DataWorks数据埋点的设计及未来发展的思考
2017-11-02 13:37
344 查看
什么是前端埋点?
马总曾经说过现在是DT时代(大数据的时代)。数据已经成为一家公司最宝贵的财富,越来越多的互联网公司开始重视数据的应用。数据应用的过程是:数据收集 -> 数据整理(数据同步)-> 数据分析 -> 数据可视化。
前端埋点是用户行为数据采集领域非常重要的手段,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。
当然前端埋点上报也不仅仅有用户行为数据的采集,还有一个很重要的领域——前端健康度分析。包括采集页面加载性能,js报错收集,接口出错上报,自定义测速等等。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
为什么要进行前端埋点
埋点可以帮助分析人员获取真正需要的业务数据及其附带信息,对产品发展、业务决策和指导运营有非常重要的作用。在不同场景下,业务人员关注的信息和角度可能不同。典型的应用场景如淘宝活动运营,以及PD和UED。前者注重来源渠道和广告效果,而后两者更在意产品本身流程和体验的优化。这就需要通过埋点采集到对应的数据,以数据为依据来做决策和判断。
打个比方,城市要提高一个路口的通过率,那必须要重新调整交通信号灯的逻辑。光看是不行的,我们需要同时拿到路口各个时间段和各个方向的车辆流动量,这就需要在相应的节点上安装摄像头和交通流量计数器。埋点同理。
DataWorks的产品和埋点需求
DataWorks是阿里集团内最大最优秀的一站式大数据平台,整合了大数据设计和开发、运维监控、数据集成、数据管理,数据安全,数据质量等产品,并打通算法平台pai,形成了完整的大数据闭环。
需求背景
目前整个DataWorks所有前端产品缺少一个统一化的埋点方案,导致产品和UED无法准确地拿到用户数据来辅助决策。鉴于此背景,我们在为DataWorks做埋点和数据上报的时候,遇到了不小的挑战。
需要上报的数据
UV/PV(支持单页应用)所有按钮链接的点击事件
导航点击事件
表格筛选表单的使用情况
操作系统和浏览器信息
前端性能数据
前端报错记录
接口返回时间
接口报错信息,包含errorCode,requestId等
碰到的问题
首先,DataWorks是一个数据平台,包含产品15+,涉及到的页面将近50个,如果使用传统埋点方式,工作量巨大。因为历史遗留问题,产品的前端技术栈不统一,有jquery、requirejs、react、angular1.x,还有一些自研的前端框架,导致无法使用统一的埋点规则进行数据采集上报。
DataWorks的很多产品都是复杂的单页应用,而且需求交互迭代特别频繁,对用户行为数据埋点上报的拓展性和灵活性有非常高的要求。
其他业务需求
业务上对用户的角色、BU等信息进行分析有需求,所以在上报的数据中需要带上当前用户信息及一些产品自定义的信息。能够有一个地方可以看到所有产品的PV/UV,及在线时长,流失率等指标。
针对定制化的需求,能够方便地对上报的数据进行抽取分析,并输出报表。
能够支持专有云的埋点上报。
埋点设计
设计原则
能够支持基础的PV/UV以及前端健康度的上报,也可以支持用户自定义上报。尽量做到无痕,或者尽可能少的代码改动。降低接入埋点的工作量。
能够提供快速的数据抽取分析的方法。
可以让开发者针对不同的产品,在每次数据采集的时候,传入自定义数据。例如,用户信息,项目信息等。
默认全部记录,可设置抽样上报,并提供开关,关闭埋点功能。
统一入口,比如在公共头里统一接入埋点,再对外暴露方法,让各个产品设置自己的埋点配置。
技术选型
集团内比较成熟的两个方案:aplus:可以进行采集用户的PV/UV,并统计页面的在线时长,流失率等指标,而且提供了页面可视化展示各项数据。
retcode:更专注于对前端健康度的监控和报警,并提供了灵活的自定义上报接口。另外retcode的源日志数据比较开放,更方便做后续的数据分析。
针对DataWorks的数据上报需求,我们决定使用retcode进行主要的数据上报,aplus也会默认接入(阿里的Nginx会默认在页面中插入aplus的js)。
但在埋点需求中有一项aplus和retcode都无法实现,就是“所有按钮链接的点击事件”。这个需求就需要使用到“无痕埋点”(在“无痕埋点”的场景下,数据监测工具一般倾向于在监测时捕获和发送尽可能多的事件和信息,而在数据处理后端进行触发条件匹配和统计计算等工作,以较好地支持关注点变更和历史数据回溯。)。
但因为DataWorks的产品技术栈不统一,尤其当下业界在react和angular框架的无痕埋点方向上基本属于空白状态。所以我设计了一套埋点机制,来实现不同前端框架的下的无痕埋点,并将采集到的事件和数据通过retcode进行数据上报。
架构设计
从结构上划分,分为底座和插件两大块。底座:负责插件的装载、数据的封装处理和上报。
插件:不同前端框架的埋点方案都基于规定好的数据格式开发插件,并按需插入到底座来实现埋点数据采集。
从功能上划分,底座总共分为三层,既数据采集层、数据处理层及数据传输层。
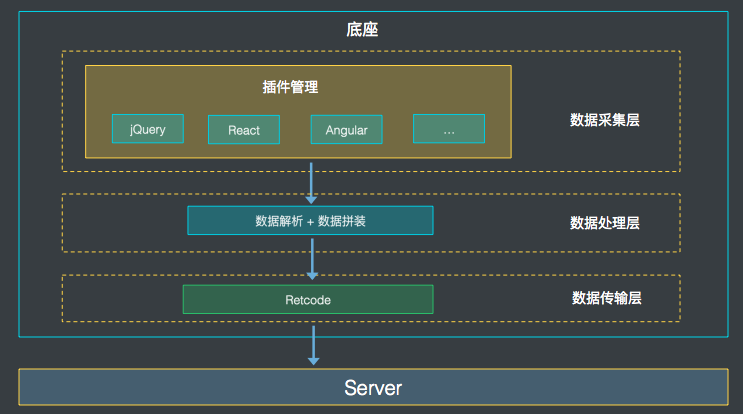
底座设计
上面讲到底座分为三层:数据采集层,提供了一整套的插件接入机制。底座自身并不提供数据采集的功能,它本身只是一个容器,允许各种插件按照一定的规则插入到底座中,提供数据采集的功能。
