python验证码简单识别
2017-11-12 16:09
357 查看
因为需求,所以接触了验证码这一块,原本感觉到会很难,学了之后挺简单的,但后来又发现自己还是too young。。。
PIL官方网站:http://www.pythonware.com/products/pil/
不支持python3,但有高手把它重新编译生成python3下可安装的exe了。这一非官方下载地址 http://www.lfd.uci.edu/~gohlke/pythonlibs/#pil ,
,它已经多年未更新了,差不多已经被遗弃了。
Pillow的Github主页:https://github.com/python-pillow/Pillow
Pillow的文档(对应版本v3.0.0):
https://pillow.readthedocs.org/en/latest/handbook/index.html
安装它很简单
使用方式:
#python2
#python3(因为是派生的PIL库,所以要导入PIL中的Image)
以python3为例,
open
format
format属性定义了图像的格式,如果图像不是从文件打开的,那么该属性值为None;size属性是一个tuple,表示图像的宽和高(单位为像素);mode属性为表示图像的模式,常用的模式为:L为灰度图,RGB为真彩色,CMYK为pre-press图像。如果文件不能打开,则抛出IOError异常。
save
convert()
convert() 是图像实例对象的一个方法,接受一个 mode 参数,用以指定一种色彩模式,mode 的取值可以是如下几种:
· 1 (1-bit pixels, black and
4000
white, stored with one pixel per byte)
· L (8-bit pixels, black and white)
· P (8-bit pixels, mapped to any other mode using a colour palette)
· RGB (3x8-bit pixels, true colour)
· RGBA (4x8-bit pixels, true colour with transparency mask)
· CMYK (4x8-bit pixels, colour separation)
· YCbCr (3x8-bit pixels, colour video format)
· I (32-bit signed integer pixels)
· F (32-bit floating point pixels)
Filter
from PIL import Image, ImageFilter
im = Image.open(‘1.png’)
# 高斯模糊
im.filter(ImageFilter.GaussianBlur)
