序、归并排序简单比较
2017-11-26 11:54
295 查看
快速排序、堆排序和归并排序都是平均时间复杂度为O(nlog(n))的算法。有关其原理介绍已经有很多。今天写了个简单的实现,用JFreeChart做了个简单的性能比较。懒得保存在本地,上传一下,以供日后回看。
结果如图:
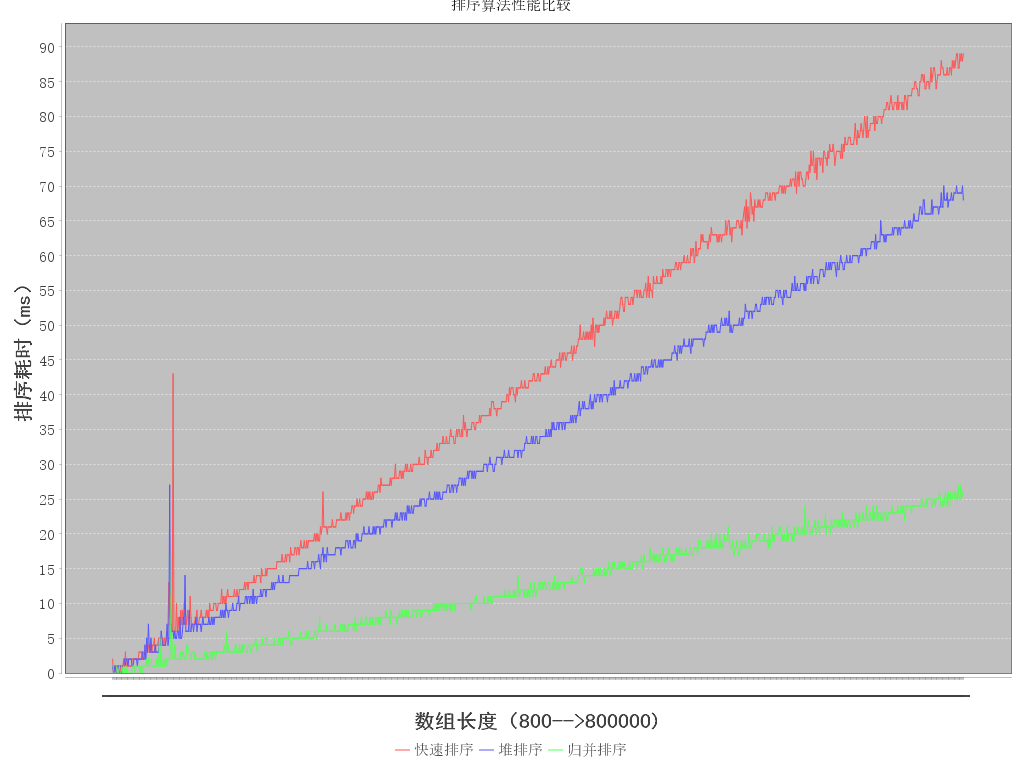
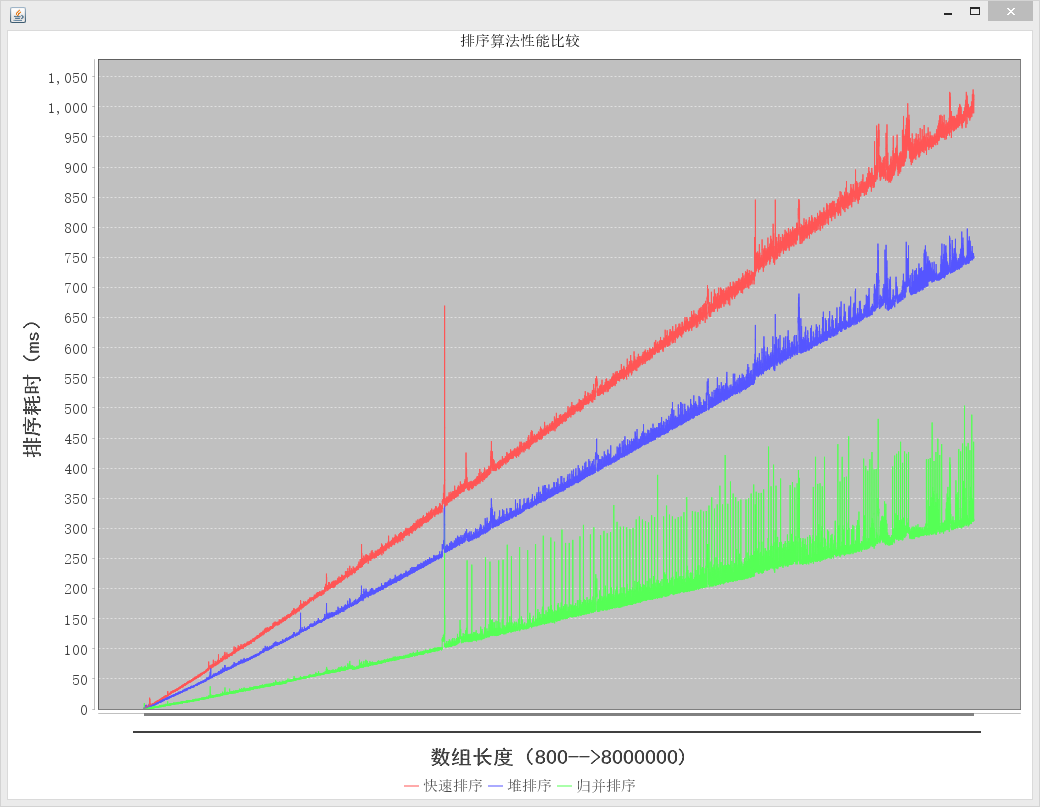
import org.jfree.chart.ChartFactory;
import org.jfree.chart.ChartFrame;
import org.jfree.chart.JFreeChart;
import org.jfree.chart.StandardChartTheme;
import org.jfree.chart.plot.CategoryPlot;
import org.jfree.data.category.DefaultCategoryDataset;
import java.awt.*;
import java.util.*;
public class Solution {
public static void main(String[] args) {
int time = 400;
StandardChartTheme mChartTheme = new StandardChartTheme("CN");
mChartTheme.setLargeFont(new Font("黑体", Font.BOLD, 20));
mChartTheme.setExtraLargeFont(new Font("宋体", Font.PLAIN, 15));
mChartTheme.setRegularFont(new Font("宋体", Font.PLAIN, 15));
ChartFactory.setChartTheme(mChartTheme);
DefaultCategoryDataset dataset = new DefaultCategoryDataset();
for (int i=0; i<time; i++) {
int len = (i+1)*800;
int scale = len*2;
int[] arr = new int[len];
for (int j=0; j<len; j++) {
arr[j] = (int)Math.floor(Math.random()*scale);
}
Calendar begin = Calendar.getInstance();
quickSort(arr, 0, len-1);
Calendar q = Calendar.getInstance();
dataset.addValue(q.getTimeInMillis()-begin.getTimeInMillis(), "快速排序", ""+len);
heapSort(arr);
Calendar h = Calendar.getInstance();
dataset.addValue(h.getTimeInMillis()-q.getTimeInMillis(), "堆排序", ""+len);
mergeSort(arr);
Calendar m = Calendar.getInstance();
dataset.addValue(m.getTimeInMillis()-h.getTimeInMillis(), "归并排序", ""+len);
}
JFreeChart chart = ChartFactory.createLineChart("排序算法性能比较","数组长度","排序耗时(ms)", dataset);
CategoryPlot plot = (CategoryPlot)chart.getPlot();
ChartFrame chartFrame = new ChartFrame("", chart);
chartFrame.pack();
chartFrame.setVisible(true);
}
/**
* 归并排序
* @param arr
*/
