吴恩达【深度学习工程师】学习笔记(六)
2017-11-03 10:44
302 查看
吴恩达【深度学习工程师】专项课程包含以下五门课程:
1、神经网络和深度学习;
2、改善深层神经网络:超参数调试、正则化以及优化;
3、结构化机器学习项目;
4、卷积神经网络;
5、序列模型。
今天介绍《改善深层神经网络:超参数调试、正则化以及优化》系列第一讲:深度学习的实用层面。
主要内容:
1、训练/开发/测试集;
2、偏差/方差;
3、常用的几种正则化方法;
4、梯度消失和梯度爆炸.
一般地,我们将所有的样本数据分成三个部分:训练/开发/测试集。训练集用来训练算法模型;开发集用来验证算法的表现;测试集用来测试算法的实际表现,作为该算法的无偏估计。
1)、机器学习中,由于样本量小(例如:10000个样本),通常设置训练/开发/测试集的比例为:60%、20%、20% 或者 70%、0%、30%
较为合理。
2)、深度学习中,由于样本量超大(例如:10 000 000个样本),通常设置训练/开发/测试集的比例为:98%、1%、1%
或者 99%、0.5%、0.5%较为合理 。
在深度学习中,务必保障训练集/开发集/测试集来自于同一数据分布。
如果没有测试集也是可以的。测试集的主要目标是进行无偏估计。我们可以通过训练集训练不同的算法模型,然后分别在开发集上进行验证,根据结果选择最好的算法模型。
在机器学习算法中,偏差和方差对应着欠拟合和过拟合,是对立的,我们常常需要在偏差和方差之间进行权衡。
而在深度学习中,我们可以同时减小偏差和方差,构建最佳神经网络模型。
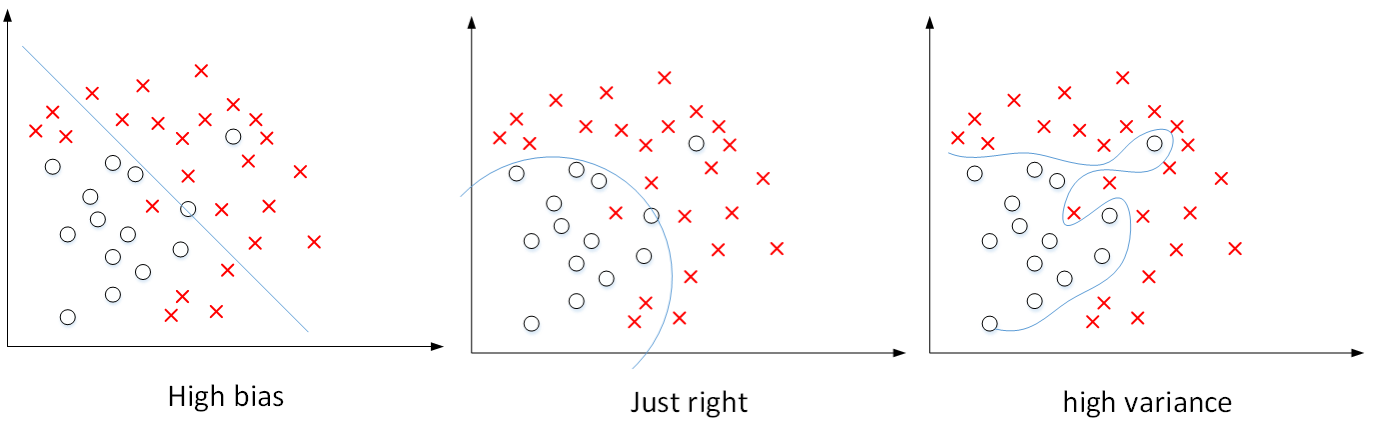
在深度学习中,我们可以通过两个数值:训练集error和开发集error来理解偏差和方差。
1)、训练集error为1%,而开发集error为6%,说明该模型对训练样本可能存在过拟合,模型泛化能力不强,是高方差的表现;
2)、训练集error为5%,而开发集error为6%,说明该模型对训练样本存在欠拟合,是高偏差的表现;
3)、训练集error为5%,而开发集 error为10%,说明模型既存在高偏差也存在高方差(可以理解成部分欠拟合,部分过拟合);
4)、假设训练集error为0.5%,而开发error为1%,即低偏差和低方差,是最理想的情况。
深度学习中最重要的一个问题就是避免出现高偏差和高方差。
1)、减少高偏差的常用方法是增加神经网络的隐层数、神经元数,延长训练时间,增加模型复杂度等。