# 普通模糊
im.filter(ImageFilter.BLUR)
# 边缘增强
im.filter(ImageFilter.EDGE_ENHANCE)
# 找到边缘
im.filter(ImageFilter.FIND_EDGES)
# 浮雕
im.filter(ImageFilter.EMBOSS)
# 轮廓
im.filter(ImageFilter.CONTOUR)
# 锐化
im.filter(ImageFilter.SHARPEN)
# 平滑
im.filter(ImageFilter.SMOOTH)
# 细节
im.filter(ImageFilter.DETAIL)
查看图像直方图
转换图像文件格式
屏幕截图
from PIL import ImageGrab
im = ImageGrab.grab((0,0,800,200)) #截取屏幕指定区域的图像
im = ImageGrab.grab() #不带参数表示全屏幕截图
图像裁剪与粘贴
box = (120, 194, 220, 294) #定义裁剪区域
region = im.crop(box) #裁剪
region = region.transpose(Image.ROTATE_180)
im.paste(region,box) #粘贴
图像缩放
im = im.resize((100,100)) #参数表示图像的新尺寸,分别表示宽度和高度
图像对比度增强
tesseract-ocr是谷歌的开源项目,用于图像文本识别,具体安装使用情况可以参照图片文字OCR识别-tesseract-ocr4.00.00安装使用(4.000版本是实验版,建议使用正式版的3.X)
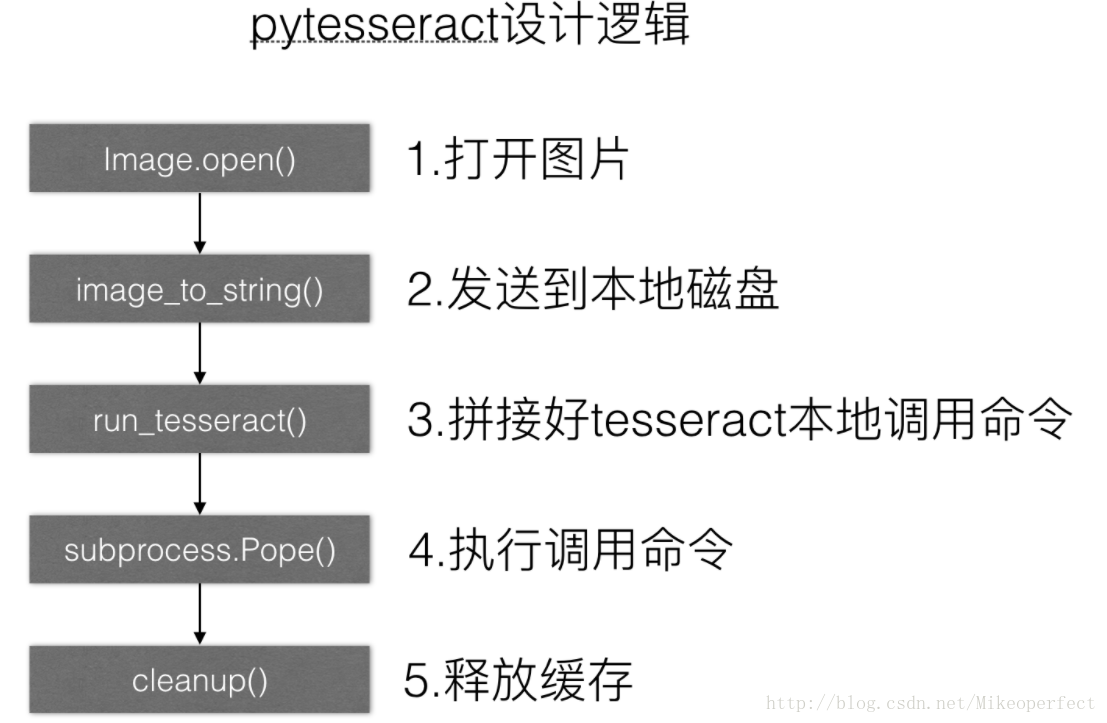
pytesseract是调用tesseract的一个库,所以必须先安装好tesseract,
如何安装pytesseract
pip install pytesseract
如何使用pytesseract
很简单,pytesseract只有一个简单的image_to_string方法。
示例
图片:
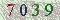
结果:
图一:

图二:
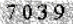
打印结果:

——来补充了———
这次选择的是云打码平台(非广告),当然啦,只是本人选择的是云打码,事实上其他的打码平台都是类似的,
首先要分清楚云打码平台的账户种类
云打码平台分两种:用户和开发者
我们只需使用用户就可以了
注册完之后可以选择充值,先充1块钱,有2000积分,下面是使用积分的说明:
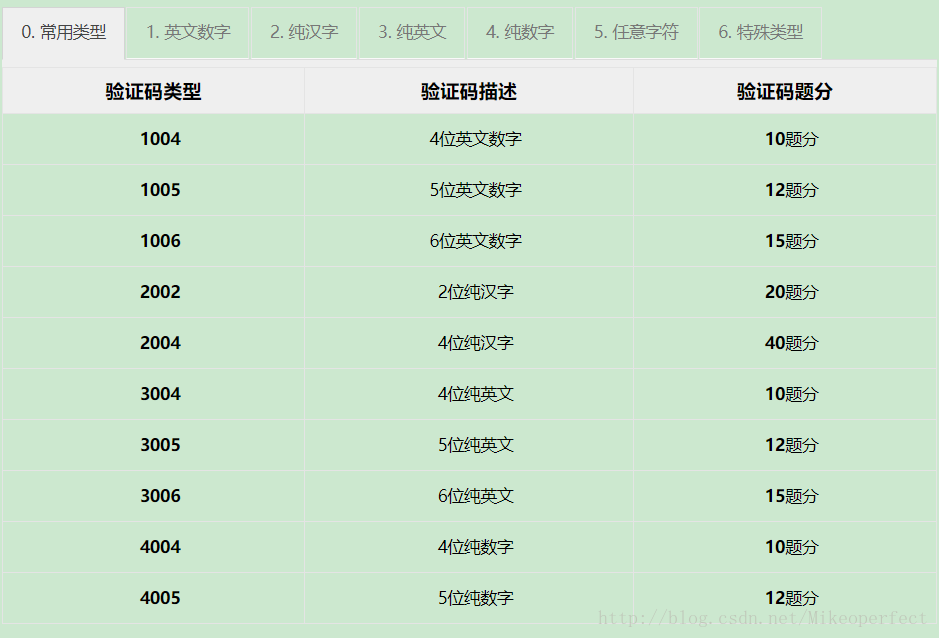
也就是说1块钱大概可以使用50次以上,这还是可以接受的
接下来就简单多了
用户username: ……..