public static void mergeSort(int[] arr) {
int[] tmp = new int[arr.length];
divideArray(arr, 0, arr.length, tmp);
}
/**
* 将arr分成有序的
* @param arr 被divided的数组
* @param left 左边界(包含)
* @param right 右边界(不包含)
* @param tmp 存放合并信息的临时数组
*/
private static void divideArray(int[] arr, int left, int right, int[] tmp) {
if (left < right-1) { // 保证至少有两个元素
int mid = (left+right) / 2;
divideArray(arr, left, mid, tmp);
divideArray(arr, mid, right, tmp);
mergeArray(arr, left, mid, right, tmp);
}
}
/**
* 假设arr中相邻的两块[begin, first_end)和[first_end, second_end)都是分别有序的,
* 则该函数使得[begin, second_end)有序。
* @param arr 数组
* @param begin 被调整子数组的开始(包含)
* @param first_end
* @param second_end 被调整子数组的结束(不包含)
*/
public static void mergeArray(int[] arr, int begin, int first_end, int second_end, int[] tmp) {
int f_index = begin;
int s_index = first_end;
int t = 0;
while(f_index < first_end && s_index < second_end) {
if (arr[f_index] <= arr[s_index]) {
tmp[t] = arr[f_index];
f_index++;
} else {
tmp[t] = arr[s_index];
s_index++;
}
t++;
}
while(f_index<first_end) {
tmp[t] = arr[f_index];
f_index++;
t++;
}
while(s_index<second_end) {
tmp[t] = arr[s_index];
s_index++;
t++;
}
t = 0;
while (begin < second_end) {
arr[begin] = tmp[t];
begin++;
t++;
}
}
/**
* 堆排序
* @param arr
*/
public static void heapSort(int [] arr) {
int len = arr.length;
// 由于默认arr[]是无序的,所以先从最下层往上构建二叉堆。
// 从最下层往上的顺序的原因是这样可以保证每次只需要调整节点i的位置即可。
for (int i=(len-1)/2; i>=0; i--) {
heapAdjust(arr, i, len-1);
}
// 然后,循环梳理最大堆。每次梳理,都会将最大元素放到数组末尾
int end = len-1;
for (int i=0; i<len; i++) {
int tmp = arr[0];
arr[0] = arr[end];
arr[end] = tmp;
end--;
heapAdjust(arr, 0, end);
}
}
/**
* 将二叉堆调整为最大堆。
* 这个函数的假设是:arr中除了arr[parent]这个根节点以外,arr[parent]下面的直到arr[length]的子树都是最大堆。
* 所以目的是将arr[parent]的值通过在[parent, length]范围内的调整,重新梳理二叉堆。
* @param arr 二叉堆
* @param parent 需要调整的子树的根的索引值。如果是全堆调整,则该值为0.
