HBase源码系列(六)HBase存储结构与StoreFile存储格式
2017-11-16 21:50
441 查看
Region
Store
MemStore
MemStore Flush
StoreFile HFile
HFile 格式
KeyValue
Blocks
StoreFile存储格式
往HFile追加KeyValue
close的时候
open的时候
这次终于到了HBase的存储部分,先看一下 HBase系统架构图
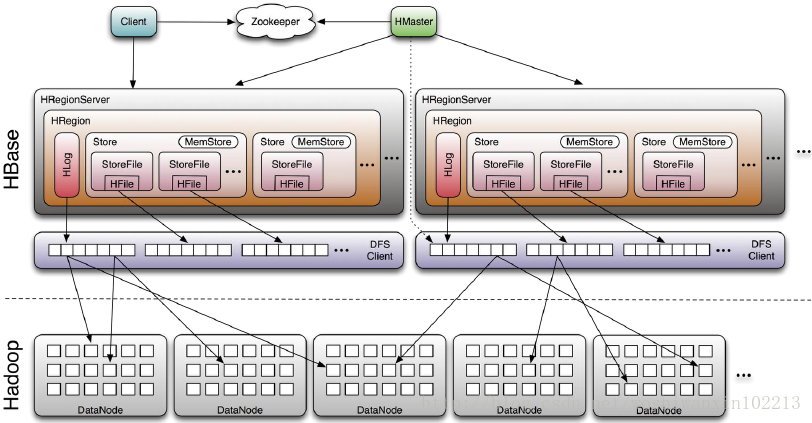
详细一点
1、当一个MemStore达到
2、当全局MemStore使用量达到
刷新顺序按照一个region的MemStore使用量的降序进行flush。
Regions将刷新它们的MemStore,直到整个MemStore使用率下降到或略低于
3、当给定region服务器的WAL中的WAL日志条目数达到hbase.regionserver.max.logs中指定的值时,来自各个regions的MemStore将被刷新到磁盘以减少WAL中的日志数量。
刷新基于时间顺序,最早的MemStore的regions将首先刷新,直到WAL日志降至

使用org.apache.hadoop.hbase.io.hfile.HFile工具查看HFile内容
在用writer进行append之前先把kv写到generalBloomFilterWriter里面,但是我们发现generalBloomFilterWriter是HFile.Writer里面的InlineBlockWriter。
接下来看HFileWriterV2的append方法。
从上面我们可以看到来,HFile写入的时候,是分一个块一个块的写入的,每个Block块64KB左右,这样有利于数据的随机访问,不利于连续访问,连续访问需求大的,可以把Block块的大小设置得大一点。好,我们继续看checkBlockBoundary方法。
简单交代一下
1、结束一个block的时候,把block的所有数据写入到hdfs的流当中,记录一些信息到DataBlockIndex(块的第一个key和上一个块的key的中间值,块的大小,块的起始位置)。
2、writeInlineBlocks(false)给了一个false,是否要关闭,所以现在什么都没干,它要等到最后才会输出的。
3、newBlock方法就是重置输出流,做好准备,读写下一个块。
在调用writer的close方法之前,close了两个BloomFilter,把BloomFilter的类型写进FileInfo里面去,把BloomWriter添加到Writer里面。下面进入HFileWriterV2的close方法!