2)、减少高方差的常用方法是增加训练样本量,加大正则化程度,增加模型复杂度等。
在深度学习模型中,L2 正则化的表达式为:
J(w[1],b[1],⋯,w[L],b[L])=1m∑i=1mL(y^(i),y(i))+λ2m∑l=1L||w[l]||2
||w[l]||2=∑i=1n[l]∑j=1n[l−1](w[l]ij)2
通常,我们把||w[l]||2称为Frobenius范数,记为||w[l]||2F。一个矩阵的Frobenius范数就是计算所有元素平方和再开方,如下所示:
||A||F=∑i=1m∑j=1n|aij|2−−−−−−−−−−
⎷
|
由于加入了正则化项,梯度下降算法中的dw[l]计算表达式要做如下修改:
dw[l]=dw[l]before+λmw[l]
w[l]:=w[l]−α⋅dw[l]
L2
正则化也被称做权重衰减。这是因为,由于加上了正则项,dw[l]有个增量,在更新w[l]的时候,会多减去这个增量,使得w[l]比没有正则项的值要小一些。不断迭代更新,不断地减小。
w[l]:===w[l]−α⋅dw[l]w[l]−α⋅(dw[l]before+λmw[l])(1−αλm)w[l]−α⋅dw[l]before
其中,(1−αλm)<1。
为什么正则化能够有效避免高方差,防止过拟合呢?
如下图所示为一个4层神经网络对应的三种不同模型 (高偏差/最佳/高方差):
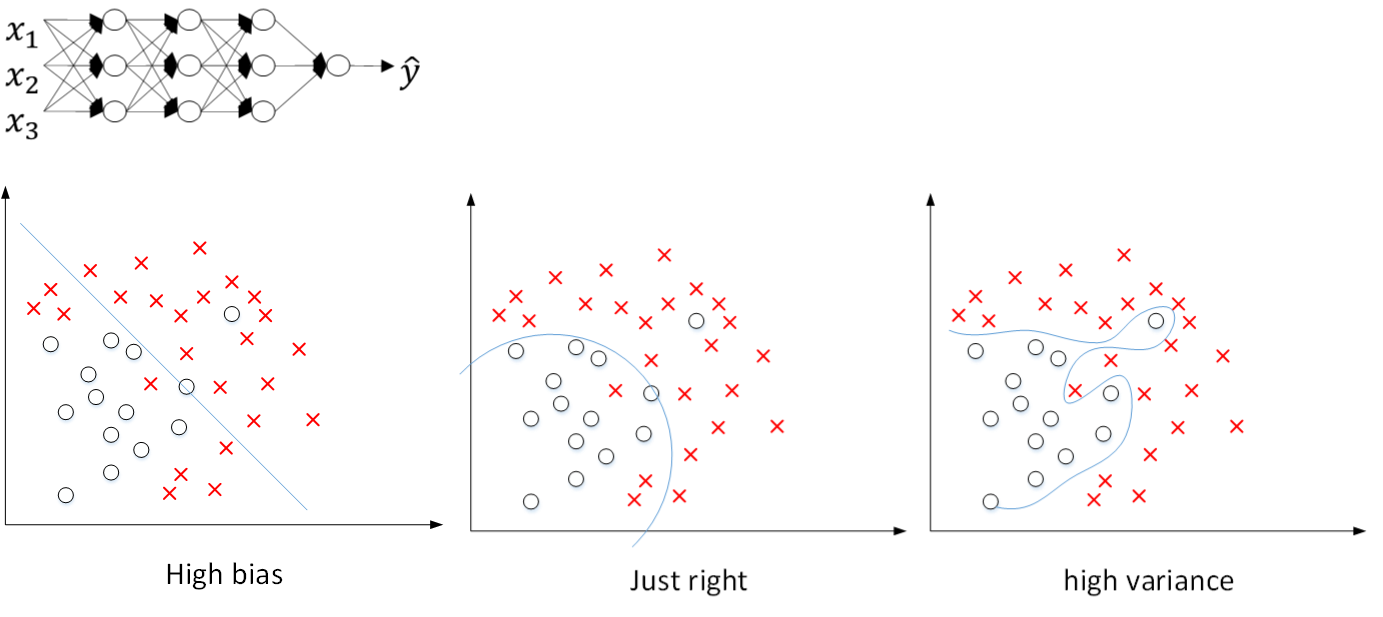
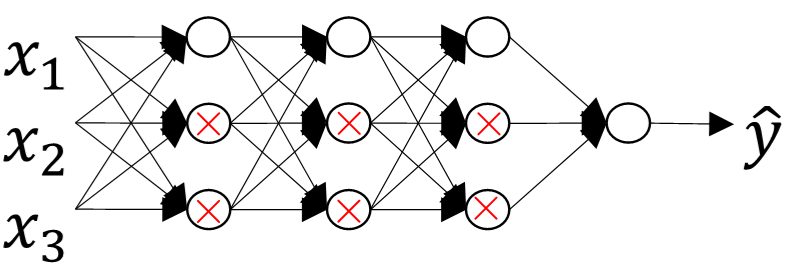
在未使用正则化的情况下,我们得到的分类超平面可能是类似上图右侧的过拟合。但是,如果使用L2 正则化,当λ很大时,w[l]≈0。w[l]近似为零,意味着该神经网络模型中的某些神经元实际作用很小,可以忽略。等同于将某些神经元给忽略掉了。这样原本过于复杂的神经网络模型就变得非常简单了。如下图所示,整个简化的神经网络模型变成了一个逻辑回归模型。问题就从高方差变成了高偏差了。
因此,选择合适的λ值,就能够同时避免高偏差和高方差,得到最佳模型。
Dropout通过每次迭代训练时,随机选择不同的神经元,相当于每次都在不同的神经网络上进行训练,类似机器学习中Bagging的方法,能够防止过拟合。
