python(二):使用multiprocessing中的常见问题
2017-11-06 14:05
555 查看
简介
在python的解释器中,CPython是应用范围最广的一种,其具有丰富的扩展包,方便了开发者的使用。当然CPython也不是完美的,由于全局解释锁(GIL)的存在,python的多线程可以近似看作单线程。为此,开发者推出了multiprocessing,这里介绍一下使用中的常见问题。
环境
>>> import sys >>> print(sys.version) 3.6.0 |Anaconda 4.3.1 (64-bit)| (default, Dec 23 2016, 12:22:00) \n[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)]
共享变量
任务能否切分成多个子任务是判断一个任务能否使用多进程或多线程的重要标准。在任务切分时,不可避免的需要数据通讯,而共享变量是数据通讯的重要方式。在multiprocess中,共享变量有两种方式:Shared memory和
Server process。
share memory
multiprocess通过Array和
Value来共享内存
from multiprocessing import Array, Value
num = 10
elements = Array("i", [2 * i + 1 for i in range(num)])
val = Value('d', 0.0)然后就可以将数据同步到Process中。这里举一个例子,即将elements翻倍,val增加1,首先定义函数
def func(elements, val): for i, ele in enumerate(elements): elements[i] = ele * 2 val.value += 1
再定义
Process
from multiprocessing import Process p = Process(target=func, args=(elements, val, )) p.start() # 运行Process p.join() # 等待Process运行结束
最终运行结果
=====Process运行前======= [elements]:1 3 5 7 9 11 13 15 17 19 [Value]:0.0 =====Process运行后======= [elements]:2 6 10 14 18 22 26 30 34 38 [Value]:1.0
在某些特定的场景下要共享string类型,方式如下:
from ctypes import c_char_p str_val = Value(c_char_p, b"Hello World")
关于Share Memory支持的更多类型,可以查看module-multiprocessing.sharedctypes。
Server process
此种方式通过创建一个Server process来管理python object,然后其他process通过代理来访问这些python object。相较于share memory,它支持任意类型的共享,包括:list、dict、Namespace等。这里以dict和list举一个例子:from multiprocessing import Process, Manager
def func(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
print("=====Process运行前=======")
print(d)
print(l)
p = Process(target=func, args=(d, l))
p.start()
p.join()
print("=====Process运行后=======")
print(d)
print(l)运行结果如下
=====Process运行前=======
{}
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
=====Process运行后=======
{1: '1', '2': 2, 0.25: None}
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]进程间通讯
众所周知,并发编程中应该尽量避免共享变量,多进程更是如此。在这种情况下,多进程间的通讯就要用到Queue和
Pipe。
Queue
Queue是一种线程、进程安全的先进先出的队列。使用中,首先定义Queuefrom multiprocessing import Queue queue = Queue()
然后将需要处理的数据放入Queue中
elements = [i for i in range(100)] for i in elements: queue.put(i)
然后创建子进程
process
from multiprocessing import Process process = Process(target=func, args=(queue, ))
其中
func是子进程处理数据的逻辑。
from queue import Empty
def func(queue):
buff = []
while True:
try:
ele = queue.get(block=True, timeout=1)
buff.append(str(ele))
except Empty:
print(" ".join(buff))
print("Queue has been empty.....")
break使用
queue.get时,若Queue中没有数据,则会抛出queue.Empty错误。值得注意的是,在使用
queue.get()时一定要设置
block=True和
timeout,否则它会一直等待,直到queue中放入数据(刚开始用的时候,我一直奇怪为什么程序一直处在等待状态)。运行结果
=====单进程====== 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 Queue has been empty.....
