关于Python-requests内容编码问题
2017-11-06 20:31
197 查看
参考了代码分析Python requests库中文编码问题一文,自己整理了一部分
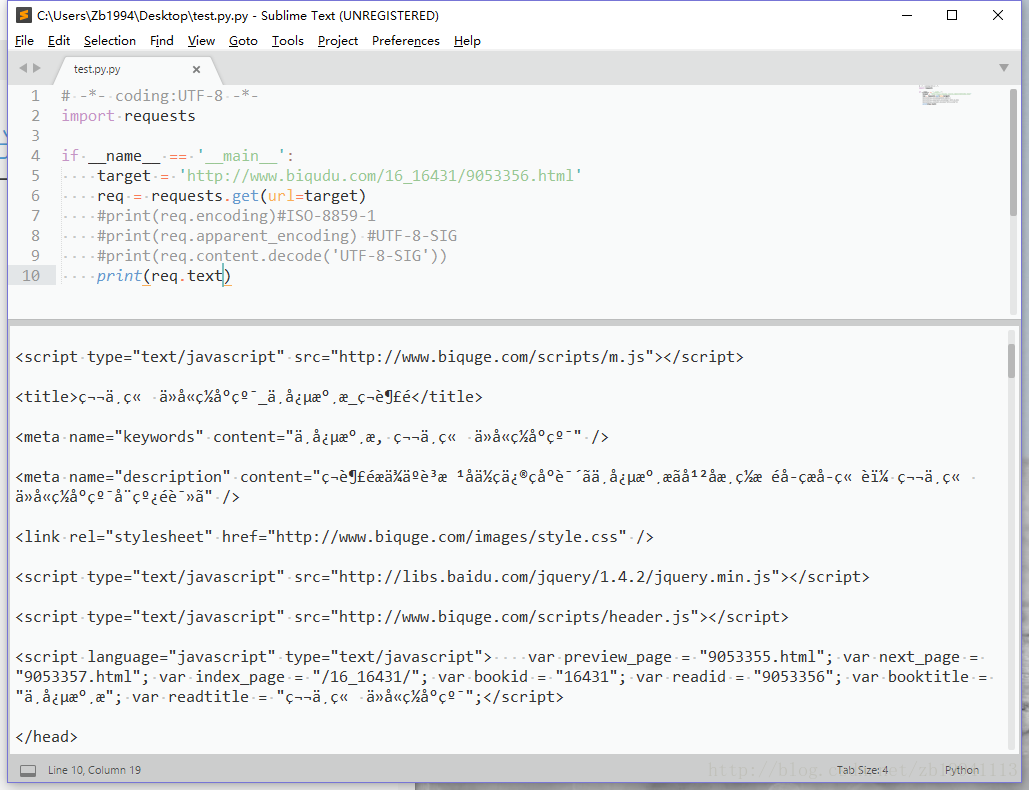
1.运行以下代码,结果为乱码
2.运行:
之所以会有ISO-8859-1这种编码是因为:
requests会从服务器返回的响应头的 Content-Type 去获取字符集编码,如果content-type有charset字段那么requests才能正确识别编码,否则就使用默认的 ISO-8859-1. 一般那些不规范的页面往往有这样的问题.
3.解决办法:
requests的返回结果对象里有个apparent_encoding函数, apparent_encoding通过调用chardet.detect()来识别文本编码
通过
说明本页面使用UTF-8-SIG编码,在明确了网页的字符集编码后可以使用
4.关于requests后面跟的text() 与content() 的区别:
r.text返回的是处理过的Unicode型的数据,而使用r.content返回的是bytes型的原始数据。也就是说,r.content相对于r.text来说节省了计算资源,r.content是把内容bytes返回. 而r.text是decode成Unicode. 如果headers没有charset字符集的化,text()会调用chardet来计算字符集。
1.运行以下代码,结果为乱码
2.运行:
print(req.encoding)结果显示ISO-8859-1
之所以会有ISO-8859-1这种编码是因为:
requests会从服务器返回的响应头的 Content-Type 去获取字符集编码,如果content-type有charset字段那么requests才能正确识别编码,否则就使用默认的 ISO-8859-1. 一般那些不规范的页面往往有这样的问题.