对于某个神经元来说,某次训练时,它的某些输入在dropout的作用被过滤了。而在下一次训练时,又有不同的某些输入被过滤。经过多次训练后,某些输入被过滤,某些输入被保留。这样,该神经元就不会受某个输入非常大的影响,影响被均匀化了。也就是说,对应的权重w不会很大。这从从效果上来说,与L2 regularization是类似的,都是对权重w进行“惩罚”,减小了w的值。
Dropout每次丢掉一定数量的隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其他的神经元(指层与层之间相连接的神经元),使神经网络更加能学习到与其他神经元之间的更加健壮robust的特征。
需要注意的是,训练阶段才会使用dropout,测试和实际应用阶段不能进行dropout。
在使用dropout的时候,不同隐藏层的dropout系数keep_prob可以不同。一般来说,神经元越多的隐藏层,keep_out可以设置得小一些.,例如0.5;神经元越少的隐藏层,keep_out可以设置的大一些,例如0.8,设置是1。实际应用中,不建议对输入层进行dropout。
一种方法是增加训练样本数量。但是通常成本较高,难以获得额外的训练样本。
我们可以对已有的训练样本进行一些处理来“制造”出更多的样本,称为data augmentation。例如图片识别问题中,可以对已有的图片进行水平翻转、垂直翻转、任意角度旋转、缩放或扩大等等。
如下图所示,这些处理都能“制造”出新的训练样本。虽然这些是基于原有样本的,但是对增大训练样本数量还是有很有帮助的,不需要增加额外成本,却能起到防止过拟合的效果。

还有一种方法是early stopping。一个神经网络模型随着迭代训练次数增加,训练集error一般是单调减小的,而开发集error 先减小,之后又增大。即随着训练次数的增多,模型会对训练样本拟合的越来越好,但是对验证集拟合效果逐渐变差,即发生了过拟合。因此,迭代训练次数不是越多越好,可以通过训练集error和开发集error随着迭代次数的变化趋势,选择合适的迭代次数。
在训练神经网络时,标准化输入可以提高训练的速度。标准化输入就是对训练数据集进行归一化的操作,即将原始数据减去其均值μ后,再除以其方差σ2
μ=1m∑i=1mX(i)
σ2=1m∑i=1m(X(i))2
X:=X−μσ2
以二维平面为例,下图展示了其归一化过程:
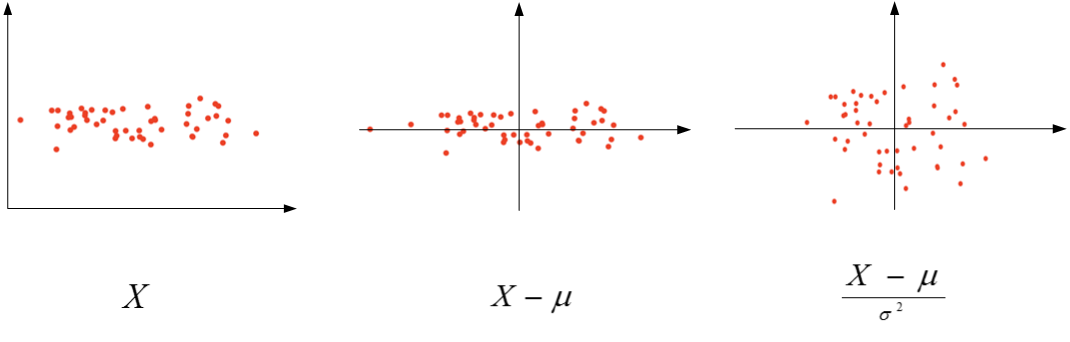
由于训练集进行了标准化处理,那么对于测试集或在实际应用时,应该使用同样的μ和σ2对其进行标准化处理。这样保证了训练集合测试集的标准化操作一致。
