TeraSort实验--测试Map和Reduce Task数量对Hadoop性能的影响
2017-11-19 11:40
501 查看
一、 实验环境
1个master节点, 16个slave节点: CPU:8GHZ , 内存: 2G
网络:局域网
二、 实验描述
通过Hadoop自带的Terasort排序程序,测试不同的map task和reduce task数量,对Hadoop性能的影响。
实验数据由程序中的teragen程序生成,数据量为1GB和10GB。
通过设置mapred.min.split.size,从而调节map task的数量;设置mapred.reduce.tasks,从而调节reduce task的数量;
dfs.replication的值设为3,其它参数默认。
三、 实验结果与分析
Ø 实验一
表1、改变reduce task(数据量为1GB)
结果分析:
1) 当reduce task的值小于15时,总时间和Reduce时间都与Reduce task数量成反比关系。当reduce task的值大于15时,总时间和reduce时间基本保持恒定。Reduce task的数量应该设置为接近slave节点数量,或者适当大于节点数,不宜设置为比节点数量小太多。
2) Map时间与Reduce task之间没有明显的关系。
3) Killed map Task Attempts的值对Map的时间影响很大,表1中当reduce task = 45时,Killed map Task Attempts的值为1,此时Map的时间很长,从图1可看出,map的时间主要集中在map 99%的最后阶段。
4) job运行过程中产生Killed Task Attempts的原因:这是因为hadoop里面对task的speculative机制。简单来说就是hadoop觉得有些task运行过慢,所以它在其它tasktracker上同时再运行同样的任务,当其中一个完成后,其余同样的任务就会被kill掉。这就造成有多个被kill的taskattempt。可以通过设置mapred.map.tasks.speculative.execution为false来禁止hadoop的这种行为,这样可以提高效率,因为每个speculative都是占用task的slot的。
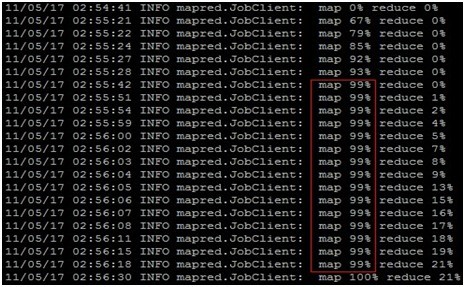
图1、表1中当reduce task = 45的执行过程
Ø 实验二
表2 改变reduce task(数据量为1GB)

图2、 1G数据性能对比
表3 改变map task(数据量为10GB)
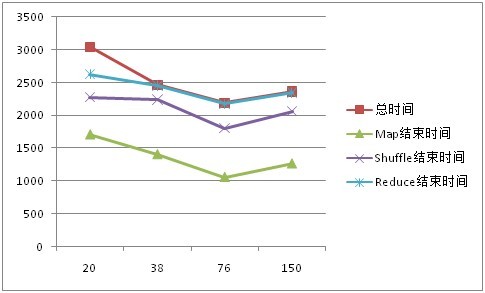
图2、 10G数据性能对比
结果分析:
通过学习这篇文章,我觉得有以下几点可以作为设置maptask和reducetask数量时的考虑:
1、blocksize最好设置为默认值,这样split的大小与其一致,效率较高。当然出现较大的数据时,如TB级别的,可以适当的调整split的大小,设置为256M或者512M。
2、尽量关闭hadoop的speculative功能,在大部分情况下,没必要一个task运行在两处,然后再返回去处理掉运行慢的task。实际业务中,节点功能相似度比较高,节点之间的差距不会太大。
3、reducetask的数量尽量设置为slave节点数量的95%比较靠谱。既能充分利用每一个节点,也能确保一定的容错。当考虑全局汇总结果的情况下,只能设置一个reducetask。
4、对于多个小文件作为输入,请先进行小文件的合并。否则每一个小文件都是一个split,你自己考虑后果。
5、其他提高效率的小技巧:自定义文件的读取方式,JVM的重用等
原文地址http://blog.csdn.net/xiejava/archive/2011/05/19/6432095.aspx
1个master节点, 16个slave节点: CPU:8GHZ , 内存: 2G
网络:局域网
二、 实验描述
通过Hadoop自带的Terasort排序程序,测试不同的map task和reduce task数量,对Hadoop性能的影响。
实验数据由程序中的teragen程序生成,数据量为1GB和10GB。
通过设置mapred.min.split.size,从而调节map task的数量;设置mapred.reduce.tasks,从而调节reduce task的数量;
dfs.replication的值设为3,其它参数默认。
三、 实验结果与分析
Ø 实验一
表1、改变reduce task(数据量为1GB)
| Map task = 16 | ||||||||||
| Reduce task | 1 | 5 | 10 | 15 | 16 | 20 | 25 | 30 | 45 | 60 |
| 总时间 | 892 | 146 | 110 | 92 | 88 | 100 | 128 | 101 | 145 | 104 |
| Map 时间 | 24 | 21 | 25 | 50 | 21 | 40 | 24 | 48 | 109 | 25 |
| Reduce时间 | 875 | 125 | 88 | 71 | 67 | 76 | 102 | 80 | 98 | 83 |
| Killed map/reduce Task Attempts | 0/0 | 0/2 | 0/2 | 0/5 | 0/4 | 0/9 | 0/9 | 0/8 | 1/7 | 0/17 |
结果分析:
1) 当reduce task的值小于15时,总时间和Reduce时间都与Reduce task数量成反比关系。当reduce task的值大于15时,总时间和reduce时间基本保持恒定。Reduce task的数量应该设置为接近slave节点数量,或者适当大于节点数,不宜设置为比节点数量小太多。
2) Map时间与Reduce task之间没有明显的关系。