主要过程有:
1、输出HFileBlocks
2、输出HFileBlockIndex的二级索引(我叫它二级索引,我也不知道对不对,HFileBlockIndex那块我有点儿忘了,等我再重新调试的时候再看看吧)
3、如果有的话,输出MetaBlock
下面的部分是打开文件的时候就加载的:
4、输出HFileBlockIndex的根索引
5、如果有的话,输出MetaBlockIndex的根索引(它比较小,所以只有一层)
6、输出文件信息(FileInfo)
7、输出文件尾巴(Trailer)
Store
MemStore
MemStore Flush
StoreFile HFile
HFile 格式
KeyValue
Blocks
StoreFile存储格式
往HFile追加KeyValue
close的时候
open的时候
这次终于到了HBase的存储部分,先看一下 HBase系统架构图
Region
Region是构成分布式table的基本元素,它由每个Column Family 对应一个Store组成。/hbase /<Table> (Tables in the cluster) /<Region> (Regions for the table) /<ColumnFamily> (ColumnFamilies for the Region for the table) /<StoreFile> (StoreFiles for the ColumnFamily for the Regions for the table)
详细一点
Table (HBase table) Region (Regions for the table) Store (Store per ColumnFamily for each Region for the table) MemStore (MemStore for each Store for each Region for the table) StoreFile (StoreFiles for each Store for each Region for the table) Block (B 4000 locks within a StoreFile within a Store for each Region for the table)
Store
Store有一个MemStore和0个或更多的StoreFiles(HFiles)。MemStore
MemStore保存对Store的内存修改。 修改是Cells / KeyValues。 当请求刷新时,当前的MemStore被移动到快照并被清除。HBase将继续处理来自新的MemStore的编辑并支持快照,直到flusher报告flush成功。 此时,快照被丢弃。 请注意,发生刷新时,属于同一区域的MemStore将全部刷新。MemStore Flush
MemStore刷新可以在下面列出的任何条件下触发。 最小flush单位是每个region,而不是单个MemStore级别。1、当一个MemStore达到
hbase.hregion.memstore.flush.size配置的大小时,属于一个region的所有MemStore都会刷新到磁盘。
2、当全局MemStore使用量达到
hbase.regionserver.global.memstore.upperLimit配置的大小时,不同region的MemStore将会刷新到磁盘,以减少RegionServer中的MemStore使用量。
刷新顺序按照一个region的MemStore使用量的降序进行flush。
Regions将刷新它们的MemStore,直到整个MemStore使用率下降到或略低于
hbase.regionserver.global.memstore.lowerLimit。
3、当给定region服务器的WAL中的WAL日志条目数达到hbase.regionserver.max.logs中指定的值时,来自各个regions的MemStore将被刷新到磁盘以减少WAL中的日志数量。
刷新基于时间顺序,最早的MemStore的regions将首先刷新,直到WAL日志降至
hbase.regionserver.max.logs以下。
StoreFile (HFile)
StoreFile是实际存储数据的。StoreFile是HFile的轻量级包装。HFile 格式
HFile文件格式基于Hadoop的TFile,模仿了Google Bigtable 架构中的SSTable格式。文件格式如下:KeyValue
KeyValue类是HBase中数据存储的核心。 KeyValue包装一个字节数组,并将偏移量和长度值放入传递的数组中,指定将内容开始解释为KeyValue的位置。使用org.apache.hadoop.hbase.io.hfile.HFile工具查看HFile内容
$ ${HBASE_HOME}/bin/hbase org.apache.hadoop.hbase.io.hfile.HFileBlocks
StoreFiles由块组成。 块大小在每个ColumnFamily的基础上配置。StoreFile存储格式
往HFile追加KeyValue
看一下StoreFile里面的append方法。public void append(final Cell cell) throws IOException {
//如果是新的rowkey的value,就追加到Bloomfilter里面去
appendGeneralBloomfilter(cell);
//如果是DeleteFamily、DeleteFamilyVersion类型的kv
appendDeleteFamilyBloomFilter(cell);
writer.append(cell);
//记录最新的put的时间戳,更新时间戳范围
trackTimestamps(cell);
}在用writer进行append之前先把kv写到generalBloomFilterWriter里面,但是我们发现generalBloomFilterWriter是HFile.Writer里面的InlineBlockWriter。
generalBloomFilterWriter = BloomFilterFactory.createGeneralBloomAtWrite( conf, cacheConf, bloomType, (int) Math.min(maxKeys, Integer.MAX_VALUE), writer); //在createGeneralBloomAtWriter方法发现了addInlineBlockWriter() ... CompoundBloomFilterWriter bloomWriter = new CompoundBloomFilterWriter(getBloomBlockSize(conf), err, Hash.getHashType(conf), maxFold, cacheConf.shouldCacheBloomsOnWrite(), bloomType == BloomType.ROWCOL ? KeyValue.COMPARATOR : KeyValue.RAW_COMPARATOR); writer.addInlineBlockWriter(bloomWriter);
接下来看HFileWriterV2的append方法。
public void append(final Cell cell) throws IOException {
byte[] value = cell.getValueArray();
int voffset = cell.getValueOffset();
int vlength = cell.getValueLength();
// checkKey uses comparator to check we are writing in order.