* @param length 需要调整的子树的叶子的最大索引值。如果是全堆调整,则该值为arr.length
*/
private static void heapAdjust(int[] arr, int parent, int length) {
int top_pre = arr[parent]; // 保存临时的顶节点值
int bigger = 2*parent + 1; // parent位置元素的较大子节点的索引,默认左子节点。
while (bigger <=length) {
// 将索引值调整到左右子节点中值较大的节点上去。
if (bigger+1<=length && arr[bigger]<arr[bigger+1]) {
// 如果parent位置元素的右子节点存在,并且其值大于左子节点
bigger++; // 则将索引值调整到右节点上去。
}
// 如果根节点的值小于其左右子节点中的较大值
if (arr[bigger] <= top_pre) {
break; // 则说明顺序正确,无需调整。
} else {
// 否则,说明顺序不正确,将较大子节点的值赋给根节点
arr[parent] = arr[bigger];
// 然后将较大子节点作为根节点,较大子节点的左子节点作为较大子节点。将初始parent的值接着向下传递比较。
parent = bigger;
bigger = 2*parent+1;
}
}
// 将初始parent的值,按照最大堆的规则传递到了最深的地方。
arr[parent] = top_pre;
}
/**
* 快速排序
* @param arr
* @param left 左边起始(包含)
* @param right 右边起始(包含)
*/
public static void quickSort(int [] arr, int left, int right) {
if (left > right) {
return;
}
int i = left;
int j = right;
int base = arr[i];
while (i != j) {
// 先从右边开始找
while(arr[j]>=base && i<j) {
j--;
}
while(arr[i]<=base && i<j) {
i++;
}
// 交换位置
if (i<j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// while过后,将基准换到i的位置上,而且此时i==j
arr[left] = arr[i];
arr[i] = base;
quickSort(arr, left, i-1);
quickSort(arr, i+1, right);
}
}结果如图:

相关文章推荐
- 6种排序算法及其比较 简单选择排序,堆排序,简单插入排序,希尔排序,冒泡排序,快速排序,归并排序
- 快速排序、归并排序、堆排序三种算法性能比较
- 排序总结:插入(简单和改进)、希尔、选择、冒泡、快速、堆排序、归并排序
- 八大排序算法:简单插入排序、冒泡排序、希尔排序、快速排序、堆排序、归并排序等总结。
- 快速排序、堆排序、归并排序比较
- 比较排序总结——直接插入排序,希尔排序,选择排序,堆排序,冒泡排序,快速排序,归并排序
- 堆排序 合并排序 快速排序 简单比较
- java实现七种排序 (插入排序, 希尔排序, 插入排序, 快速排序, 简单选择排序, 堆排序, 归并排序)
- 八大排序方法汇总(选择排序,插入排序-简单插入排序、shell排序,交换排序-冒泡排序、快速排序、堆排序,归并排序,计数排序)
- 归并排序,堆排序,基数排序,希尔排序,快速排序,交换排序,选择排序和插入排序的总结和比较
- 六、内部排序综合(九种)—插入类排序(直接插入、折半插入、希尔排序);交换类排序(冒泡、快速);选择类排序(简单选择、堆排序);二路归并排序;基数排序
- 快速排序、堆排序、归并排序比较
- 快速排序-堆排序-STL中的堆排序-归并排序 》时间比较
- 几种常见的排序算法,选择排序,冒泡排序,希尔排序,堆排序,快速排序,归并排序,基数排序的比较
- 【更新】排序算法比较:插入排序,冒泡排序,归并排序,堆排序,快速排序,计数排序,基数排序,桶排序
- python排序算法-冒泡排序,选择排序,直接插入排序,希尔排序,归并排序,快速排序,堆排序
- 冒泡排序,快速排序,堆排序比较(转自:http://linpder.blog.163.com/blog/static/487641020082124532971/)
- 排序算法 快速排序 归并排序 堆排序
- C语言实现 排序源程序(包括直接插入、希尔、冒泡、快速、简单选择、堆排序)
- 选择排序,冒泡排序,归并排序,快速排序,堆排序等等