机器学习PLA&Pocket algorithm实现(python)
2017-11-19 21:52
225 查看
1. PLA&Pocket algorithm
在机器学习中,感知机(Perceptron)是二分类的线性分类模型,属于监督学习算法。对于线性可分数据集可以直接使用PLA进行分类,且最终一定可以找到一个最优分类超平面将数据完全分开;有关感知机收敛性证明可以参考李航老师的《统计学习方法》或者这篇博客,感知机的python实现可以参考这里。下两幅图来自台大林轩田老师的机器学习基石课程,分别为PLA算法和PLA算法的实施步骤。

本篇博客主要研究利用pocket algorithm对线性不可分数据集进行简单分类:对于线性不可分数据集,PLA算法将会一直运行下去(在不设置迭代次数等其他停止条件下),这时我们可以使用Pocket
algorithm.(一种改进的PLA 算法),算法流程如下:

2. python实现
2.1 数据集
数据集:http://pan.baidu.com/s/1bVDV3K
2.2 代码实现
【注】以下代码可以实现PLA和Pocket algprithm
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2017/11/18 20:47
# @Author : Z.C.Wang
# @Email : iwangzhengchao@gmail.com
# @File : pocket_algorithm.py
# @Software: PyCharm Community Edition
"""
Description :
pocket algorithm
"""
import time
import numpy as np
import matplotlib.pyplot as plt
# load data from DataSet.txt
data_set = []
data_label = []
file = open('DataSet.txt')
# file = open('DataSet_linear_separable.txt')
for line in file:
line = line.split('\t')
for i in range(len(line)):
line[i] = float(line[i])
data_set.append(line[0:2])
data_label.append(int(line[-1]))
file.close()
data = np.array(data_set)
for i in range(len(data_label)):
if data_label[i] != 1:
data_label[i] = -1
label = np.array(data_label)
# Initialize w, b, alpha
w = np.array([0.5, 1])
b = 0
alpha = 0.4
trainLoss = []
# Calculate train_loss
f = (np.dot(data, w.T) + b) * label
idx = np.where(f <= 0)
train_loss = -np.sum((np.dot(data[idx], w.T) + b) * label[idx]) / (np.sqrt(w[0]**2+w[1]**2))
trainLoss.append(train_loss)
# iteration
max_iter = 500
iteration = 1
start = time.time()
while iteration <= max_iter:
if f[idx].size == 0:
break
for sample in data[idx]:
i = 0
w += alpha * sample * label[idx[0][i]]
b += alpha * label[idx[0][i]]
i += 1
print('Iteration:%d w:%s b:%s' % (iteration, w, b))
f = (np.dot(data, w.T) + b) * label
idx = np.where(f <= 0)
