【图文教程】五分钟内搞一个双十一数据大屏_实时看到自己的业务访问情况
2017-11-21 14:55
363 查看
点击有惊喜
提到双十一人人都会想到天猫霸气的实时大屏。说起实时大屏,都会想到最典型的流式计算架构:
数据采集:将来自各源头数据实时采集
中间存储:利用类Kafka Queue进行生产系统和消费系统解耦
实时计算:环节中最重要环节,订阅实时数据,通过计算规则对窗口中数据进行运算
结果存储:计算结果数据存入SQL和NoSQL
可视化:通过API调用结果数据进行展示
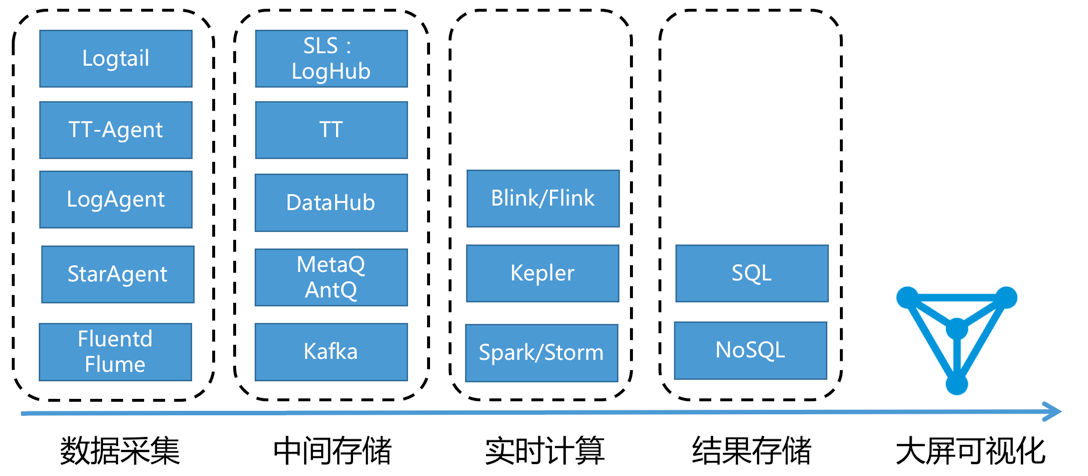
在阿里集团内,有大量成熟的产品可以完成此类工作,一般可供选型的产品如下:
除这种方案外,今天给大家介绍一种新的方法:通过日志服务(LOG,原SLS)查询分析LogSearch/Analytics API 直接对接DataV进行大屏展示。
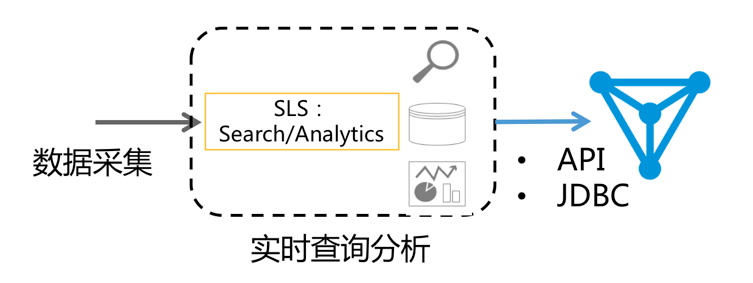
2017年9月日志服务(原SLS)加强日志实时分析功能(LogSearch/Analytics),可以使用查询+SQL92语法对日志进行实时分析。在结果分析可视化上,除了使用自带Dashboard外,还支持Grafana、Tableua(JDBC)等对接方式
计算一般根据数据量、实时性和业务需求会分为两种方式:实时计算(流计算)、离线计算(数据仓库+离线计算),日志服务(原SLS)对实时采集数据提供两种方式对接。
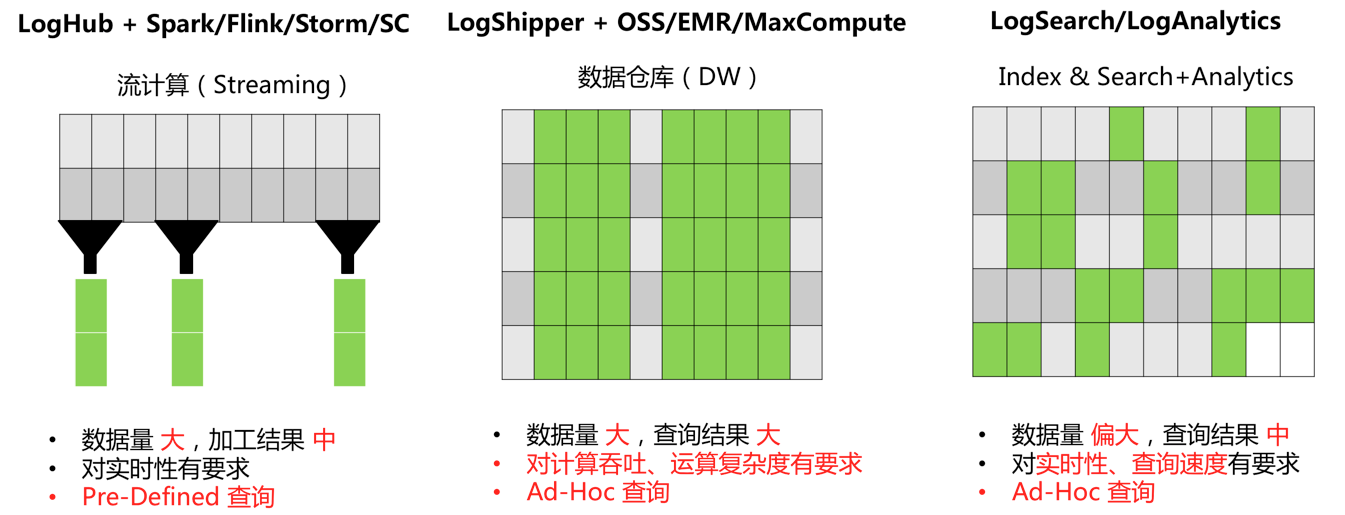
除此之外,对于数据量偏大,对实时性有要求的日志分析场景,我们提供实时索引LogHub中数据机制,之后可通过LogSearch/Anlaytics直接进行查询分析。这种方法好处是什么:
快速:API传入Query立马拿到结果,无需等待和预计算结果
实时:日志产生到反馈大屏99.9%情况下1秒内
动态:无论修改统计方法、补数据能立马刷新结果,不需要等待重新计算
当然没有一个计算系统是万能的,这种方式限制如下:
数据量:单次计算数据量在百亿以下,超过需要限定时间段
计算灵活度:目前计算限于SQL92语法,不支持自定义UDF
