散布矩阵(scatter_matrix)及相关系数(correlation coefficients)实例分析
2017-11-19 12:01
996 查看
在进行机器学习建模之前,需要对数据进行分析,判断各特征(属性,维度)的数据分布及其之间的关系成为十分必要的环节,本文利用Pandas和Numpy的散布矩阵函数及相关系数函数对数据集特征及其关系进行实例分析。
各参数如下:
frame:(DataFrame),DataFrame对象
alpha:(float, 可选), 图像透明度,一般取(0,1]
figsize: ((float,float), 可选),以英寸为单位的图像大小,一般以元组 (width, height) 形式设置
ax:(Matplotlib axis object, 可选),一般取None
diagonal:({‘hist’, ‘kde’}),必须且只能在{‘hist’, ‘kde’}中选择1个,’hist’表示直方图(Histogram plot),’kde’表示核密度估计(Kernel Density Estimation);该参数是scatter_matrix函数的关键参数,下文将做进一步介绍
marker:(str, 可选), Matplotlib可用的标记类型,如’.’,’,’,’o’等
density_kwds:(other plotting keyword arguments,可选),与kde相关的字典参数
hist_kwds:(other plotting keyword arguments,可选),与hist相关的字典参数
range_padding:(float, 可选),图像在x轴、y轴原点附近的留白(padding),该值越大,留白距离越大,图像远离坐标原点
kwds:(other plotting keyword arguments,可选),与scatter_matrix函数本身相关的字典参数
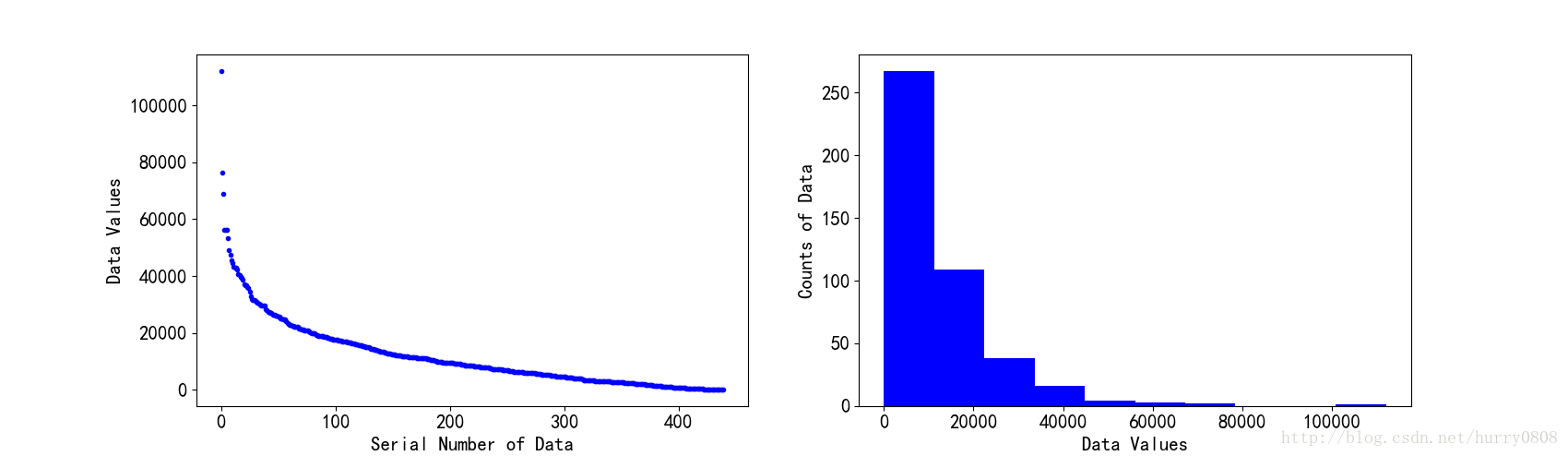
例如有1维整型数组,共有元素440个,按照值从大至小的顺序排列后,其散布图与直方图如下所示:
以相同的1维整型数组为例,使用Gaussian Kernel Density估计得到的密度函数如下所示:

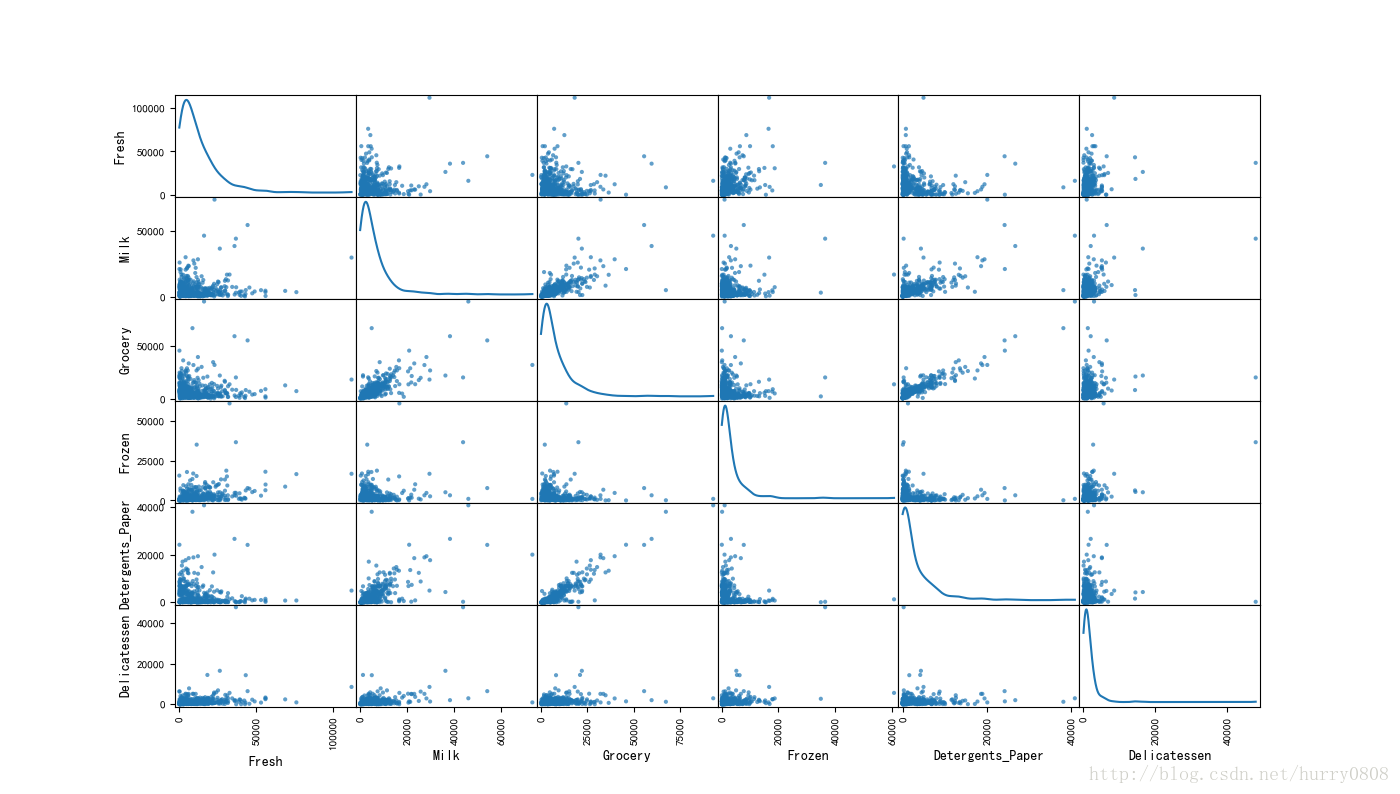
在上文介绍diagonal参数取’hist’、’kde’值时,绘图所用数据为Fresh列数据;从图中可以看出,单列数据绘制的密度函数曲线与本图左上角第1个子图一致。
图中对角线上的子图均为经高斯核密度估计后的密度函数曲线,scatter_matrix函数源码中对应部分如下:
散布矩阵图呈对称结构,除对角上的密度函数图之外,其他子图分别显示了不同特征列之间的关联关系,如Grocery与Detergents_Paper之间、Grocery与Milk之间、Milk与Detergents_Paper之间近似成线性关系,说明该些特征之间关联性很强;相反地,其他各特征列之间的散布状态比较杂乱,基本无规律可循,说明各特征之间的关联性不强。