密码password: ………
账户余额balance:………..分
只需修改验证码地址和验证码种类,填好注册时的用户名和密码,然后运行即可输出相关信息,目测新浪微博验证码识别率95%以上
直接运行下面的源码即可(记得改好上面的要求)
附赠几张新浪微博的验证码:



小结
验证码是一个神奇的产物,它充分的遏制住了一大批计算机上网的冲动,就是这么一个小小的验证码阻挡住了千军万马,但是我相信未来的算法一定会将这个产物解决掉的-。-。-。-。-。-。-。
PIL(python Image Library)
目前PIL的官方最新版本为1.1.7,支持的版本为python 2.5, 2.6, 2.7,PIL官方网站:http://www.pythonware.com/products/pil/
不支持python3,但有高手把它重新编译生成python3下可安装的exe了。这一非官方下载地址 http://www.lfd.uci.edu/~gohlke/pythonlibs/#pil ,
,它已经多年未更新了,差不多已经被遗弃了。
pillow
Pillow是PIL的一个派生分支,但如今已经发展成为比PIL本身更具活力的图像处理库。pillow可以说已经取代了PIL,将其封装成python的库(pip即可安装),且支持python2和python3,目前最新版本是3.0.0。Pillow的Github主页:https://github.com/python-pillow/Pillow
Pillow的文档(对应版本v3.0.0):
https://pillow.readthedocs.org/en/latest/handbook/index.html
安装它很简单
pip install pillow
使用方式:
#python2
import Image
#python3(因为是派生的PIL库,所以要导入PIL中的Image)
from PIL import Image
以python3为例,
open
from PIL import Image
im = Image.open("1.png")
im.show()format
format属性定义了图像的格式,如果图像不是从文件打开的,那么该属性值为None;size属性是一个tuple,表示图像的宽和高(单位为像素);mode属性为表示图像的模式,常用的模式为:L为灰度图,RGB为真彩色,CMYK为pre-press图像。如果文件不能打开,则抛出IOError异常。
print(im.format, im.size, im.mode)
save
im.save("c:\\")convert()
convert() 是图像实例对象的一个方法,接受一个 mode 参数,用以指定一种色彩模式,mode 的取值可以是如下几种:
· 1 (1-bit pixels, black and
4000
white, stored with one pixel per byte)
· L (8-bit pixels, black and white)
· P (8-bit pixels, mapped to any other mode using a colour palette)
· RGB (3x8-bit pixels, true colour)
· RGBA (4x8-bit pixels, true colour with transparency mask)
· CMYK (4x8-bit pixels, colour separation)
· YCbCr (3x8-bit pixels, colour video format)
· I (32-bit signed integer pixels)
· F (32-bit floating point pixels)
im = Image.open('1.png').convert('L')Filter
from PIL import Image, ImageFilter
im = Image.open(‘1.png’)
# 高斯模糊
im.filter(ImageFilter.GaussianBlur)
# 普通模糊
im.filter(ImageFilter.BLUR)
# 边缘增强
im.filter(ImageFilter.EDGE_ENHANCE)
# 找到边缘
im.filter(ImageFilter.FIND_EDGES)
# 浮雕
im.filter(ImageFilter.EMBOSS)
# 轮廓
im.filter(ImageFilter.CONTOUR)
# 锐化
im.filter(ImageFilter.SHARPEN)
# 平滑
im.filter(ImageFilter.SMOOTH)
# 细节
im.filter(ImageFilter.DETAIL)
查看图像直方图
im.histogram()
转换图像文件格式
def img2jpg(imgFile):
if type(imgFile)==str and imgFile.endswith(('.bmp', '.gif', '.png')):
with Image.open(imgFile) as im:
im.convert('RGB').save(imgFile[:-3]+'jpg')img2jpg('1.gif')