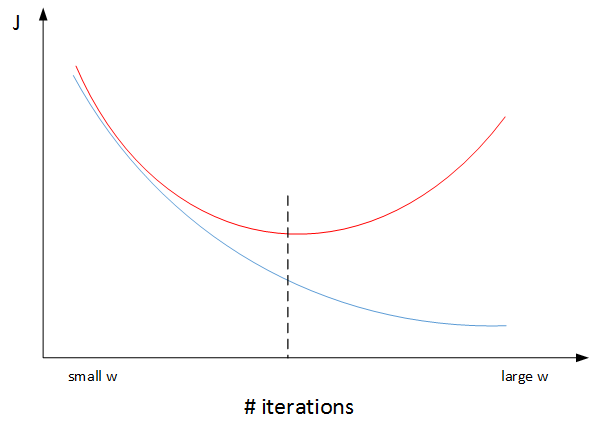
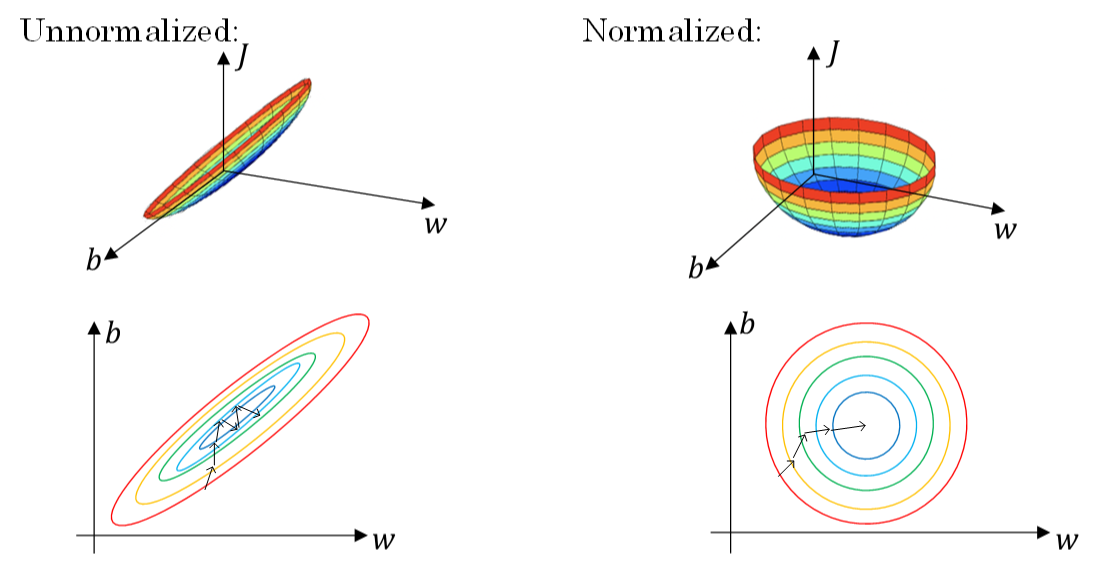
之所以要对输入进行标准化操作,主要是为了让所有输入归一化同样的尺度上,方便进行梯度下降算法时能够更快更准确地找到全局最优解。假如输入特征是二维的,且x1的范围是[1,1000],x2的范围是[0,1]。如果不进行标准化处理,x1与x2之间分布极不平衡,训练得到的w1和w2也会在数量级上差别很大。这样导致的结果是代价函数与w和b的关系可能是一个非常细长的椭圆形碗。对其进行梯度下降算法时,由于w1和w2数值差异很大,只能选择很小的学习因子α,来避免J发生振荡。一旦α较大,必然发生振荡,J不再单调下降。
如果进行了标准化操作,x1与x2分布均匀,w1和w2数值差别不大,得到的代价函数与w和b的关系是类似圆形碗。对其进行梯度下降算法时,α可以选择相对大一些,且J一般不会发生振荡,保证了J是单调下降的。如下右图所示。
当训练一个 隐层非常多的神经网络时,计算得到的梯度值可能非常小或非常大。
如下图所示:

为了便于分析,我们令各层的激活函数为线性函数,即g(Z)=Z。且忽略各层常数项b的影响,令b全部为零。那么,该网络的预测输出Y^为:
Y^=W[L]W[L−1]W[L−2]⋯W[3]W[2]W[1]X
如果各层权重W[l]的元素都稍大于1,例如1.5,则预测输出Y^将正比于1.5L。L越大,Y^越大,且呈指数型增长。我们称之为数值爆炸。相反,如果各层权重W[l]的元素都稍小于1,例如0.5,则预测输出Y^将正比于0.5L。网络层数L越多,Y^呈指数型减小。我们称之为数值消失。
改善梯度消失或梯度爆炸的方法是:对权重w进行一些初始化处理。
深度神经网络模型中,以单个神经元为例,该层(l)的输入个数为n,其输出为:
z=w1x1+w2x2+⋯+wnxn
a=g(z)

这里忽略了常数项b。为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小才好。这样能够保证z不会过大。一种方法是在初始化w时,令其方差为1n。相应的python伪代码为:
[/code]
如果激活函数是tanh,一般选择上面的初始化方法。
如果激活函数是ReLU,权重w的初始化一般令其方差为2n:
[/code]
除此之外,Yoshua Bengio提出了另外一种初始化w的方法,令其方差为2n[l−1]n[l]:
[/code]