分析数据集各特征(列)之间的关系时,散布矩阵能以图形的形式“定性”给出各特征之间的关系,如要进一步“定量”分析,则需要使用相关系数。
Numpy中的计算相关系数的函数为:
各参数如下:
x:(array_like),包含多个特征和值的1维或2维数组,每行表示一个特征,每列表示各特征的取值,以行为依据计算各特征之间的相关系数
y:(array_like,可选),一组额外的特征和值,数组形状与x相同
rowvar:(bool, 可选),该值为True时,每行表示1个特征,各列表式各特征的取值;该值为False时,每列表示1个特征,各行表式各特征的取值;默认情况下为True
bias:(_NoValue,可选),无效果,从1.10.0版本后废止
ddof :(_NoValue,可选),无效果,从1.10.0版本后废止

该图形也为对称结构,依据相关系数的计算式,其对角线上的相关系数为1;子图颜色越接近绿色表示相关系数越接近1,特征相关性越强且为正相关,子图颜色接近另一个极端(-1)时,特征之间相关性也很强且为负相关;本例相关系数最小值为-0.132,蓝色最浓的子图即为该值,0处的颜色表示特征之间不相关(相关系数为0)。
从图中可以看出,Grocery与Detergents_Paper特征相关性最强,Grocery与Milk、Milk与Detergents_Paper特征之间也有较强相关性,其余各特征之间相关性较弱、甚至不相关,该结论与散布矩阵图得出的结论一致。
散布矩阵(scatter_matrix)
Pandas中散布矩阵的函数原型为:def scatter_matrix(frame, alpha=0.5, figsize=None, ax=None, diagonal='hist', marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds)
各参数如下:
frame:(DataFrame),DataFrame对象
alpha:(float, 可选), 图像透明度,一般取(0,1]
figsize: ((float,float), 可选),以英寸为单位的图像大小,一般以元组 (width, height) 形式设置
ax:(Matplotlib axis object, 可选),一般取None
diagonal:({‘hist’, ‘kde’}),必须且只能在{‘hist’, ‘kde’}中选择1个,’hist’表示直方图(Histogram plot),’kde’表示核密度估计(Kernel Density Estimation);该参数是scatter_matrix函数的关键参数,下文将做进一步介绍
marker:(str, 可选), Matplotlib可用的标记类型,如’.’,’,’,’o’等
density_kwds:(other plotting keyword arguments,可选),与kde相关的字典参数
hist_kwds:(other plotting keyword arguments,可选),与hist相关的字典参数
