zookeeper的选主机制的实现过程以及原理
2017-11-23 23:51
162 查看
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式式应用程序可以基于它实现同步服务,配置维护和命名服务等。ZooKeeper是Hadoop的一个子项目。在分布式应用中,由于部分开发者不能很好的使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,因此需要一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。ZooKeeper目的于此。
Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
选举线程首先向所有Server发起一次询问(包括自己);
选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得N/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
综上:要使Leader获得多数Server的支持,则Server总数必须是奇数2N+1,且存活的Server的数目不得少于N+1.每个Server启动后都会重复以上流程。具体流程图如下所示:
选主机制概念
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
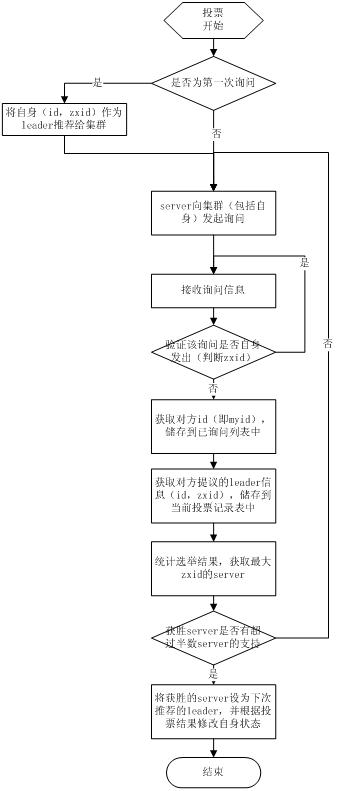
basic paxos流程
选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;选举线程首先向所有Server发起一次询问(包括自己);
选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得N/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
综上:要使Leader获得多数Server的支持,则Server总数必须是奇数2N+1,且存活的Server的数目不得少于N+1.每个Server启动后都会重复以上流程。具体流程图如下所示:
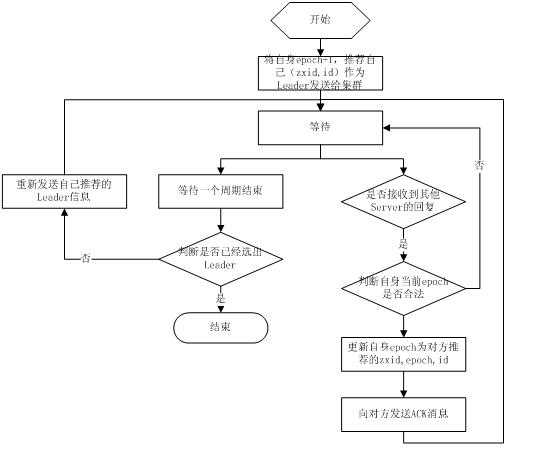
fast paxos流程
某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。其流程图如下所示:

相关文章推荐
- MySQL主从复制原理及配置详细过程以及主从复制集群自动化部署的实现
- windows程序的运行原理以及VC 的实现过程
- 微信扫一扫打印照片的原理以及实现过程(持续更新中)
- [Android开发] 在项目中快速实现 列表字母排序滑动索引 功能原理以及过程代码
- WinMain(windows程序的运行原理以及VC++的实现过程)
- 消息推送原理以及实现过程
- VC点滴 之 WinMain(windows程序的运行原理以及VC++的实现过程)
- Spring学习06--IOC实现原理以及IOC容器初始化过程
- MySQL主从复制原理及配置详细过程以及主从复制集群自动化部署的实现
- jQuery的datatable的使用例子,以及通过例子分析datatable插件的实现过程,即不但要会用,还要懂其原理
- WebSocket实现长链接原理以及和ajax轮询、long poll的对比
- dubbo学习过程、使用经验分享及实现原理简单介绍
- tomcat以及常用web容器线程池的实现原理
- 二、InnodDB和MyIsam引擎对比以及索引实现原理
- CSRF攻击原理以及nodejs的实现和防御
- 堆栈以及常用的几种堆栈实现原理
- Qt中Ui名字空间以及setupUi函数的原理和实现
- Vue实现双向绑定的原理以及响应式数据
- hadoop2.x通过Zookeeper来实现namenode的HA方案以及ResourceManager单点故障的解决方案
- redis随笔(二)----淘汰策略的原理以及实现