3.解决办法:
requests的返回结果对象里有个apparent_encoding函数, apparent_encoding通过调用chardet.detect()来识别文本编码
通过
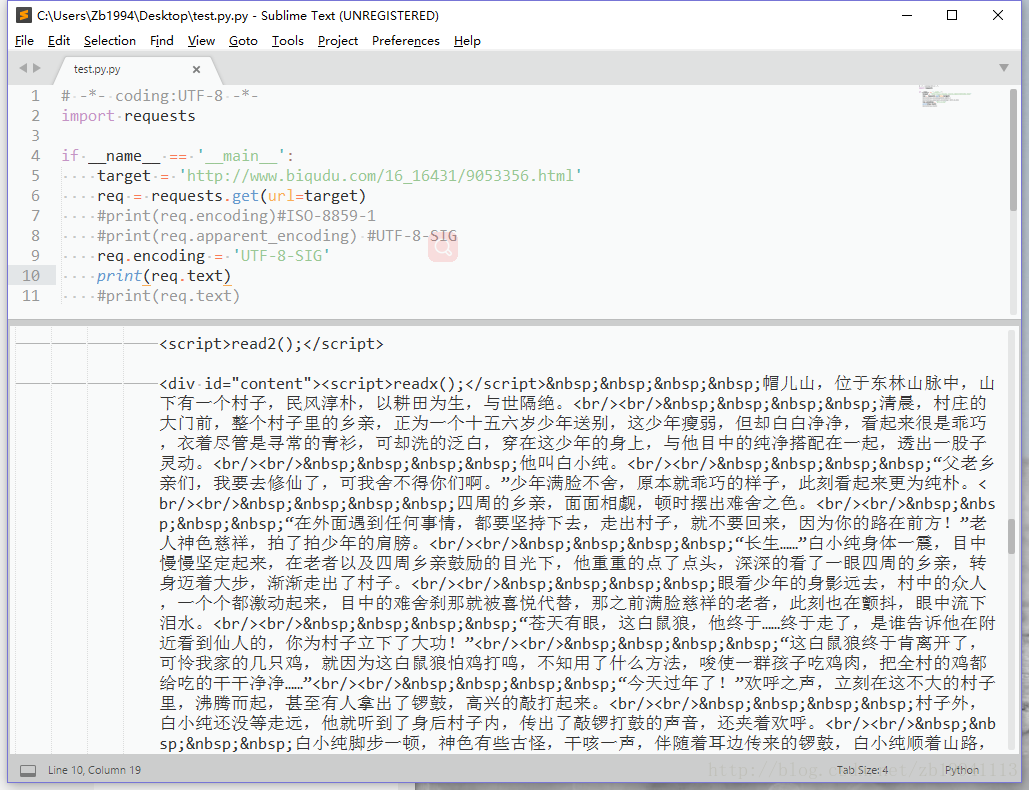
print(req.apparent_encoding)结果显示UTF-8-SIG
说明本页面使用UTF-8-SIG编码,在明确了网页的字符集编码后可以使用
r.encoding = 'UTF-8-SIG'获取正确结果,如下图所示:
4.关于requests后面跟的text() 与content() 的区别:
r.text返回的是处理过的Unicode型的数据,而使用r.content返回的是bytes型的原始数据。也就是说,r.content相对于r.text来说节省了计算资源,r.content是把内容bytes返回. 而r.text是decode成Unicode. 如果headers没有charset字符集的化,text()会调用chardet来计算字符集。

相关文章推荐
- Python 使用requests时的编码问题
- 关于python的编码问题的个人小结
- 关于python2.X的编码问题的转载(后续改用python3爬取搜狗壁纸)
- 关于python requests 包跑ssl的设置 和 charles相关抓包的问题
- Python——关于中文编码的问题
- 通过读写文本文件小结“关于python处理中文编码的问题”
- 关于python2.7中Windows下默认编码的问题
- Python3中关于中文编码的问题
- 关于Python的第三方库requests关闭SSL验证后,依然警告致使程序无法执行问题
- 关于Python编码问题的一些看法
- 关于python字符串编码问题的理解
- 关于python的str和unicode以及编码的问题
- Python处理unicode编码的txt文件(Python中文处理)——解决to_excel()和to_csv()导出文件内容为空的问题
- 关于Python文档读取UTF-8编码文件问题
- 关于python requests包新版本设置代理的问题
- 关于python编码问题无法读取GBK文件
- 在Python中关于中文编码问题的处理建议
- 关于Python编码的问题。
- 关于python3里gbk编码的问题解决
- SyntaxError: Non-ASCII character ‘\xe5′ in file 关于python中的编码问题