range_padding:(float, 可选),图像在x轴、y轴原点附近的留白(padding),该值越大,留白距离越大,图像远离坐标原点
kwds:(other plotting keyword arguments,可选),与scatter_matrix函数本身相关的字典参数
‘hist’值
diagonal参数取’hist’值时,表示散布矩阵的对角线上的图形为数据集各特征的直方图。直方图是一种可对值频率进行离散化显示的柱状图,数据点被拆分到离散的,间隔均匀的面元中,绘制的是各面元中数据点的数量。例如有1维整型数组,共有元素440个,按照值从大至小的顺序排列后,其散布图与直方图如下所示:
‘kde’值
diagonal参数取’kde’值时,表示散布矩阵的对角线上的图形为数据集各特征的核密度估计(Kernel Density Estimation,KDE)。核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。简单来说,核密度估计就是在当前数据集(连续型数据样本)已知的情况下,通过计算来获取该样本分布的概率密度函数;在计算获取时需要用到核函数,如Gaussian Kernel Density、Exponential Kernel Density、Cosine Kernel Density等,不同核函数可以得到样本整体趋势和密度分布规律性基本一致的结果;影响该结果的还包括带宽(bandwidth),带宽值过大或过小都会影响估计结果;关于核密度估计的进一步论述请参考这里。以相同的1维整型数组为例,使用Gaussian Kernel Density估计得到的密度函数如下所示:
scatter_matrix函数实例
以优达学城的数据集为例,来说明散布矩阵函数的使用方法。该数据集是某供货商统计的各类客户的年度采购额,每行数据为1个客户的采购记录,共440行;数据集包括6个维度——Fresh(生鲜)、Milk(奶制品)、Grocery(杂货)、Frozen(冷藏食品)、Detergents_Paper(清洁纸)、Delicatessen(熟食品),记录了客户采购不同门类产品的情况;数据集元素均为整型数据,无缺失值。import pandas as pd
import matplotlib.pyplot as plt
try:
data = pd.read_csv("customers_dataset.csv")
except:
print "Dataset could not be loaded."
pd.plotting.scatter_matrix(data, alpha=0.7, figsize=(14,8), diagonal='kde')
plt.show()在上文介绍diagonal参数取’hist’、’kde’值时,绘图所用数据为Fresh列数据;从图中可以看出,单列数据绘制的密度函数曲线与本图左上角第1个子图一致。
图中对角线上的子图均为经高斯核密度估计后的密度函数曲线,scatter_matrix函数源码中对应部分如下:
……
# Deal with the diagonal by drawing a histogram there.
if diagonal == 'hist':
ax.hist(values, **hist_kwds)
elif diagonal in ('kde', 'density'):
from scipy.stats import gaussian_kde
y = values
gkde = gaussian_kde(y)
ind = np.linspace(y.min(), y.max(), 1000)
ax.plot(ind, gkde.evaluate(ind), **density_kwds)
……散布矩阵图呈对称结构,除对角上的密度函数图之外,其他子图分别显示了不同特征列之间的关联关系,如Grocery与Detergents_Paper之间、Grocery与Milk之间、Milk与Detergents_Paper之间近似成线性关系,说明该些特征之间关联性很强;相反地,其他各特征列之间的散布状态比较杂乱,基本无规律可循,说明各特征之间的关联性不强。
分析数据集各特征(列)之间的关系时,散布矩阵能以图形的形式“定性”给出各特征之间的关系,如要进一步“定量”分析,则需要使用相关系数。
相关系数(correlation coefficients)
在统计学中,皮尔逊积矩相关系数(Pearson product-moment correlation coefficient,又称作 PPMCC或PCCs, 常用r或Pearson’s r表示)用于度量两个变量X和Y之间的相关关系(线性相关),其值介于-1与1之间。在进行数据分析时,常用作度量各特征之间的相关程度。Numpy中的计算相关系数的函数为:
corrcoef(x, y=None, rowvar=True, bias=<class numpy._globals._NoValue>, ddof=<class numpy._globals._NoValue>)
各参数如下:
x:(array_like),包含多个特征和值的1维或2维数组,每行表示一个特征,每列表示各特征的取值,以行为依据计算各特征之间的相关系数
y:(array_like,可选),一组额外的特征和值,数组形状与x相同
rowvar:(bool, 可选),该值为True时,每行表示1个特征,各列表式各特征的取值;该值为False时,每列表示1个特征,各行表式各特征的取值;默认情况下为True
bias:(_NoValue,可选),无效果,从1.10.0版本后废止
ddof :(_NoValue,可选),无效果,从1.10.0版本后废止
corrcoef函数实例
仍以优达学城的数据集为例,计算各特征之间的相关系数并绘图:import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
try:
data = pd.read_csv("customers_dataset.csv")
except:
print "Dataset could not be loaded."
cov = np.corrcoef(data.T)
img = plt.matshow(cov,cmap=plt.cm.winter)
plt.colorbar(img, ticks=[-1,0,1])
plt.xticks(np.arange(len(data.keys())), data.keys())
plt.yticks(np.arange(len(data.keys())), data.keys())
plt.show()该图形也为对称结构,依据相关系数的计算式,其对角线上的相关系数为1;子图颜色越接近绿色表示相关系数越接近1,特征相关性越强且为正相关,子图颜色接近另一个极端(-1)时,特征之间相关性也很强且为负相关;本例相关系数最小值为-0.132,蓝色最浓的子图即为该值,0处的颜色表示特征之间不相关(相关系数为0)。
从图中可以看出,Grocery与Detergents_Paper特征相关性最强,Grocery与Milk、Milk与Detergents_Paper特征之间也有较强相关性,其余各特征之间相关性较弱、甚至不相关,该结论与散布矩阵图得出的结论一致。
总结
对于给定数据集,Pandas的scatter_matrix函数能够显示各特征的密度函数曲线,能大致显示各特征之间的相关关系,Numpy的corrcoef函数能够准确计算各特征之间的相关系数,且能借助Matplotlib库以图形形式直观表达。参考
http://blog.csdn.net/sinat_25059791/article/details/71336557
相关文章推荐
- 散布矩阵(Scatter Matrix)
- 散布矩阵(Scatter Matrix)
- 散布矩阵(Scatter Matrix)(一)
- R语言linux 安装命令,特征之间的相关系数分析实例
- pandas的scatter_matrix散布矩阵图如何理解
- 如何做出相关系数矩阵可视化图
- Matlab编程实例(4) 相位角与相关系数曲线
- 声明一个矩阵类Matrix,有这样一些实例方法:将一个矩阵转置、求两个矩阵的和。
- 经典相关分析,典型关分析, CCA,Canonical Correlation Analysis,多元变量分析,线性组合,相关系数最大化
- Excel在统计分析中的应用—第十一章—相关分析-简单线性相关-使用相关分析工具确定相关系数
- Excel在统计分析中的应用—第十一章—相关分析-多元相关-多元相关系数
- 协方差矩阵, 相关系数矩阵
- C#中矩阵运算方法实例分析
- 数据挖掘学习------------------1-数据准备-4-主成分分析(PCA)降维和相关系数降维
- C++中map的相关用法及实例分析
- 数据分析之《菜鸟侦探挑战数据分析》-3-R语言-散点图,相关系数,回归线
- Python+pandas计算数据相关系数的实例
- 测试相关理解(四)边界值分析实例
- Numpy中矩阵matrix读取一列的方法及数组和矩阵的相互转换实例
- R语言实用案例分析-相关系数的应用