云栖大会期间有个临时需求,统计线上(网站)在全国各地访问量。由于之前采集全量日志数据并且在日志服务中打开了查询分析,所以只要写一个查询分析Query即可。以统计UV为例子:我们对所有访问日志中nginx下forward字段获取10月11日到目前唯一计数:
线上已跑了1天需求变更了,只需要统计yunqi这个域名下的数据。我们增加了一个过滤条件(host),立马拿到结果:
后来发现Nginx访问日志中有多个IP情况,默认情况下只要第一个ip即可,在查询中对Query进行处理
到第三天接到需求,针对访问计算中需要把uc中广告访问去掉,于是我们加上一个过滤条件(not …)既马上算到最新结果:

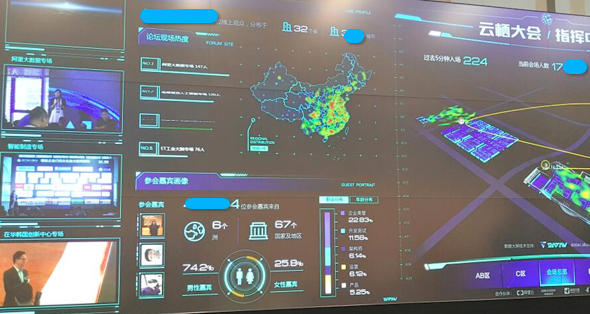
最后大屏效果如下:
主要分3个步骤:
数据采集,参考文档
索引设置 与控制台查询,参考索引设置与可视化,或最佳实践中网站日志分析案例
对接DataV插件,将实时查询SQL转化为视图
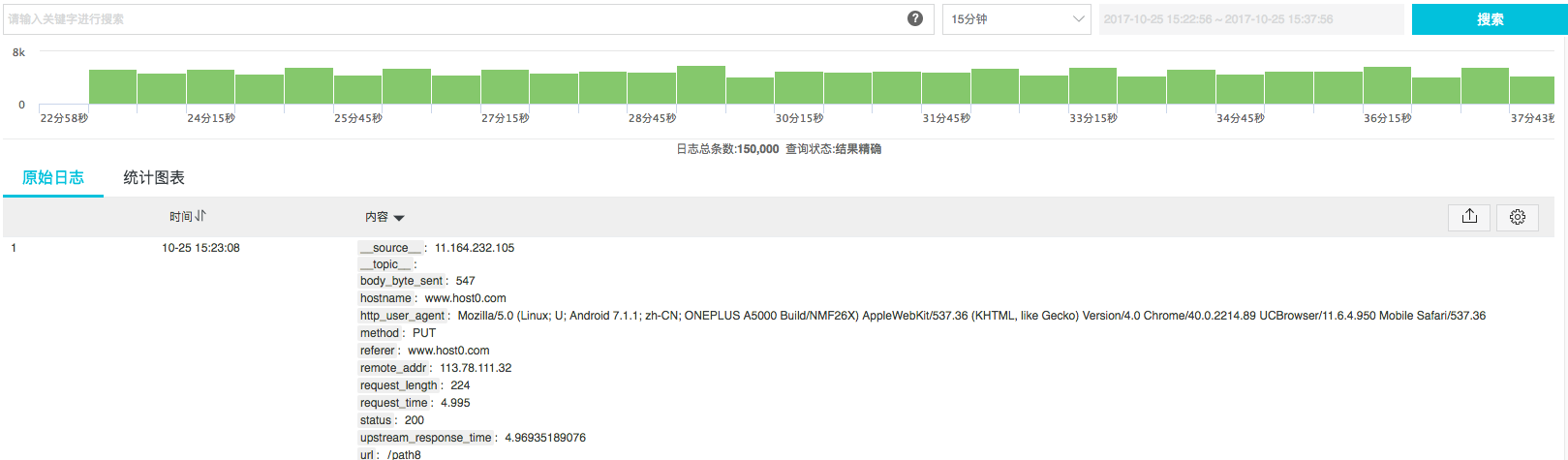
我们主要演示步骤3,在做完1、2步骤后,在查询页面可以看到原始日志:
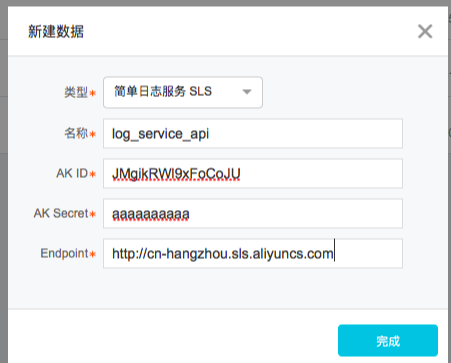
类型指定『简单日志服务-SLS』
名称自定义
AK ID和AK Secret填写主账号,或者有权限读取日志服务的子帐号的AK。
Endpoint填写 日志服务的project所在region的地址。图中为杭州的region地址。
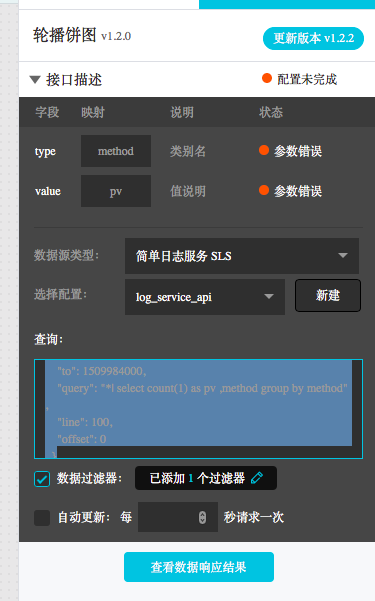
创建一个折线图,在折线图的数据配置中,数据源类型选择『简单日志服务-SLS』,然后选择刚刚创建的数据源『log_service_api』在查询中输入参数。
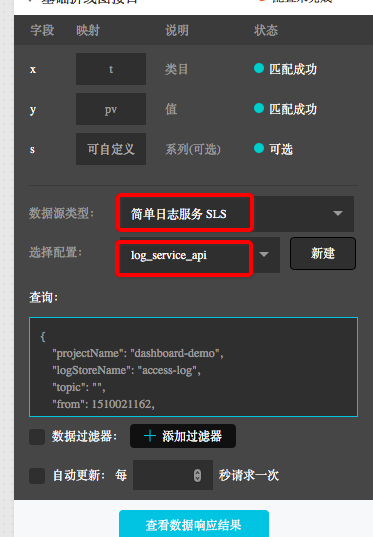
查询参数样例如下:
projectName填写自己的project。
logstoreName填写日志的logstore。
from和to分别是日志的起始和结束时间。
注意,上文的我们填写的是:from和:to。 在测试时,可以先填写unix time,例如1509897600。等发布之后,换成:from和:to这种形式,然后我们可以在url参数里控制这两个数值的具体时间范围。例如,预览是的url是
打开
