Python高级——正则表达式 re模块 2.高级应用
2017-11-03 18:11
567 查看
re模块的高级应用
1、search
执行正则表达式搜索,(只用填写要搜索的数字类型和重复次数)并且在搜索结束后返回所匹配到的串,只返回第一次匹配到的结果求出帖子阅览的次数:
| >>> import re >>> res = re.search(r"\d+","当前浏览量是8808次") >>> res.group() '8808' |
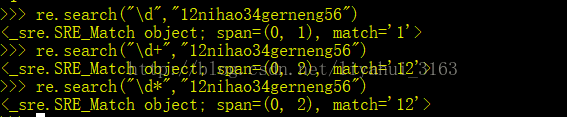
倘若用search方法查找多个数据,则只返回一个数据,其余的数据不会返回,这是因为search方法在找到第一个满足条件的数据后,不会再继续查找。请看如下例子,“\d” 查找一位数字,"\d+"查找一位以上数字,"\d*"查找0到多个数字,但是只返回了第一个为数字数据:
那么若要返回多个数据,我们该怎么办呢?这时就用到了findall( )方法.
2、findall和finditer
匹配所有的对象,返回一个列表| >>> re.findall(r"\d+","1 当前浏览量是8808次,回帖人数是200人") ['1', '8808', '200'] |

但是在实际应用中若数据较为庞大,都要以列表的形式全部返回吗?这样是非常占用内存的. 可以使用finditer()方法:
finditer : 但是返回一个迭代器iterator,这个iterator yield match objects.返回顺序、内容和re.findall()相同
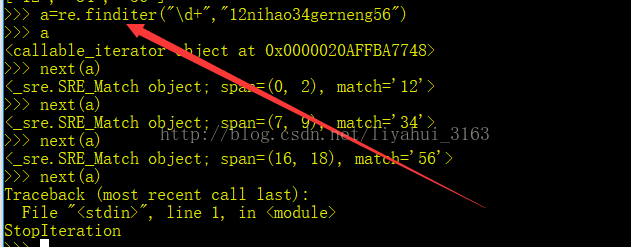
下面是finditer方法,此时用变量a接住,打印a可以看到是callable_iterator即可调用的迭代器,然后用next()方法依次输出结果:
这样做的目的在很大程度上节约 了内存空间.
3、sub
实现查找替换,用法:re.sub(“要替换的对象”,“新值”,str)| >>> re.sub(r"\d+","1024","当前浏览量是8808次") '当前浏览量是1024次' 还可使用函数来操作匹配到的对象 def add(temp): return str(int(temp.group())+1) re.sub(r"\d+",add,"当前浏览量是8808次,200") 结果为:'当前浏览量是8809次,201' |

4、split
分割字符串,结果返回列表:用法:re.split(“分割依据”,str)| a =re.split(" ,","你好,我是a,他是b,你是?") |

5、compile
compile用来编译正则表达式模式字符串,并生成Regular Expression Objects。| compile(pattern, flags=0) Compile a regular expression pattern, returning a pattern object. |
Ø re.I(IGNORECASE)忽略大小写,括号内是完整的写法
Ø re.M(MULTILINE)多行模式,改变^和$的行为
Ø re.S(DOTALL)点可以匹配任意字符,包括换行符
Ø re.L(LOCALE)做本地化识别的匹配,不推荐使用
Ø re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
Ø re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
| import re str = "LIjianhongJgd" p = re.compile("Li",re.I) # 表示li或略大小写,即LI、li、Li、lI都能匹配 p.match(str) 结果如下: <_sre.SRE_Match object; span=(0, 2), match='LI'> |
在以上方法中,最常用的为re.I方法,即忽略字母大小写:
例如:
a = re.compile(“aBc”,re.I) # 这是a相当于原来的re,比之前多了一个不区分大小写的功能
a.match(str) # 倘若str =“AbC”,也依然能够匹配。贪婪与懒惰
在Python中正则默认是贪婪模式(个别语言中也可能是非贪婪模式),贪婪模式就是总会尝试匹配更多的字符。非贪婪模式则反之,总是尝试匹配尽可能少的字符。
在*、?、+、{m,n}后面加上?,可以将贪婪模式变成非贪婪模式。
| 表5.懒惰限定符 | |
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| >>> re.match(r"this .*","this is a number 56-89-89-458-12531") <_sre.SRE_Match object; span=(0, 35), match='this is a number 56-89-89-458-12531'> >>> re.match(r"this .*?","this is a number 56-89-89-458-12531") <_sre.SRE_Match object; span=(0, 5), match='this '> >>> re.match(r".+(\d+-\d+)","this is a number 56-89-89-458-12531") 结果为: <_sre.SRE_Match object; span=(0, 35), match='this is a number 56-89-89-458-12531'> >>> re.match(r".+(\d+-\d+?)","this is a number 56-89-89-458-12531") 结果为: <_sre.SRE_Match object; span=(0, 31), match='this is a number 56-89-89-458-1'> |

相关文章推荐
- python应用regex正则表达式模块re
- Python高级——正则表达式 re模块1.match方法
- python全栈开发-re模块(正则表达式)应用(字符串的处理)
- python应用regex正则表达式模块re
- python正则表达式re模块语法
- Python之re(正则表达式)模块小结
- python中re正则表达式模块学习
- python正则表达式re模块详细介绍--转载
- Python基础(13)_python模块之re模块(正则表达式)
- Python re模块 正则表达式
- Python中re(正则表达式)模块学习
- Python数据分析学习-re正则表达式模块
- Python的re模块正则表达式操作
- python基础之正则表达式和re模块
- python之re模块通过正则表达式实现截取
- Python 正则表达式 RE模块的使用方法
- Python中re(正则表达式)模块学习
- python内置正则表达式(re)模块官方文档简要中文版
- Python中正则表达式(re模块)的使用
- Python之re模块 —— 正则表达式操作