稀疏矩阵的三种存储方式
2017-11-01 16:23
155 查看
稀疏矩阵的三种存储方式
一,相关概念
㈠特殊矩阵:矩阵中存在大多数值相同的元,或非0元,且在矩阵中的分布有一定规律。
⒈对称矩阵:矩阵中的元素满足
aij=aji 1≤i,j≤n
⒉三角矩阵:上(下)三角矩阵指矩阵的下(上)三角(不包括对角线)中的元素均为常数c或0的n阶矩阵。
⒊对角矩阵(带状矩阵):矩阵中所有非0元素集中在主对角线为中心的区域中。
㈡稀疏矩阵:非0元素很少(≤ 5%)且分布无规律。
二,存储结构
1、对称矩阵
存储分配策略: 每一对对称元只分配一个存储单元,即只存储下三角(包括对角线)的元, 所需空间数为: n(n+1)/2。
存储分配方法: 用一维数组sa[n(n+1)/2]作为存储结构。
sa[k]与aij之间的对应关系为:
2、三角矩阵
也是一个n阶方阵,有上三角和下三角矩阵。下(上)三角矩阵是主对角线以上(下)元素均为零的n阶矩阵。设以一维数组sb[0..n(n+1)/2]作为n阶三角矩阵B的存储结构,仍采用按行存储方案,则B中任一元素bi,j和sb[k]之间仍然有如上的对应关系,只是还需要再加一个存储常数c的存储空间即可。如在下三角矩阵中,用n(n+1)/2的位置来存储常数。
对特殊矩阵的压缩存储实质上就是将二维矩阵中的部分元素按照某种方案排列到一维数组中,不同的排列方案也就对应不同的存储方案
2、稀疏矩阵
常见的有三元组表示法、带辅助行向量的二元组表示法(也即行逻辑链表的顺序表),十字链表表示法等。
1)、三元组表示法
三元组表示法就是在存储非零元的同时,存储该元素所对应的行下标和列下标。稀疏矩阵中的每一个非零元素由一个三元组(i,j,aij)唯一确定。矩阵中所有非零元素存放在由三元组组成的数组中。
在此,data域中表示非零元的三元组是以行序为主序顺序排列的。
以下看如何利用三元组表示法来实现矩阵的转置。
(1)按照b.data中三元组的次序依次在a.data中找出相应的三元组进行转置。换句话说,按照矩阵M的列序进行转置。为了找到M的每一列中所有的非零元素,需要对其三元组表a.data从第一行起整个扫描一遍。由于a.data是以M的行序为存放每个非零元的,由此得到的恰好是b.data应有的顺序。
2)、带辅助行向量的二元组表示法及十字链表表示法在下一节中学习介绍。
三、存储结构及C语言描述
1、三元组表示法
按照b矩阵中的行次序依次在a.data中找到相应的三元组进行转置。
快速转置:按照a.data中三元组的次序进行转置,并将转置后的三元组放到b.data中的恰当位置。
恰当位置的确定:首先计算M矩阵的每一列(即T的每一行)中非0元的个数,然后求得M矩阵每一列第一个非0元在b.data中的位置。
算法基本思想:
设置两个向量:
num[col]:第col列的非零元素个数。
cpot[col]:第col列第一个非零元在b.data中的恰当位置。
在转置过程中,指示该列下一个非零元在b.data中的位置。
1、num[col]的计算:
顺序扫描a.data三元组,累计各列非0元个数。
2、cpot[col]计算:
三元组表示代码:
2,行逻辑连接的顺序表
上面我们讨论的是稀疏矩阵的转置,现在我们讨论稀疏矩阵的相乘,相加,相减。如果预先知道不是稀疏矩阵,则用二维数组相乘法就可以了。如果是,则我们用来存储矩阵的结构称之为行逻辑连接的顺序表,就是加入一个行表来记录稀疏矩阵中每行的非零元素在三元组表中的起始位置。
在M.data和N.data中找到相应的各对元素进行相乘即可。此时矩阵的存储结构是
在此,我们引入rpos[row]用来指示矩阵N的第row行中第一个非零元在N.data中的序号,则rpos[row+1]-1指示矩阵的第row行中最后一个非零元在N.data中的序号。而最后一行中最后一个非零元在N.data的位置就是N.tu了。
如上图中,N的rpos值为:
带行逻辑链接的顺序表实现代码:
3,十字链表表示法
我们知道稀疏矩阵的三元组存储方式的实现很简单,每个元素有三个域分别是i,