query填写查询的条件,query的语法参考分析语法文档。样例中是展示每分钟的pv数。 query中的时间格式,一定要是2017/07/11 12:00:00这种,所以采用date_format(from_unixtime(date_trunc('hour',__time__)
) ,'%Y/%m/%d %H:%i:%s') 把时间对齐到整点,再转化成目标格式。
其他参数采用默认值。
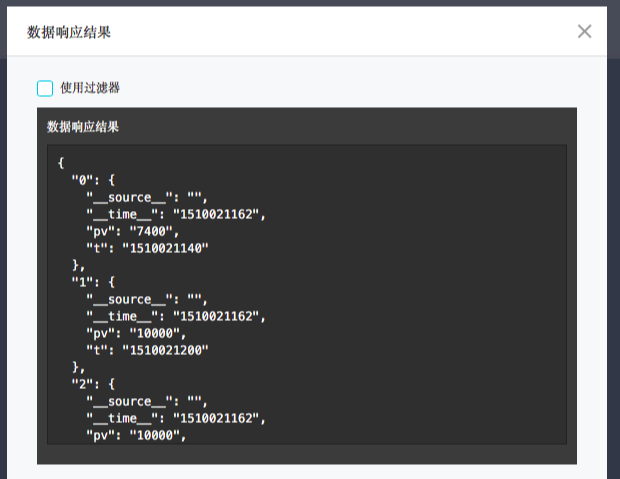
配置完成后,点击『查看数据响应结果』:
点击上方『使用过滤器』,然后新建一个过滤器:
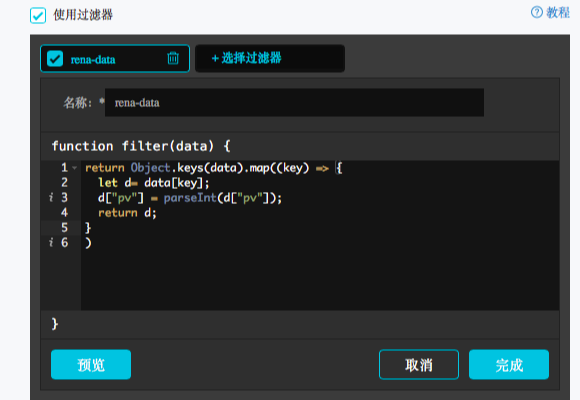
过滤器内容填写:
在过滤器中,要把y轴用到的结果变成int类型,上述样例中,y轴是pv,所以需要转换pv列。
能看到在结果中有t和pv两列,那么我们在x轴配置为t,y轴配置成pv。
点击有惊喜

提到双十一人人都会想到天猫霸气的实时大屏。说起实时大屏,都会想到最典型的流式计算架构:
数据采集:将来自各源头数据实时采集
中间存储:利用类Kafka Queue进行生产系统和消费系统解耦
实时计算:环节中最重要环节,订阅实时数据,通过计算规则对窗口中数据进行运算
结果存储:计算结果数据存入SQL和NoSQL
可视化:通过API调用结果数据进行展示
在阿里集团内,有大量成熟的产品可以完成此类工作,一般可供选型的产品如下:
除这种方案外,今天给大家介绍一种新的方法:通过日志服务(LOG,原SLS)查询分析LogSearch/Analytics API 直接对接DataV进行大屏展示。
2017年9月日志服务(原SLS)加强日志实时分析功能(LogSearch/Analytics),可以使用查询+SQL92语法对日志进行实时分析。在结果分析可视化上,除了使用自带Dashboard外,还支持Grafana、Tableua(JDBC)等对接方式
两种方式差别
计算一般根据数据量、实时性和业务需求会分为两种方式:实时计算(流计算)、离线计算(数据仓库+离线计算),日志服务(原SLS)对实时采集数据提供两种方式对接。除此之外,对于数据量偏大,对实时性有要求的日志分析场景,我们提供实时索引LogHub中数据机制,之后可通过LogSearch/Anlaytics直接进行查询分析。这种方法好处是什么:
快速:API传入Query立马拿到结果,无需等待和预计算结果
实时:日志产生到反馈大屏99.9%情况下1秒内