img2jpg('1.bmp')
img2jpg('1.png')屏幕截图
from PIL import ImageGrab
im = ImageGrab.grab((0,0,800,200)) #截取屏幕指定区域的图像
im = ImageGrab.grab() #不带参数表示全屏幕截图
图像裁剪与粘贴
box = (120, 194, 220, 294) #定义裁剪区域
region = im.crop(box) #裁剪
region = region.transpose(Image.ROTATE_180)
im.paste(region,box) #粘贴
图像缩放
im = im.resize((100,100)) #参数表示图像的新尺寸,分别表示宽度和高度
图像对比度增强
from PIL import Image
from PIL import ImageEnhance
#原始图像
image = Image.open('lena.jpg')
image.show()
#亮度增强
enh_bri = ImageEnhance.Brightness(image)
brightness = 1.5
image_brightened = enh_bri.enhance(brightness)
image_brightened.show()
#色度增强
enh_col = ImageEnhance.Color(image)
color = 1.5
image_colored = enh_col.enhance(color)
image_colored.show()
#对比度增强
enh_con = ImageEnhance.Contrast(image)
contrast = 1.5
image_contrasted = enh_con.enhance(contrast)
image_contrasted.show()
#锐度增强
enh_sha = ImageEnhance.Sharpness(image)
sharpness = 3.0
image_sharped = enh_sha.enhance(sharpness)
image_sharped.show()pytesseract
Python-tesseract是一款用于光学字符识别(OCR)的python工具,即从图片中识别出其中嵌入的文字。Python-tesseract是对Google Tesseract-OCR的一层封装。它也同时可以单独作为对tesseract引擎的调用脚本,支持使用PIL库(Python Imaging Library)读取的各种图片文件类型,包括jpeg、png、gif、bmp、tiff和其他格式,。作为脚本使用它将打印出识别出的文字而非写入到文件。所以安装pytesseract前要先安装PIL(也就是现在的pillow)和tesseract-orc这俩依赖库tesseract-ocr是谷歌的开源项目,用于图像文本识别,具体安装使用情况可以参照图片文字OCR识别-tesseract-ocr4.00.00安装使用(4.000版本是实验版,建议使用正式版的3.X)
pytesseract是调用tesseract的一个库,所以必须先安装好tesseract,
如何安装pytesseract
pip install pytesseract
如何使用pytesseract
from PIL import Image
import pytesseract
print(pytesseract.image_to_string(Image.open('test.png')))
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra'))#后面的lang是语言的意思,fra是法语的意思.很简单,pytesseract只有一个简单的image_to_string方法。
示例
图片:
from PIL import Image
from PIL import ImageEnhance
import pytesseract
im=Image.open("1.jpg")
im=im.convert('L')
im.show()
im=ImageEnhance.Contrast(im)
im=im.enhance(3)
im.show()
print(pytesseract.image_to_string(im))结果:
图一:
图二:
打印结果:
打码平台
众所周知,上面的验证码识别都是小儿科,也就简单的上面可以去去噪,换换灰度什么的,要是碰到了神奇的干扰线,或者奇葩的字母组合,那就基本上歇菜了,目前的验证码识别依旧存在着巨大的问题,所以打码平台也就经久不衰了,这么多年过去了,非但没有就此陌去,反而得到了飞速的发展,其中几个比较有名,下次有时间再来补充。。。——来补充了———
这次选择的是云打码平台(非广告),当然啦,只是本人选择的是云打码,事实上其他的打码平台都是类似的,
首先要分清楚云打码平台的账户种类
云打码平台分两种:用户和开发者
我们只需使用用户就可以了
注册完之后可以选择充值,先充1块钱,有2000积分,下面是使用积分的说明:
也就是说1块钱大概可以使用50次以上,这还是可以接受的
接下来就简单多了
用户username: ……..