j,
e。代表了该非零元的行号、列号以及值。那么在十字链表的存储方式下,首先这三个域是肯定少不了的,不然在进行很多操作的时候都要自己使用计数器,很麻
烦。而十字链表的形式大家可以理解成每一行是一个链表,而每一列又是一个链表。如图所示:
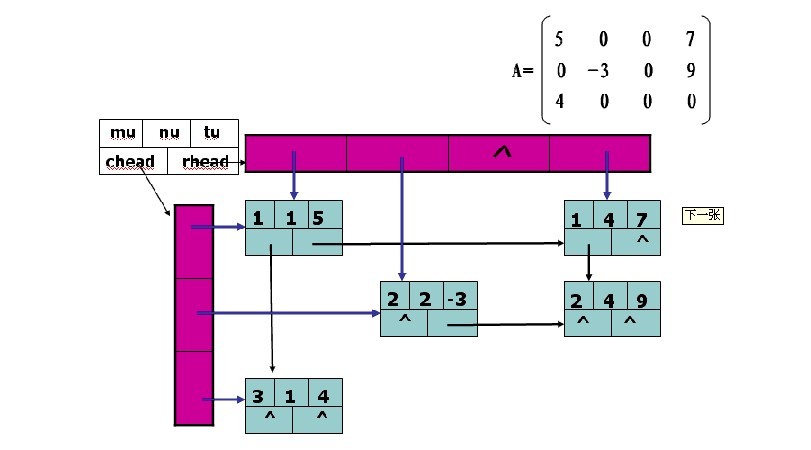
通过上面的图我们可以知道,每个结点不止要存放i, j, e。还要存放它横向的下一个结点的地址以及纵向的下一个结点的地址。形成一个类似十字形的链表的结构。那么每个结点的结构体定义也就呼之欲出了
这样我们对结点的插入与删除就要修改两个指针域。为了方便我们对结点的操作,我们要创建头指针或者头结点。至于到底是选择头指针呢还是头结点,请继续看下去..
我们想下要怎么创建头指针或者头结点,我们可以创建OLNode结构的结点形成一段连续的地址空间来指向某一行或者某一列中的结点(这是我最初的想法)
或者我们创建指针数组,数组元素中存放的地址就是某一行或者某一列的第一个结点的地址。来分析下两种方法
第一种方法会浪费大量的空间,而因为指针变量的空间都是4个字节,所以相对来说第二种节省空间。
毫无疑问我们选择第二种,也就是创建头指针。那么第二种我们用什么来实现?是数组还是动态内存分配?如果用数组我们要预先定义行和列的最大值,显然
这不是一个好主意,而动态内存分配的方法我们可以在用户输入了行数与列数之后分配相应的一段地址连续的空间。更为灵活,所以我们选择动态内存分配。
注意Rhead与Chead的类型,它们是指向指针的指针,也就是说,它们是指向我们定义的OLNode结构的结点的指针的指针。这话有点绕,不过相信C学的不错的朋友都应该清楚。如果不清楚的请看这个帖子 http://topic.csdn.net/u/20110829/01/506b33e3-ebc9-4905-bf8d-d0c877f85c08.html
现在结构体已经定义好了,我们来想想下面应该干什么。首先需要用户输入稀疏矩阵的行数与列数以及非零元的个数。那么就需要定义一个CrossList的结构体变量来存储这些值。
CreatSMatrix函数是我们今天要创建的函数,它用来建立稀疏矩阵并使用十字链表的方式存储矩阵。该函数的原型为int CreateSMatrix(CrossList *M);
当我们创建好了M就需要用户输入了,那么就要对用户的输入进行检查,看是否符合要求,首先mu, nu, tu都不能小于0,并且mu, nu不能等于0(我们这里假设行号与列号都是从1开始的,所以不能等于0),tu的值必须在0与mu * nu之间。
当用户输入了正确的值以后,我们要创建头指针的数组
这里m+1与n+1是为了后面操作的方便使得它们的下标从1开始。注意我们创建时候的强制转换的类型。OLink * , 首先它是指针类型。我们连续创建了m+1个,每一个都指向OLink类型的变量,所以它里面存放的就应该是一个指向OLNode类型的指针的地址。
创建完以后必须初始化,因为我们后面的插入就其中一个判断条件就是它们的值为NULL,也就是该行或者该列中没有结点
现在我们就可以进行结点的输入了,显而易见的要输入的结点个数刚才已经存放到了t变量中,那么我们要创建t个结点。这就是一个大的循环
而每创建一个结点我们都要修改它的两个指针域以及链表头数组。那么我们可以分开两次来修改,第一次修改行的指针域,第二次修改列的指针域。
当用户输入一系列正确的值,并且我们也创建了一个OLNode类型的结点之后我们要讲它插入到某一行中。首先要确定插入在哪一行?我们输入的时候已经输入了行号i,那么我们自然要插入到i行中,那么应该怎样去插入?分两种情况
1、当这一行中没有结点的时候,那么我们直接插入
2、当这一行中有结点的时候我们插入到正确的位置
逐个来分析:
怎么判定一行中有没有结点? 记得我们前面对Rhead的初始化吗? 所有的元素的值都为NULL,所以我们的判断条件就是 NULL==M->Rhead[i].