动态:无论修改统计方法、补数据能立马刷新结果,不需要等待重新计算
当然没有一个计算系统是万能的,这种方式限制如下:
数据量:单次计算数据量在百亿以下,超过需要限定时间段
计算灵活度:目前计算限于SQL92语法,不支持自定义UDF
实际案例:不断调整统计口径下实时大屏
云栖大会期间有个临时需求,统计线上(网站)在全国各地访问量。由于之前采集全量日志数据并且在日志服务中打开了查询分析,所以只要写一个查询分析Query即可。以统计UV为例子:我们对所有访问日志中nginx下forward字段获取10月11日到目前唯一计数:* | select approx_distinct(forward) as uv
线上已跑了1天需求变更了,只需要统计yunqi这个域名下的数据。我们增加了一个过滤条件(host),立马拿到结果:
host:yunqi.aliyun.com | select approx_distinct(forward) as uv
后来发现Nginx访问日志中有多个IP情况,默认情况下只要第一个ip即可,在查询中对Query进行处理
host:yunqi.aliyun.com | select approx_distinct(split_part(forward,',',1)) as uv
到第三天接到需求,针对访问计算中需要把uc中广告访问去掉,于是我们加上一个过滤条件(not …)既马上算到最新结果:
host:yunqi.aliyun.com not url:uc-iflow | select approx_distinct(split_part(forward,',',1)) as uv
最后大屏效果如下:
使用说明:SLS对接DataV
主要分3个步骤:数据采集,参考文档
索引设置 与控制台查询,参考索引设置与可视化,或最佳实践中网站日志分析案例
对接DataV插件,将实时查询SQL转化为视图
我们主要演示步骤3,在做完1、2步骤后,在查询页面可以看到原始日志:
创建dataV数据源
类型指定『简单日志服务-SLS』
名称自定义
AK ID和AK Secret填写主账号,或者有权限读取日志服务的子帐号的AK。
Endpoint填写 日志服务的project所在region的地址。图中为杭州的region地址。
创建一个折线图