boolean dupKey = checkKey(cell);
checkValue(value, voffset, vlength);
if (!dupKey) {
//在写每一个新的KeyValue之间,都要检查,到了BlockSize就重新写一个HFileBlock
checkBlockBoundary();
}
if (!fsBlockWriter.isWriting()) {
//如果当前的fsBlockWriter的状态不对,就重新写一个新块
newBlock();
}
if (warnCellWithTags && getFileContext().isIncludesTags()) {
LOG.warn("A minimum HFile version of " + HFile.MIN_FORMAT_VERSION_WITH_TAGS
+ " is required to support cell attributes/tags. Consider setting "
+ HFile.FORMAT_VERSION_KEY + " accordingly.");
warnCellWithTags = false;
}
fsBlockWriter.write(cell);
totalKeyLength += CellUtil.estimatedSerializedSizeOfKey(cell);
totalValueLength += vlength;
// Are we the first key in this block?
if (firstCellInBlock == null) {
// If cell is big, block will be closed and this firstCellInBlock reference will only last
// a short while.
firstCellInBlock = cell;
}
// TODO: What if cell is 10MB and we write infrequently? We'll hold on to the cell here
// indefinetly?
lastCell = cell;
entryCount++;
this.maxMemstoreTS = Math.max(this.maxMemstoreTS, cell.getSequenceId());
}从上面我们可以看到来,HFile写入的时候,是分一个块一个块的写入的,每个Block块64KB左右,这样有利于数据的随机访问,不利于连续访问,连续访问需求大的,可以把Block块的大小设置得大一点。好,我们继续看checkBlockBoundary方法。
protected void checkBlockBoundary() throws IOException {
if (fsBlockWriter.blockSizeWritten() < hFileContext.getBlocksize())
return;
finishBlock();
writeInlineBlocks(false);
newBlock();
}简单交代一下
1、结束一个block的时候,把block的所有数据写入到hdfs的流当中,记录一些信息到DataBlockIndex(块的第一个key和上一个块的key的中间值,块的大小,块的起始位置)。
2、writeInlineBlocks(false)给了一个false,是否要关闭,所以现在什么都没干,它要等到最后才会输出的。
3、newBlock方法就是重置输出流,做好准备,读写下一个块。
close的时候
接着看StoreFile的close方法。 close的时候就有得忙咯,从之前的图上面来看,它在最后的时候是最忙的,因为它要写入一大堆索引信息、附属信息啥的。public void close() throws IOException {
boolean hasGeneralBloom = this.closeGeneralBloomFilter();
boolean hasDeleteFamilyBloom = this.closeDeleteFamilyBloomFilter();
// 调用HFileWriterV2的close方法
writer.close();
}在调用writer的close方法之前,close了两个BloomFilter,把BloomFilter的类型写进FileInfo里面去,把BloomWriter添加到Writer里面。下面进入HFileWriterV2的close方法!
public void close() throws IOException {
if (outputStream == null) {
return;
}
// Save data block encoder metadata in the file info.
// 经过编码压缩的,把编码压缩方式写进FileInfo里面
blockEncoder.saveMetadata(this);
// Write out the end of the data blocks, then write meta data blocks.
// followed by fileinfo, data block index and meta block index.
finishBlock();
//输出DataBlockIndex索引的非root层信息
writeInlineBlocks(true);
FixedFileTrailer trailer = new FixedFileTrailer(getMajorVersion(), getMinorVersion());
// Write out the metadata blocks if any.
if (!metaNames.isEmpty()) {
for (int i = 0; i < metaNames.size(); ++i) {
// store the beginning offset
long offset = outputStream.getPos();
// write the metadata content
// 输出meta的内容,它是meta的名字的集合,按照名字排序
DataOutputStream dos = fsBlockWriter.startWriting(BlockType.META);
metaData.get(i).write(dos);
fsBlockWriter.writeHeaderAndData(outputStream);
totalUncompressedBytes += fsBlockWriter.getUncompressedSizeWithHeader();
// Add the new meta block to the meta index.