至于选择哪种初始化方法因人而异,可以根据不同的激活函数选择不同方法。
反向传播神经网络有一项重要的测试是梯度检查(gradient checking)。目的是检查验证反向传播过程中梯度下降算法是否正确。
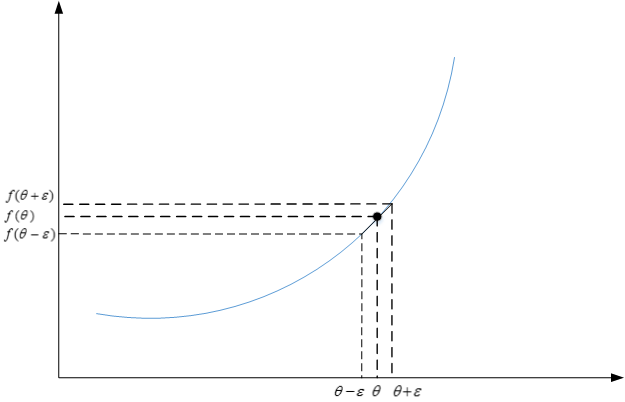
利用微分思想,函数f在点θ处的梯度可以表示成:
g(θ)=f(θ+ε)−f(θ−ε)2ε
其中,ε>0,且足够小。
梯度检查首先要做的是分别将W[1],b[1],⋯,W[L],b[L]这些矩阵构造成一维向量,然后将这些一维向量组合起来构成一个更大的一维向量θ。这样cost
function J(W[1],b[1],⋯,W[L],b[L])就可以表示成J(θ)。
然后将反向传播过程通过梯度下降算法得到的dW[1],db[1],⋯,dW[L],db[L]按照一样的顺序构造成一个一维向量dθ。dθ的维度与θ一致。
接着利用J(θ)对每个θi计算近似梯度,其值与反向传播算法得到的dθi相比较,检查是否一致。例如,对于第i个元素,近似梯度为:
dθapprox[i]=J(θ1,θ2,⋯,θi+ε,⋯)−J(θ1,θ2,⋯,θi−ε,⋯)2ε
计算完所有θi的近似梯度后,可以计算dθapprox与dθ的欧氏(Euclidean)距离来比较二者的相似度。公式如下:
||dθapprox−dθ||2||dθapprox||2+||dθ||2
一般来说,如果欧氏距离越小,例如10−7,甚至更小,则表明dθapprox与dθ越接近,即反向梯度计算是正确的。如果欧氏距离较大,例如10−5,则表明梯度计算可能出现问题,需要再次检查是否有bug存在。
在进行梯度检查的过程中有几点需要注意的地方:
不要在整个训练过程中都进行梯度检查,仅仅作为debug使用。
如果梯度检查出现错误,找到对应出错的梯度,检查其推导是否出现错误。
注意不要忽略正则化项,计算近似梯度的时候要包括进去。
梯度检查时关闭dropout,检查完毕后再打开dropout。
随机初始化时运行梯度检查,经过一些训练后再进行梯度检查(不常用)。
1、神经网络和深度学习;
2、改善深层神经网络:超参数调试、正则化以及优化;
3、结构化机器学习项目;
4、卷积神经网络;
5、序列模型。
今天介绍《改善深层神经网络:超参数调试、正则化以及优化》系列第一讲:深度学习的实用层面。
主要内容:
1、训练/开发/测试集;
2、偏差/方差;
3、常用的几种正则化方法;
4、梯度消失和梯度爆炸.
