python基础-正则表达式、python使用正则
2017-11-13 15:36
519 查看
正则表达式
字符组
元字符
量词
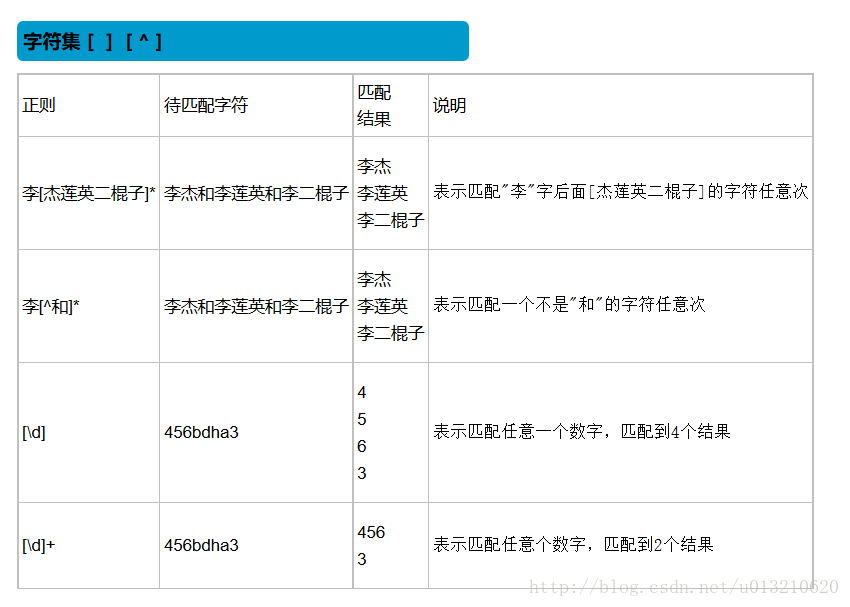
字符集
转义符
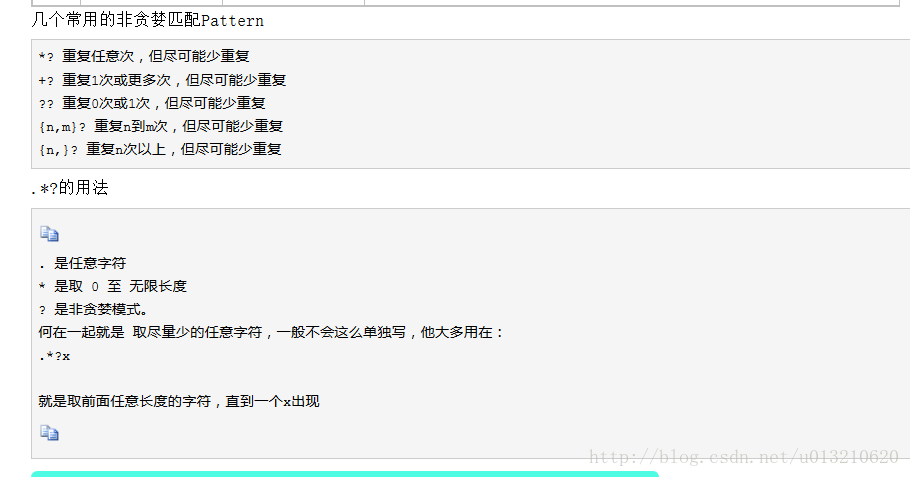
贪婪匹配
python中的正则使用
匹配标签
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
推荐一个在线正则
在线测试工具 http://tool.chinaz.com/regex/
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
\b 匹配一个单词的结尾
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[…] 匹配字符组中的字符
[^…] 匹配除了字符组中字符的所有字符
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次


输出如下:
获取的匹配结果可以直接用group(‘名字’)拿到对应的值
如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
获取的匹配结果可以直接用group(序号)拿到对应的值
输出如下:
字符组
元字符
量词
字符集
转义符
贪婪匹配
python中的正则使用
匹配标签
正则表达式
在学习python中如何使用正则表达式,我们先来了解下正则表达式正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
推荐一个在线正则
在线测试工具 http://tool.chinaz.com/regex/
字符组
字符组 : [字符组]| 正则 | 待匹配字符 | 结果 | 说明 |
|---|---|---|---|
| [0123456789] | 8 | True | 在一个字符组里枚举合法的所有字符,字符组里的任意一个字符和”待匹配字符”相同都视为可以匹配 |
| [0-9] | 7 | True | 也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
| [a-z] | s | True | 同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
| [A-Z] | B | True | [A-Z]就表示所有的大写字母 |
| [0-9a-fA-F] | e | True | 可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
元字符
. 匹配除换行符以外的任意字符\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
\b 匹配一个单词的结尾
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[…] 匹配字符组中的字符
[^…] 匹配除了字符组中字符的所有字符
| 正则 | 待匹配字符 | 结果 | 说明 |
|---|---|---|---|
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有”海.”的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配”海.” |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的”海.$” |
量词:
* 重复零次或更多次+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
字符集[][^]
*转义符 *
贪婪匹配
python中的正则使用
import re
# 返回所有满足匹配条件的结果,放在列表里
ret = re.findall('a', 'eva egon yuan')
print(ret) #结果 : ['a', 'a']
#search从左到右依次找,找到一个就回来,需要使用group()获取返回值
#如果re.search找不到,就返回None。使用group会报错
ret = re.search('a', 'eva egon yuan')
if ret:
print(ret.group())
# match从头开始匹配,匹配上了需要使用group来获取返回值
# 匹配不上返回None,使用group会报错
# 同search,不过尽在字符串开始处进行匹配
ret = re.match('a', 'abc').group()
print(ret)
#结果 : 'a'
# 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
ret = re.split('[ab]', 'abcd')