密码password: ………
账户余额balance:………..分
只需修改验证码地址和验证码种类,填好注册时的用户名和密码,然后运行即可输出相关信息,目测新浪微博验证码识别率95%以上
直接运行下面的源码即可(记得改好上面的要求)
import http.client, mimetypes, urllib, json, time, requests
######################################################################
#验证码地址**(记得修改)**
Image="C:\\Users\\Desktop\\ORC\\1.png"
#验证码种类**(记得修改)**
Species=1005
class YDMHttp:
apiurl = 'http://api.yundama.com/api.php'
username = ''
password = ''
appid = ''
appkey = ''
def __init__(self, username, password, appid, appkey):
self.username = username
self.password = password
self.appid = str(appid)
self.appkey = appkey
def request(self, fields, files=[]):
response = self.post_url(self.apiurl, fields, files)
response = json.loads(response)
return response
def balance(self):
data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['balance']
else:
return -9001
def login(self):
data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['uid']
else:
return -9001
def upload(self, filename, codetype, timeout):
data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)}
file = {'file': filename}
response = self.request(data, file)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['cid']
else:
return -9001
def result(self, cid):
data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'cid': str(cid)}
response = self.request(data)
return response and response['text'] or ''
def decode(self, filename, codetype, timeout):
cid = self.upload(filename, codetype, timeout)
if (cid > 0):
for i in range(0, timeout):
result = self.result(cid)
if (result != ''):
return cid, result
else:
time.sleep(1)
return -3003, ''
else:
return cid, ''
def post_url(self, url, fields, files=[]):
for key in files:
files[key] = open(files[key], 'rb');
res = requests.post(url, files=files, data=fields)
return res.text
######################################################################
# 用户名(填自己的)**(记得修改)**
username = '*************'
# 密码(填自己的)**(记得修改)**
password = '*******'
# 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!(非开发者不用管)
appid = 1
# 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!(非开发者不用管)
appkey = '22cc5376925e9387a23cf797cb9ba745'
# 图片文件
filename = Image
# 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html codetype = Species
# 超时时间,秒
timeout = 60
# 检查
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login();
print('uid: %s' % uid)
# 查询余额
balance = yundama.balance();
print('balance: %s' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout);
print('cid: %s, result: %s' % (cid, result))
######################################################################附赠几张新浪微博的验证码:
小结
验证码是一个神奇的产物,它充分的遏制住了一大批计算机上网的冲动,就是这么一个小小的验证码阻挡住了千军万马,但是我相信未来的算法一定会将这个产物解决掉的-。-。-。-。-。-。-。

相关文章推荐
- python 验证码识别示例(一) 某个网站验证码的简单识别
- Python验证码识别:利用pytesser识别简单图形验证码
- 使用python以及工具包进行简单的验证码识别
- Python2.7+pytesser简单验证码的识别
- Python验证码识别:利用pytesser识别简单图形验证码
- 基于Python使用SVM识别简单的字符验证码的完整代码开源分享
- 用Python识别简单验证码
- pytesseract的简单验证码的识别-python
- Python2.7+pytesser简单验证码的识别
- Python2.7+pytesser实现简单验证码的识别方法
- 利用Python进行简单的验证码识别步骤
- Python验证码识别:利用pytesser识别简单图形验证码
- 利用Python进行简单的图像识别(验证码)
- Python验证码识别:利用pytesser识别简单图形验证码
- Python简单的验证码识别
- 基于python的验证码生成与识别1—生成简单的验证码
- 使用python及工具包进行简单的验证码识别
- Python验证码识别:利用pytesser识别简单图形验证码
- 用Python进行简单图像识别(验证码)
- 识别简单的验证码