// 把meta块的信息加到meta块的索引里
metaBlockIndexWriter.addEntry(metaNames.get(i), offset,
fsBlockWriter.getOnDiskSizeWithHeader());
}
}
// Load-on-open section.
// Data block index.
//
// In version 2, this section of the file starts with the root level data
// block index. We call a function that writes intermediate-level blocks
// first, then root level, and returns the offset of the root level block
// index.
// 下面这部分是打开文件的时候就加载的部分,是前面部分的索引
// HFileBlockIndex的根层次的索引
long rootIndexOffset = dataBlockIndexWriter.writeIndexBlocks(outputStream);
trailer.setLoadOnOpenOffset(rootIndexOffset);
// Meta block index.
metaBlockIndexWriter.writeSingleLevelIndex(fsBlockWriter.startWriting(
BlockType.ROOT_INDEX), "meta");
fsBlockWriter.writeHeaderAndData(outputStream);
totalUncompressedBytes += fsBlockWriter.getUncompressedSizeWithHeader();
if (this.hFileContext.isIncludesMvcc()) {
// Append the given key/value pair to the file info
appendFileInfo(MAX_MEMSTORE_TS_KEY, Bytes.toBytes(maxMemstoreTS));
appendFileInfo(KEY_VALUE_VERSION, Bytes.toBytes(KEY_VALUE_VER_WITH_MEMSTORE));
}
// 把FileInfo的起始位置写入trailer,然后输出
writeFileInfo(trailer, fsBlockWriter.startWriting(BlockType.FILE_INFO));
fsBlockWriter.writeHeaderAndData(outputStream);
totalUncompressedBytes += fsBlockWriter.getUncompressedSizeWithHeader();
// 输出GENERAL_BLOOM_META、DELETE_FAMILY_BLOOM_META类型的BloomFilter的信息
for (BlockWritable w : additionalLoadOnOpenData) {
fsBlockWriter.writeBlock(w, outputStream);
totalUncompressedBytes += fsBlockWriter.getUncompressedSizeWithHeader();
}
// HFileBlockIndex的二级实体的层次
trailer.setNumDataIndexLevels(dataBlockIndexWriter.getNumLevels());
// 压缩前的HFileBlockIndex的大小
trailer.setUncompressedDataIndexSize(
dataBlockIndexWriter.getTotalUncompressedSize());
// 第一个HFileBlock的起始位置
trailer.setFirstDataBlockOffset(firstDataBlockOffset);
// 最后一个HFileBlock的起始位置
trailer.setLastDataBlockOffset(lastDataBlockOffset);
// 比较器的类型
trailer.setComparatorClass(comparator.getClass());
// HFileBlockIndex的根实体的数量,应该是和HFileBlock的数量是一样的
// 它每次都把HFileBlock的第一个key加进去
trailer.setDataIndexCount(dataBlockIndexWriter.getNumRootEntries());
// 把Trailer的信息写入硬盘,关闭输出流
finishClose(trailer);
fsBlockWriter.release()
b06f
;
}主要过程有:
1、输出HFileBlocks
2、输出HFileBlockIndex的二级索引(我叫它二级索引,我也不知道对不对,HFileBlockIndex那块我有点儿忘了,等我再重新调试的时候再看看吧)
3、如果有的话,输出MetaBlock
下面的部分是打开文件的时候就加载的:
4、输出HFileBlockIndex的根索引
5、如果有的话,输出MetaBlockIndex的根索引(它比较小,所以只有一层)
6、输出文件信息(FileInfo)
7、输出文件尾巴(Trailer)
open的时候
实例化Reader的时候,根据不同类型的文件是怎么实例化Reader的? 在StoreFile里面搜索open方法。this.reader = fileInfo.open(this.fs, this.cacheConf); // Load up indices and fileinfo. This also loads Bloom filter type. metadataMap = Collections.unmodifiableMap(this.reader.loadFileInfo());

相关文章推荐
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式
- HBase源码系列(六)HBase存储结构与StoreFile存储格式