train_loss = -np.sum((np.dot(data[idx], w.T) + b) * label[idx]) / (np.sqrt(w[0] ** 2 + w[1] ** 2))
trainLoss.append(train_loss)
iteration = iteration + 1
if f[idx].size == 0:
accuracy = 100
else:
accuracy = len(f[idx]) / len(label) * 100
end = time.time()
print('Pocket learning algorithm is over')
print('train time is %f s.' % (end - start))
print('-'*50)
print('min trainLoss: %f' % np.min(trainLoss))
print('Classification accuracy: %.2f%%' % accuracy)
# draw
x1 = np.arange(-4, 5, 0.1)
x2 = (w[0] * x1 + b) / (-w[1])
idx_p = np.where(label == 1)
idx_n = np.where(label != 1)
data_p = data[idx_p]
data_n = data[idx_n]
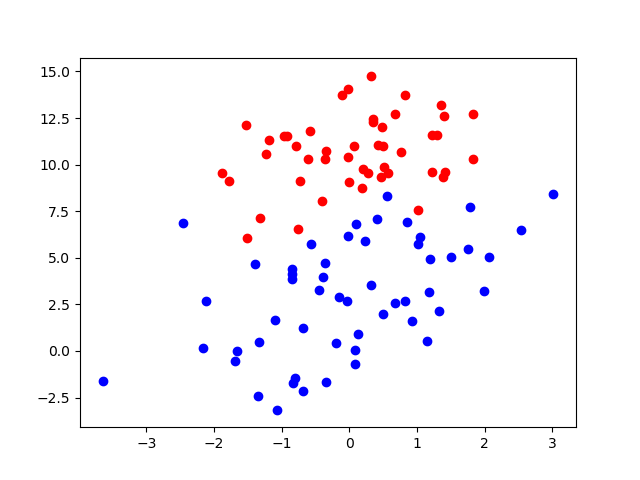
plt.figure()
plt.scatter(data_p[:, 0], data_p[:, 1], color='b')
plt.scatter(data_n[:, 0], data_n[:, 1], color='r')
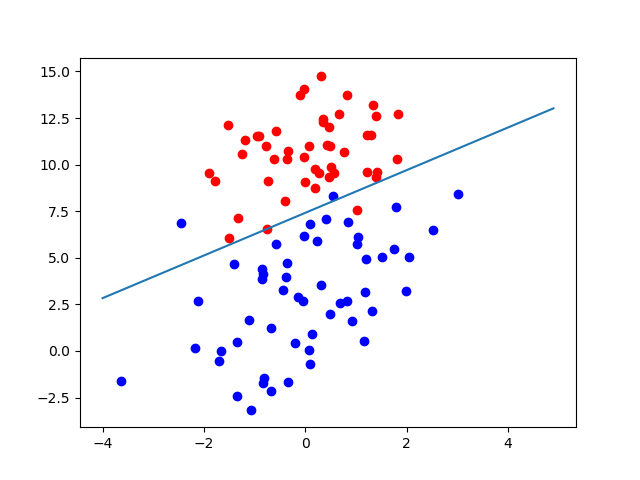
plt.plot(x1, x2)
plt.show()
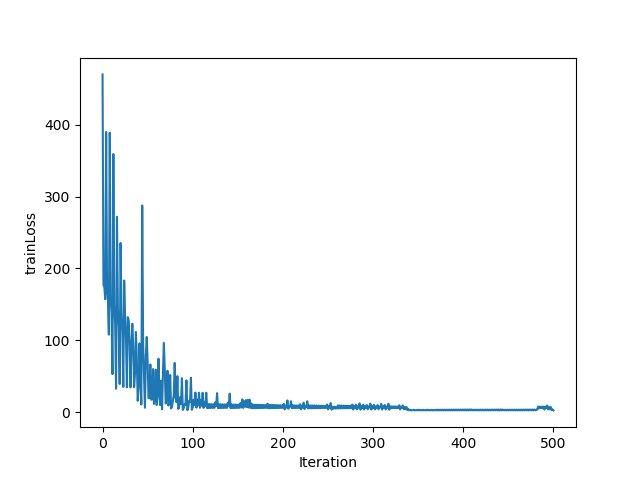
plt.figure()
plt.plot(trainLoss)
plt.ylabel('trainLoss')
plt.xlabel('Iteration')
plt.show()2.3 运行结果Iteration:498 w:[ 79.2537332 -64.189894 ] b:508.4 Iteration:499 w:[ 79.0104068 -80.1653084] b:506.4 Iteration:500 w:[ 78.4516652 -68.5393232] b:508.0 Pocket learning algorithm is over train time is 0.177006 s. -------------------------------------------------- min trainLoss: 2.323198 Classification accuracy: 4.00%

相关文章推荐
- 机器学习-感知机python实现
- 用shell & Python 封装 Hive SQL 实现类Store Procedure 功能
- 机器学习经典算法详解及Python实现--CART分类决策树、回归树和模型树
- Python语言实现机器学习的K-近邻算法
- Python实现机器学习--实现多元线性回归
- python机器学习实战2:实现决策树
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
- 推荐一个机器学习框架——python实现
- 机器学习---Logistic回归数学推导以及python实现
- 用Python Scikit-learn 实现机器学习十大算法--朴素贝叶斯算法(文末有代码)
- 纯python实现机器学习之kNN算法示例
- 利用Python分析GP服务运行结果的输出路径 & 实现服务输出路径的本地化
- 小白学习机器学习---第三章(3):二分类LDA的python实现
- Python&Auto.js:实现蚂蚁森林自动收能量(懒人的高效生活)
- 机器学习专题(一)——KNN算法的python实现
- 机器学习基石 作业1 实现PLA和Pocket算法
- 机器学习决策树及python实现
- python3与机器学习实践---2、KNN实现手写数字识别
- PLA算法python实现
- python机器学习之神经网络实现