大数据计算引擎发展的四个阶段
2017-11-12 23:08
232 查看
根据一些公开资料整理,也许有失偏颇,仅供参考:
1.第一代
Hadoop 承载的 MapReduce
2.第二代
支持 DAG(有向无环图) 的框架: Tez 、 Oozie,主要还是批处理任务
3.第三代
Job 内部的 DAG(有向无环图) 支持(不跨越 Job),以及强调的实时计算:Spark
4.第四代
对流计算的支持,以及更一步的实时性:Flink
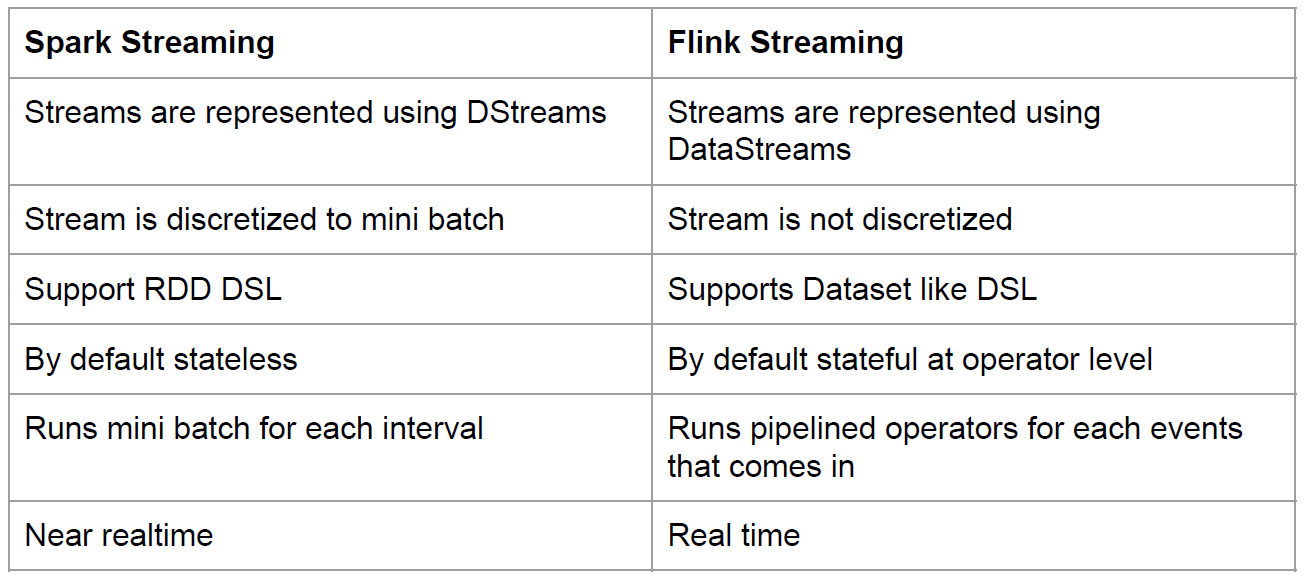
SparkStreaming VS Flink Streaming
1.第一代
Hadoop 承载的 MapReduce
2.第二代
支持 DAG(有向无环图) 的框架: Tez 、 Oozie,主要还是批处理任务
3.第三代
Job 内部的 DAG(有向无环图) 支持(不跨越 Job),以及强调的实时计算:Spark
4.第四代
对流计算的支持,以及更一步的实时性:Flink
SparkStreaming VS Flink Streaming

相关文章推荐
- 云计算IDC未来的四个发展阶段
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 职业发展的四个阶段
- 腾讯大数据之TDW计算引擎解析——Shuffle
- 数据引擎- 主流SQL计算引擎
- 2017中国云计算与大数据产业发展大会落幕
- 饿了么大数据计算引擎实践与应用 - 大数据
- [转载]DevOps发展的四个重要阶段
- 饿了么大数据计算引擎实践与应用 - 大数据
- 蒋步星:轻量级大数据计算引擎
- 动态数据仓库发展演变的五个阶段
- 纯JAVA大数据计算引擎
- 大数据应用的下一阶段发展方向在哪里?
- Spark大数据计算引擎介绍
- 2017中国云计算与大数据产业发展大会落幕
- 系统监控和管理及相关产品发展的四个阶段
- 企业发展滞缓,还不是因为踩了这四个数据大坑!
- 当代移动通信发展四个阶段
- 数据科学家如何优雅的运行R在spark内存计算引擎上
- 大数据SQL交互查询 presto/spark/mapreduce 计算引擎对比