创建一个折线图,在折线图的数据配置中,数据源类型选择『简单日志服务-SLS』,然后选择刚刚创建的数据源『log_service_api』在查询中输入参数。查询参数样例如下:
{
"projectName": "dashboard-demo",
"logStoreName": "access-log",
"topic": "",
"from": ":from",
"to": ":to",
"query": "*| select approx_distinct(remote_addr) as uv ,count(1) as pv , date_format(from_unixtime(date_trunc('hour',__time__) ) ,'%Y/%m/%d %H:%i:%s') as time group by date_trunc('hour',__time__) order by time limit 1000" ,
"line": 100,
"offset": 0
}projectName填写自己的project。
logstoreName填写日志的logstore。
from和to分别是日志的起始和结束时间。
注意,上文的我们填写的是:from和:to。 在测试时,可以先填写unix time,例如1509897600。等发布之后,换成:from和:to这种形式,然后我们可以在url参数里控制这两个数值的具体时间范围。例如,预览是的url是
http://datav.aliyun.com/screen/86312,
打开
http://datav.aliyun.com/screen/86312?from=1510796077&to=1510798877后,会按照指定的时间进行计算。
query填写查询的条件,query的语法参考分析语法文档。样例中是展示每分钟的pv数。 query中的时间格式,一定要是2017/07/11 12:00:00这种,所以采用date_format(from_unixtime(date_trunc('hour',__time__)
) ,'%Y/%m/%d %H:%i:%s') 把时间对齐到整点,再转化成目标格式。
其他参数采用默认值。
配置完成后,点击『查看数据响应结果』:
点击上方『使用过滤器』,然后新建一个过滤器:
过滤器内容填写:
return Object.keys(data).map((key) => {