Pipe
Pipe是一种管道,一端输入,一端输出。在multiprocess中,可以通过Pipe()函数来定义,返回
send和
recv的connection。使用中,先定义
from multiprocessing import Pipe parent_conn, child_conn = Pipe()
然后一端放入数据,另一端就可以接受数据了
from multiprocessing import Process def f(conn): conn.send([42, None, 'hello']) conn.close() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) p.join()
输出结果
[42, None, 'hello']
另外,值得注意的是,若两个或更多进程同时从管道一端读或写数据,会导致管道中的数据corrupt。为了直观的理解这种情况,这里举一个例子,即在主进程将数据放入管道,在子进程从管道中读出数据,并打印结果。区别之处在于,子进程的数量。首先将数据放入管道:
def func(conn):
a = conn.recv()
print(a)
parent, child = Pipe()
child.send("Hello world...")然后开启子进程
print("======单进程========")
p = Process(target=func, args=(parent, ))
p.start()
p.join()
print("======多进程========")
num_process = 2
ps = [Process(target=func, args=(parent, )) for _ in range(num_process)]
for p in ps:
p.start()
for p in ps:
p.join()输出结果
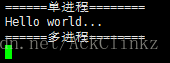
多进程并未按照预想的输出两个Hello World,而是处于死锁的状态。
例子
关于Queue和Pipe的用法讲了这么多,下面做一个小练习,内容是:利用多线程从文件中读取数据,处理后将数据保存到另外一个文件中。具体方法如下:1. 开辟一个子进程,从文件中读取数据,并将数据存入Queue中
2. 开辟多个子进程,从Queue中读取数据,处理数据,并将数据放入管道一端(注意加锁)
3. 开辟一个子进程,从管道另一端获取数据,并将数据写入文件中
0.导包
from multiprocessing import Process, Array, Queue, Value, Pipe, Lock from queue import Empty import sys
1.读取数据
def read_file(fin, work_queue):
for line in fin:
i = int(line.strip("\n"))
work_queue.put_nowait(i)其中work_queue用于连通“读数据的进程”和“处理数据的进程”。
2.处理数据
def worker_func(work_queue, conn, lock, index):
while True:
try:
ele = work_queue.get(block=True, timeout=0.5) + 1
with lock:
conn.send(ele)
except Empty:
print("Process-{} finish...".format(index))
conn.send(-1)
break从队列中读取数据,直到队列中的数据全被取走。当Queue中不存在数据时,向queue放入终止符(-1),告诉后面的进程,前面的人任务已经完成。
3.写数据
def write_file(conn, fout, num_workers): record = 0 while True: val = conn.recv() if val == -1: record += 1 else: print(val, file=fout) fout.flush() if record == num_workers: break
当写进程收到特定数量终止符(-1)时,写进程就终止了。
4.执行
path_file_read = "./raw_data.txt"
path_file_write = "./data.txt"
with open(path_file_read) as fin, \
open(path_file_write, "w") as fout:
queue = Queue()
parent, child = Pipe()
lock = Lock()
read_Process = Process(target=read_file, args=(fin, queue, ))
worker_Process = [Process(target=worker_func, args=(queue, parent, lock, index, ))
for index in range(3)]
write_Process = Process(
target=write_file, args=(child, fout, len(worker_Process), ))
read_Process.start()
for p in worker_Process:
p.start()
write_Process.start()
print("read....")
read_Process.join()
print("worker....")
for p in worker_Process:
p.join()
print("write....")
write_Process.join()输入/输出
打印错行
在使用多进程中,你会发现打印的结果发生错行。这是因为python的print函数是线程不安全的,从而导致错行。解决方法也很简单,给print加一把锁就好了,方式如下from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()无法打印日志信息
刚开始用多进程时,经常会出现日志信息无法打印的情况。其实问题很简单。在多进程中,打印内容会存在缓存中,直到达到一定数量才会打印。解决这个问题,只需要加上import sys sys.stdout.flush() sys.stderr.flush()
例如上面的例子,应该写成
import sys
def f(l, i):
l.acquire()
try:
print('hello world', i)
sys.stdout.flush() # 加入flush
finally:
l.release()总结
以上就是我在使用multiprocessing遇到的问题。
相关文章推荐
- python 使用multiprocessing需要注意的问题
- 新手使用python常见问题
- 使用Python+Selenium过程中中常见的问题汇总
- 在windows下python3使用multiprocessing.Pool时出现的问题
- python 2.7 类中使用多进程(multiprocessing)执行类函数时的问题
- Python安装与使用的常见问题
- 使用python_pep8常见问题记录
- Python之队列queue模块使用 常见问题与用法
- Python 使用技巧 常见问题
- python学习笔记1——python 中 Tkinder 使用常见问题
- Python之队列queue模块使用 常见问题与用法
- hibernate使用中常见的问题
- ADSL宽带使用过程中常见的一些问题
- 使用ASP编程常见问题解答
- 关于 python 中使用 lambda 表达式的问题
- 使用Axis部署Web服务时的常见问题及其解决方法(转)
- 使用Apache Axis部署 Web服务时的常见问题及其解决方法
- asp.net使用常见问题
- 使用Axis部署Web服务时的常见问题及其解决方法(转)
- ODAC使用指南 (一)ODAC常见问题集