现在我们来解决第二个问题。
怎么去找到要插入的正确位置。当行中有结点的时候我们无非就是插入到某个结点之前或者之后。那么我们再回到前面,在我们定义Rhead的时候就说
过,某一行的表头指针指向的就是该行中第一个结点的地址。我们假设该行中已经有了一个结点我们称它为A结点,如果要插在A结点之前那么A结点的列号必定是
大于我们输入的结点(我们称它为P结点)的列号的。我们的插入操作就要修改头指针与p结点的right域。就像链表中的插入。那么当该行中没有结点的时候
我们怎么去插入?同样是修改头指针让它指向我们的P结点,同样要修改P结点的right域。看,我们可以利用if语句来实现这两种条件的判断。那么就有了
下面的代码!
现在我们再想一下怎么去插入到某一个结点的后面? 我们新创建的P结点要插入到现有的A结点的后面,那么P的列号必定是大
于A的列号,那么我们只要找到第一个大于比P的列号大的结点B,然后插入到B结点之前!如果现有的结点没有一个结点列号是大于P结点的列号的,那么我们就
应该插入到最后一个结点之后!所以我们首先要寻找符合条件的位置进行插入
这样就插入完成了,至于列的指针域的修改和这个类似!现在贴出所有代码
一,相关概念
㈠特殊矩阵:矩阵中存在大多数值相同的元,或非0元,且在矩阵中的分布有一定规律。
⒈对称矩阵:矩阵中的元素满足
aij=aji 1≤i,j≤n
⒉三角矩阵:上(下)三角矩阵指矩阵的下(上)三角(不包括对角线)中的元素均为常数c或0的n阶矩阵。
⒊对角矩阵(带状矩阵):矩阵中所有非0元素集中在主对角线为中心的区域中。
㈡稀疏矩阵:非0元素很少(≤ 5%)且分布无规律。
二,存储结构
1、对称矩阵
存储分配策略: 每一对对称元只分配一个存储单元,即只存储下三角(包括对角线)的元, 所需空间数为: n(n+1)/2。
存储分配方法: 用一维数组sa[n(n+1)/2]作为存储结构。
sa[k]与aij之间的对应关系为:
2、三角矩阵
也是一个n阶方阵,有上三角和下三角矩阵。下(上)三角矩阵是主对角线以上(下)元素均为零的n阶矩阵。设以一维数组sb[0..n(n+1)/2]作为n阶三角矩阵B的存储结构,仍采用按行存储方案,则B中任一元素bi,j和sb[k]之间仍然有如上的对应关系,只是还需要再加一个存储常数c的存储空间即可。如在下三角矩阵中,用n(n+1)/2的位置来存储常数。
对特殊矩阵的压缩存储实质上就是将二维矩阵中的部分元素按照某种方案排列到一维数组中,不同的排列方案也就对应不同的存储方案
2、稀疏矩阵
常见的有三元组表示法、带辅助行向量的二元组表示法(也即行逻辑链表的顺序表),十字链表表示法等。
1)、三元组表示法
三元组表示法就是在存储非零元的同时,存储该元素所对应的行下标和列下标。稀疏矩阵中的每一个非零元素由一个三元组(i,j,aij)唯一确定。矩阵中所有非零元素存放在由三元组组成的数组中。
在此,data域中表示非零元的三元组是以行序为主序顺序排列的。
以下看如何利用三元组表示法来实现矩阵的转置。
(1)按照b.data中三元组的次序依次在a.data中找出相应的三元组进行转置。换句话说,按照矩阵M的列序进行转置。为了找到M的每一列中所有的非零元素,需要对其三元组表a.data从第一行起整个扫描一遍。由于a.data是以M的行序为存放每个非零元的,由此得到的恰好是b.data应有的顺序。
2)、带辅助行向量的二元组表示法及十字链表表示法在下一节中学习介绍。
三、存储结构及C语言描述
1、三元组表示法
按照b矩阵中的行次序依次在a.data中找到相应的三元组进行转置。
快速转置:按照a.data中三元组的次序进行转置,并将转置后的三元组放到b.data中的恰当位置。
恰当位置的确定:首先计算M矩阵的每一列(即T的每一行)中非0元的个数,然后求得M矩阵每一列第一个非0元在b.data中的位置。
算法基本思想:
设置两个向量:
num[col]:第col列的非零元素个数。
cpot[col]:第col列第一个非零元在b.data中的恰当位置。