1、训练/开发/测试集
一般地,我们将所有的样本数据分成三个部分:训练/开发/测试集。训练集用来训练算法模型;开发集用来验证算法的表现;测试集用来测试算法的实际表现,作为该算法的无偏估计。1)、机器学习中,由于样本量小(例如:10000个样本),通常设置训练/开发/测试集的比例为:60%、20%、20% 或者 70%、0%、30%
较为合理。
2)、深度学习中,由于样本量超大(例如:10 000 000个样本),通常设置训练/开发/测试集的比例为:98%、1%、1%
或者 99%、0.5%、0.5%较为合理 。
在深度学习中,务必保障训练集/开发集/测试集来自于同一数据分布。
如果没有测试集也是可以的。测试集的主要目标是进行无偏估计。我们可以通过训练集训练不同的算法模型,然后分别在开发集上进行验证,根据结果选择最好的算法模型。
2、偏差/方差
在机器学习算法中,偏差和方差对应着欠拟合和过拟合,是对立的,我们常常需要在偏差和方差之间进行权衡。而在深度学习中,我们可以同时减小偏差和方差,构建最佳神经网络模型。
在深度学习中,我们可以通过两个数值:训练集error和开发集error来理解偏差和方差。
1)、训练集error为1%,而开发集error为6%,说明该模型对训练样本可能存在过拟合,模型泛化能力不强,是高方差的表现;
2)、训练集error为5%,而开发集error为6%,说明该模型对训练样本存在欠拟合,是高偏差的表现;
3)、训练集error为5%,而开发集 error为10%,说明模型既存在高偏差也存在高方差(可以理解成部分欠拟合,部分过拟合);
4)、假设训练集error为0.5%,而开发error为1%,即低偏差和低方差,是最理想的情况。
深度学习中最重要的一个问题就是避免出现高偏差和高方差。
1)、减少高偏差的常用方法是增加神经网络的隐层数、神经元数,延长训练时间,增加模型复杂度等。
2)、减少高方差的常用方法是增加训练样本量,加大正则化程度,增加模型复杂度等。
3、L2正则化
在深度学习模型中,L2 正则化的表达式为:J(w[1],b[1],⋯,w[L],b[L])=1m∑i=1mL(y^(i),y(i))+λ2m∑l=1L||w[l]||2
||w[l]||2=∑i=1n[l]∑j=1n[l−1](w[l]ij)2
通常,我们把||w[l]||2称为Frobenius范数,记为||w[l]||2F。一个矩阵的Frobenius范数就是计算所有元素平方和再开方,如下所示:
||A||F=∑i=1m∑j=1n|aij|2−−−−−−−−−−
⎷
|
由于加入了正则化项,梯度下降算法中的dw[l]计算表达式要做如下修改:
dw[l]=dw[l]before+λmw[l]
w[l]:=w[l]−α⋅dw[l]
L2
正则化也被称做权重衰减。这是因为,由于加上了正则项,dw[l]有个增量,在更新w[l]的时候,会多减去这个增量,使得w[l]比没有正则项的值要小一些。不断迭代更新,不断地减小。
w[l]:===w[l]−α⋅dw[l]w[l]−α⋅(dw[l]before+λmw[l])(1−αλm)w[l]−α⋅dw[l]before
其中,(1−αλm)<1。
为什么正则化能够有效避免高方差,防止过拟合呢?