3) Killed map Task Attempts的值对Map的时间影响很大,表1中当reduce task = 45时,Killed map Task Attempts的值为1,此时Map的时间很长,从图1可看出,map的时间主要集中在map 99%的最后阶段。
4) job运行过程中产生Killed Task Attempts的原因:这是因为hadoop里面对task的speculative机制。简单来说就是hadoop觉得有些task运行过慢,所以它在其它tasktracker上同时再运行同样的任务,当其中一个完成后,其余同样的任务就会被kill掉。这就造成有多个被kill的taskattempt。可以通过设置mapred.map.tasks.speculative.execution为false来禁止hadoop的这种行为,这样可以提高效率,因为每个speculative都是占用task的slot的。
图1、表1中当reduce task = 45的执行过程
Ø 实验二
表2 改变reduce task(数据量为1GB)
| Reduce task = 15 | ||||
| Map task | 2 | 4 | 8 | 16 |
| Input Split Size | 512 | 256 | 128 | 64 |
| 总时间 | 372 | 181 | 120 | 120 |
| 平均 Map 时间 | 287 | 63 | 38 | 26 |
| Map结束时间 | 292 | 49 | 35 | 36 |
| 平均Shuffle时间 | 12 | 42 | 28 | 45 |
| Shuffle结束时间 | 308 | 103 | 63 | 67 |
| 平均Reduce时间 | 30 | 34 | 37 | 28 |
| Reduce结束时间 | 343 | 154 | 113 | 100 |
| Killed map/reduce Task Attempts | 0/4 | 0/5 | 0/3 | 0/5 |
图2、 1G数据性能对比
表3 改变map task(数据量为10GB)
| Reduce task = 15 | ||||
| Map task | 20 | 38 | 76 | 150 |
| Input Split Size | 512 | 256 | 128 | 64 |
| 总时间 | 3044 | 2464 | 2189 | 2362 |
| 平均 Map 时间 | 1274 | 825 | 403 | 231 |
| Map结束时间 | 1712 | 1409 | 1061 | 1268 |
| 平均Map时间 | 1800 | 1300 | 1144 | 1198 |
| Shuffle结束时间 | 2271 | 2236 | 1804 | 2059 |
| 平均Reduce时间 | 515 | 450 | 548 | 644 |
| Reduce结束时间 | 2624 | 2453 | 2181 | 2348 |
| Map Failed/Killed Task Attempts | 4/8 | 5/7 | 6/7 | 7/8 |
| Reduce Failed/Killed Task Attempts | 2/3 | 3/1 | 3/1 | 2/1 |
图2、 10G数据性能对比
结果分析:
通过学习这篇文章,我觉得有以下几点可以作为设置maptask和reducetask数量时的考虑:
1、blocksize最好设置为默认值,这样split的大小与其一致,效率较高。当然出现较大的数据时,如TB级别的,可以适当的调整split的大小,设置为256M或者512M。
2、尽量关闭hadoop的speculative功能,在大部分情况下,没必要一个task运行在两处,然后再返回去处理掉运行慢的task。实际业务中,节点功能相似度比较高,节点之间的差距不会太大。
3、reducetask的数量尽量设置为slave节点数量的95%比较靠谱。既能充分利用每一个节点,也能确保一定的容错。当考虑全局汇总结果的情况下,只能设置一个reducetask。
4、对于多个小文件作为输入,请先进行小文件的合并。否则每一个小文件都是一个split,你自己考虑后果。
5、其他提高效率的小技巧:自定义文件的读取方式,JVM的重用等
原文地址http://blog.csdn.net/xiejava/archive/2011/05/19/6432095.aspx

相关文章推荐
- TeraSort实验--测试Map和Reduce Task数量对Hadoop性能的影响
- TeraSort实验--测试Map和Reduce Task数量对Hadoop性能的影响
- TeraSort实验--测试Map和Reduce Task数量对Hadoop性能的影响
- 测试眼里的Hadoop系列 之Terasort
- hadoop.terasort测试
- 测试眼里的Hadoop系列 之Terasort
- 测试眼里的Hadoop系列 之Terasort
- 测试眼里的Hadoop系列 之Terasort
- 用MPI实现Hadoop Map/Reduce的TeraSort
- Benchmark性能测试工具,TestDFSIO/TeraSort
- hadoop 中map、reduce数量对mapreduce执行速度的影响
- 测试眼里的Hadoop系列 之Terasort
- 测试眼里的Hadoop系列 之Terasort
- Hadoop测试TeraSort
- Spark 与 Hadoop 关于 TeraGen/TeraSort 的对比实验(包含源代码)
- Hadoop Terasort
- 关于Map和List的性能测试报告
- 类间样本数量不平衡对分类模型性能的影响问题
- 转:性能测试中带宽的影响
- Sort_Buffer_Size 设置对服务器性能的影响