print(ret) # ['', '', 'cd']
#将数字替换成'H',参数1表示只替换1个
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)
print(ret) #evaHegon4yuan4
#将数字替换成'H',返回元组(替换的结果,替换了多少次)
ret = re.subn('\d', 'H', 'eva3egon4yuan4')
print(ret)
# 将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
obj = re.compile('\d{3}')
#正则表达式对象调用search,参数为待匹配的字符串
ret = obj.search('abc123eeee')
print(ret.group()) #结果 : 123
import re
# finditer返回一个存放匹配结果的迭代器
ret = re.finditer('\d', 'ds3sy4784a')
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果输出如下:
E:\python\python_sdk\python.exe E:/python/py_pro/1.复习.py
['a', 'a']
a
a
['', '', 'cd']
evaHegon4yuan4
('evaHegonHyuanH', 3)
123
<callable_iterator object at 0x035A1E50>
3
4
['7', '8', '4']
Process finished with exit code 0匹配标签
还可以在分组中利用?的形式给分组起名字获取的匹配结果可以直接用group(‘名字’)拿到对应的值
如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
获取的匹配结果可以直接用group(序号)拿到对应的值
ret = re.search("<\w+>\w+</\w+>","<h1>hello</h1>")
if ret:
print(ret.group())
ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")
print(ret.group('tag_name')) #结果 :h1
print(ret.group()) #结果 :<h1>hello</h1>
#分组的命名和组的引用
ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")
print(ret.group(1))
# 如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
# 获取的匹配结果可以直接用group(序号)拿到对应的值
print(ret.group()) #结果 :<h1>hello</h1>
ret = re.findall(r"<(\w+)>\w+</\1>","<h1>hello</h1>")
print(ret)输出如下:
E:\python\python_sdk\python.exe E:/python/py_pro/2.正则复习.py <h1>hello</h1> h1 <h1>hello</h1> h1 <h1>hello</h1> ['h1'] Process finished with exit code 0

相关文章推荐
- python爬虫由浅入深8---正则表达式及Re库的基础与使用
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
- python 基础学习 正则表达式2(使用)
- [零基础学JAVA]Java SE应用部分-22.Eclipse及正则表达式使用 推荐
- Java中正则表达式使用方法详解-Java基础-Java-编程开发
- Python使用正则表达式替换源码前序号
- 使用Python正则表达式从文章中取出所有图片路径
- [转]使用python的正则表达式做词法分析器
- Python天天美味(15) - Python正则表达式操作指南(re使用)(转)
- 【零基础学习PHP 五】正则表达式在php中的使用
- 在python 中使用正则表达式
- Python中使用正则表达式
- Python天天美味(15) - Python正则表达式操作指南(re使用)(转)
- python基础(5)--正则表达式
- Python 正则表达式 RE模块的使用方法
- PYTHON正则表达式 re模块使用说明
- 比较详细Python正则表达式操作指南(re使用)
- Python中的正则表达式基础
- 使用python和正则表达式获取url,及总结
- 正则表达式使用学习(C++、Qt、Python)