let d= data[key];
d["pv"] = parseInt(d["pv"]);
return d;
}
)在过滤器中,要把y轴用到的结果变成int类型,上述样例中,y轴是pv,所以需要转换pv列。
能看到在结果中有t和pv两列,那么我们在x轴配置为t,y轴配置成pv。
配置一个饼状图
点击有惊喜

相关文章推荐
- 【图文教程】五分钟内搞一个双十一数据大屏_实时看到自己的业务访问情况
- 【图文教程】五分钟内搞一个双十一数据大屏_实时看到自己的业务访问情况
- 使SQL用户只能看到自己拥有权限的库(图文教程)
- oracle授权另外一个用户访问自己创建的数据对象
- 最近项目中有遇到报表数据入库的情况,数据量说大不大,说小又赖得自己手动敲!于是自己动手写了一个入库的,下面直接上代码,如有同样的,请联系我删除此文
- oracle授权另外一个用户访问自己创建的数据对象
- 使SQL用户只能看到自己拥有权限的库(图文教程)
- 原因分析如下: 遇到这种情况,很有可能是把一个int型业务数据的 设置setText()或者类似的方法中, 这样Android系统就会主动去资源文件当中寻找, 但是它不是一个资源文件ID, 所
- oracle授权另外一个用户访问自己创建的数据对象
- 看到人问CSDN的采用了什么架构,能够承受这么多访问,就回复了个,这里把自己的的经验也发下,算是给。NET新手一个帮助
- oracle授权另外一个用户访问自己创建的数据对象
- 如何将Oracle的一个大数据表快速迁移到 Sqlserver2008数据库(图文教程)
- Scott Mitchell 的ASP.NET 2.0数据教程之二:创建一个业务逻辑层
- 硬盘只剩下一个大分区数据恢复图文教程
- 一个轻client,多语言支持,去中心化,自己主动负载,可扩展的实时数据写服务的实现方案讨论
- 【数据实时分析】流计算使用教程
- 自己编写一个简单的ActiveX控件——详尽教程
- Scott Mitchell 的ASP.NET 2.0数据教程之62:创建一个用户自定义的Database-Driven Site Map Provider
- 架设自己的FTP服务器 Serv-U详细配置图文教程[推荐]
- Android基础入门教程——6.3.1 数据存储与访问之——初见SQLite数据库