数据处理层:提供了数据的规范,各个插件需要依照该数据规范把采集到的数据进行包装(例如加入各个产品配置的业务数据),然后传给数据传输层。
数据传输层:封装retcode进行埋点上报。
这样设计的好处是底座不负责采集,采集的工作由插件实现。而插件机制又保证了整个埋点机制的拓展性,甚至未来其他的开发者也可以基于这套底座和规范,去开发各种前端框架的埋点上报。
插件设计
我们目前开发了jQuery、react及fetch的埋点采集插件。它们前端事件和请求数据的采集方案,主要是通过Hack通用的前端框架,在事件处理函数上做文章。具体Hack的方式下面会描述。优点:能够较为精确地定位到具体的选择元素以及其功能,并且可以结合框架的优势传递业务数据,更能满足我们在复杂业务场景下处理数据的需求。
缺点:必须要在执行用户代码之前执行我们的埋点代码。
jQuery的埋点方式:
第一步: 改写jQuery的事件绑定方法(如on,click,delegate等)第二部: 判断如果是click,则记录selector,并对回调函数做一层封装。
第三部:执行回调封装的时候,会把selector传入函数内,上报上去。
注: 这里selector需要注意区分,因为有可能是通过parent或者find找到的,我们需要根据selector以及prevObject来精确查找具体的元素。
React的埋点方式:
通过改写React.createElement,其中可以拿到组件传递的Property,通过Property可以进行判断,如果含有onClick事件的话,则在此事件中进行数据的上报操作。整个过程中可以上报Component名称以及Component的父子关系。
请求采集方案:
目前对于jQuery的Ajax。主要做法是修改ajax的beforeSend函数和complete函数,来对ajax进行统一的处理及上报。如果是fetch,则hack浏览器原生的fetch方法,来对请求进行包装,上报请求信息。
其他框架Angular、vue、backbone....
如果想使用我们的这套埋点机制,任何前端框架只需要遵循传输的数据格式,然后实现各自的点击事件采集即可。
解决的问题和优化
优化:1. 优化pv/uv数据的采集,由于用户在使用DataWorks时,页面不会关闭,导致PV/UV数据不准确。所以增加用户每日首次激活页面的时候也会进行PV/UV采集。
2. jQuery插件中,减少不必要的全局事件,例如绑在body上,用来隐藏右键下拉菜单的事件。
解决掉的问题:
1. retcode必须在页面文档流加载的时候引入,否则不会上报PV/UV和页面加载性能数据。这个问题很严重,因为我们的基础库是通过公共头统一引入的,这个时候文档流已经执行完毕,所以我们通过手动调用retcode提供的spm上报接口来实现PV/UV的上报。另外页面加载性能数据,也通过浏览器的PerformanceTiming API进行手动采集上报。
2. jQuery的on事件绑定方法,在hack的时候需要提取guid,并赋给hack的函数,否则off的时候会找不到对应的函数。
2. 推动七星阵支持retcode数据上报。
后期计划
本期主要目标在于产出数据,即实现对买点数据的采集、上报、汇总工作。后续工作可以从前端及后端数据处理两个方向进行发展。前端方向:
制作浏览器插件: 基于埋点数据,开发类似Udata的浏览器插件,能够帮助PD、UED、运营对页面上用户的行为数据有个直观的认识,从而支撑他们的产品设计和决策。这个插件的数据来源可以是实时数据,也可以是离线数据。
数据可视化: 与集团内部的一些自定义报表工具打通,能够快速方便得进行数据可视化展现。
后端数据处理方向:
1. 自动生成离线任务:DataWorks本身就是一整套的大数据平台,能够实现数据的抽取、分析和运维。后续将考虑搭建一套机制,能够自动的生成调度任务去帮用户进行数据分析。
即形成了 数据收集 -> 数据整理(数据同步)-> 数据分析 -> 数据可视化的闭环。
了解更多
http://click.aliyun.com/m/33996/

相关文章推荐
- DataWorks数据埋点的设计及未来发展的思考
- 我对职业规划和未来发展的一些思考
- VI设计的未来发展方向
- 我对职业规划和未来发展的一些思考
- 国内LINUX发展的现状与未来的思考一
- 数据存储行业的未来发展方向和趋势
- 关于类的数据成员的访问权限设计的一些思考(转)
- 以数据驱动页面为展现系统设计的思考
- (原创)我对未来的人类的发展,以及AI技术发展的一些思考。
- 关于类的数据成员的访问权限设计的一些思考
- 思考面向未来的架构设计
- 我对职业规划和未来发展的一些思考
- 关于多核的发展对网络游戏设计影响的一些思考
- 数据仓库专题(4)-分布式数据仓库事实表设计思考---讨论精华
- 天下数据深度解析大数据未来发展趋势
- 关于类的数据成员的访问权限设计的一些思考
- 改善代码设计 —— 组织好你的数据(Composing Data)
- 改善代码设计 —— 组织好你的数据(Composing Data)
- 深入解读:获Forrester大数据能力高评价的阿里云DataWorks思路与能力
- 基于数据的设计(Data-oriented design)