如下图所示为一个4层神经网络对应的三种不同模型 (高偏差/最佳/高方差):
在未使用正则化的情况下,我们得到的分类超平面可能是类似上图右侧的过拟合。但是,如果使用L2 正则化,当λ很大时,w[l]≈0。w[l]近似为零,意味着该神经网络模型中的某些神经元实际作用很小,可以忽略。等同于将某些神经元给忽略掉了。这样原本过于复杂的神经网络模型就变得非常简单了。如下图所示,整个简化的神经网络模型变成了一个逻辑回归模型。问题就从高方差变成了高偏差了。
因此,选择合适的λ值,就能够同时避免高偏差和高方差,得到最佳模型。
4、Dropout正则化
Dropout通过每次迭代训练时,随机选择不同的神经元,相当于每次都在不同的神经网络上进行训练,类似机器学习中Bagging的方法,能够防止过拟合。对于某个神经元来说,某次训练时,它的某些输入在dropout的作用被过滤了。而在下一次训练时,又有不同的某些输入被过滤。经过多次训练后,某些输入被过滤,某些输入被保留。这样,该神经元就不会受某个输入非常大的影响,影响被均匀化了。也就是说,对应的权重w不会很大。这从从效果上来说,与L2 regularization是类似的,都是对权重w进行“惩罚”,减小了w的值。
Dropout每次丢掉一定数量的隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其他的神经元(指层与层之间相连接的神经元),使神经网络更加能学习到与其他神经元之间的更加健壮robust的特征。
需要注意的是,训练阶段才会使用dropout,测试和实际应用阶段不能进行dropout。
在使用dropout的时候,不同隐藏层的dropout系数keep_prob可以不同。一般来说,神经元越多的隐藏层,keep_out可以设置得小一些.,例如0.5;神经元越少的隐藏层,keep_out可以设置的大一些,例如0.8,设置是1。实际应用中,不建议对输入层进行dropout。
5、其他正则化方法
一种方法是增加训练样本数量。但是通常成本较高,难以获得额外的训练样本。我们可以对已有的训练样本进行一些处理来“制造”出更多的样本,称为data augmentation。例如图片识别问题中,可以对已有的图片进行水平翻转、垂直翻转、任意角度旋转、缩放或扩大等等。
如下图所示,这些处理都能“制造”出新的训练样本。虽然这些是基于原有样本的,但是对增大训练样本数量还是有很有帮助的,不需要增加额外成本,却能起到防止过拟合的效果。
还有一种方法是early stopping。一个神经网络模型随着迭代训练次数增加,训练集error一般是单调减小的,而开发集error 先减小,之后又增大。即随着训练次数的增多,模型会对训练样本拟合的越来越好,但是对验证集拟合效果逐渐变差,即发生了过拟合。因此,迭代训练次数不是越多越好,可以通过训练集error和开发集error随着迭代次数的变化趋势,选择合适的迭代次数。
6、正则化输入
在训练神经网络时,标准化输入可以提高训练的速度。标准化输入就是对训练数据集进行归一化的操作,即将原始数据减去其均值μ后,再除以其方差σ2μ=1m∑i=1mX(i)
σ2=1m∑i=1m(X(i))2
X:=X−μσ2
以二维平面为例,下图展示了其归一化过程:
由于训练集进行了标准化处理,那么对于测试集或在实际应用时,应该使用同样的μ和σ2对其进行标准化处理。这样保证了训练集合测试集的标准化操作一致。
之所以要对输入进行标准化操作,主要是为了让所有输入归一化同样的尺度上,方便进行梯度下降算法时能够更快更准确地找到全局最优解。假如输入特征是二维的,且x1的范围是[1,1000],x2的范围是[0,1]。如果不进行标准化处理,x1与x2之间分布极不平衡,训练得到的w1和w2也会在数量级上差别很大。这样导致的结果是代价函数与w和b的关系可能是一个非常细长的椭圆形碗。对其进行梯度下降算法时,由于w1和w2数值差异很大,只能选择很小的学习因子α,来避免J发生振荡。一旦α较大,必然发生振荡,J不再单调下降。
如果进行了标准化操作,x1与x2分布均匀,w1和w2数值差别不大,得到的代价函数与w和b的关系是类似圆形碗。对其进行梯度下降算法时,α可以选择相对大一些,且J一般不会发生振荡,保证了J是单调下降的。如下右图所示。
7、梯度消失和梯度爆炸
当训练一个 隐层非常多的神经网络时,计算得到的梯度值可能非常小或非常大。如下图所示:
为了便于分析,我们令各层的激活函数为线性函数,即g(Z)=Z。且忽略各层常数项b的影响,令b全部为零。那么,该网络的预测输出Y^为:
Y^=W[L]W[L−1]W[L−2]⋯W[3]W[2]W[1]X
如果各层权重W[l]的元素都稍大于1,例如1.5,则预测输出Y^将正比于1.5L。L越大,Y^越大,且呈指数型增长。我们称之为数值爆炸。相反,如果各层权重W[l]的元素都稍小于1,例如0.5,则预测输出Y^将正比于0.5L。网络层数L越多,Y^呈指数型减小。我们称之为数值消失。
改善梯度消失或梯度爆炸的方法是:对权重w进行一些初始化处理。
深度神经网络模型中,以单个神经元为例,该层(l)的输入个数为n,其输出为:
z=w1x1+w2x2+⋯+wnxn
a=g(z)
这里忽略了常数项b。为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小才好。这样能够保证z不会过大。一种方法是在初始化w时,令其方差为1n。相应的python伪代码为:
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(1/n[l-1])1
[/code]
如果激活函数是tanh,一般选择上面的初始化方法。
如果激活函数是ReLU,权重w的初始化一般令其方差为2n:
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(2/n[l-1])1
[/code]
除此之外,Yoshua Bengio提出了另外一种初始化w的方法,令其方差为2n[l−1]n[l]:
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(2/n[l-1]*n[l])1
[/code]
至于选择哪种初始化方法因人而异,可以根据不同的激活函数选择不同方法。
8、梯度检查
反向传播神经网络有一项重要的测试是梯度检查(gradient checking)。目的是检查验证反向传播过程中梯度下降算法是否正确。利用微分思想,函数f在点θ处的梯度可以表示成:
g(θ)=f(θ+ε)−f(θ−ε)2ε
其中,ε>0,且足够小。
梯度检查首先要做的是分别将W[1],b[1],⋯,W[L],b[L]这些矩阵构造成一维向量,然后将这些一维向量组合起来构成一个更大的一维向量θ。这样cost
function J(W[1],b[1],⋯,W[L],b[L])就可以表示成J(θ)。
然后将反向传播过程通过梯度下降算法得到的dW[1],db[1],⋯,dW[L],db[L]按照一样的顺序构造成一个一维向量dθ。dθ的维度与θ一致。
接着利用J(θ)对每个θi计算近似梯度,其值与反向传播算法得到的dθi相比较,检查是否一致。例如,对于第i个元素,近似梯度为:
dθapprox[i]=J(θ1,θ2,⋯,θi+ε,⋯)−J(θ1,θ2,⋯,θi−ε,⋯)2ε
计算完所有θi的近似梯度后,可以计算dθapprox与dθ的欧氏(Euclidean)距离来比较二者的相似度。公式如下:
||dθapprox−dθ||2||dθapprox||2+||dθ||2
一般来说,如果欧氏距离越小,例如10−7,甚至更小,则表明dθapprox与dθ越接近,即反向梯度计算是正确的。如果欧氏距离较大,例如10−5,则表明梯度计算可能出现问题,需要再次检查是否有bug存在。
在进行梯度检查的过程中有几点需要注意的地方:
不要在整个训练过程中都进行梯度检查,仅仅作为debug使用。
如果梯度检查出现错误,找到对应出错的梯度,检查其推导是否出现错误。
注意不要忽略正则化项,计算近似梯度的时候要包括进去。
梯度检查时关闭dropout,检查完毕后再打开dropout。
随机初始化时运行梯度检查,经过一些训练后再进行梯度检查(不常用)。

相关文章推荐
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第六节:课程资源
- 吴恩达【深度学习工程师】学习笔记(二)
- 吴恩达【深度学习工程师】学习笔记(八)
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第三节:用神经网络进行监督学习
- 吴恩达【深度学习工程师】学习笔记(十一)
- 吴恩达【深度学习工程师】学习笔记(五)
- 吴恩达【深度学习工程师】学习笔记(三)
- 吴恩达【深度学习工程师】学习笔记(七)
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第二节:什么是神经网络
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第四节:为什么深度学习会兴起?
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第五节:关于这门课
- 吴恩达老师深度学习视频课笔记:单隐含层神经网络公式推导及C++实现(二分类)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-1)-- 机器学习策略(1)(转)
- 吴恩达深度学习视频笔记1-3:《神经网络和深度学习》之《浅层神经网络》
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-4)-- 深层神经网络(转载)
- 吴恩达深度学习笔记 4.1~4.8 深层神经网络
- 吴恩达深度学习笔记 course2 week3 超参数调试,Batch Norm,和程序框架
- 这份深度学习课程笔记获吴恩达点赞
- 吴恩达深度学习课程笔记之神经网络基础
- 吴恩达深度学习课程笔记 2.3逻辑回归cost function