在转置过程中,指示该列下一个非零元在b.data中的位置。
1、num[col]的计算:
顺序扫描a.data三元组,累计各列非0元个数。
2、cpot[col]计算:
三元组表示代码:
#include "stdio.h"
#include "stdlib.h"
#define MAXSIZE 12500
#define OK 1
typedef int ElemType;
typedef struct
{
int i,j;
ElemType e;
}Triple;
typedef struct
{
Triple data[MAXSIZE+1];
int mu,nu,tu; //矩阵行数,列数和非0元个数
}TSMatrix;
int cpot[MAXSIZE+1],num[MAXSIZE+1];
int TransposeSMatrix(TSMatrix M,TSMatrix &T)
{
T.mu=M.nu;
T.nu=M.mu;
T.tu=M.tu;
if(T.tu)
{
int q=1;
for(int col=1;col<=M.nu;++col)
for(int p=1;p<=M.tu;++p)
if(M.data[p].j==col)
{
T.data[q].i=M.data[p].j;
T.data[q].j=M.data[p].i;
T.data[q].e=M.data[p].e;
++q;
}//if
}//if
return OK;
}//TransposeSMatrix
int InPutM(TSMatrix &M)
{
printf("input nu mu tu(With a space interval)of a Matrix:\n");
scanf("%d %d %d",&M.nu,&M.mu,&M.tu); //row,colume,and tu
printf("Please input the data of Matrix:\n");
for(int c=1;c<=M.tu;c++)
{
scanf("%d",&M.data[c].i);
scanf("%d",&M.data[c].j);
scanf("%d",&M.data[c].e);
}//for
return 1;
}//InPut
int PrintM(TSMatrix T)
{
printf("Matrix after transpose is:\n");
for(int c=1;c<=T.tu;c++)
{
printf("%d %d %d\n",T.data[c].i,T.data[c].j,T.data[c].e);
}//for
return 1;
}//InPut
int FastTransposeSMatrix(TSMatrix M,TSMatrix &T)
{
T.mu=M.nu;
T.nu=M.mu;
T.tu=M.tu;
if(T.tu)
{
for(int col=1;col<=M.mu;++col) num[col]=0;
for(int t=1;t<=M.tu;++t) ++num[M.data[t].j]; //记述M.data[t].j列
//非0元的个数
cpot[1]=1;
//求第col列中第一个非零元在b.data(T)中的序号
for(int col=2;col<=M.mu;++col)
cpot[col]=cpot[col-1]+num[col-1];
for(int p=1;p<=M.tu;++p)
{
int col=M.data[p].j;
int q=cpot[col];
T.data[q].i=M.data[p].j;
T.data[q].j=M.data[p].i;
T.data[q].e=M.data[p].e;
++cpot[col];
}//for
}//if
return OK;
}//FastTransposeSMatrix
int main()
{
TSMatrix M,T;
InPutM(M);
//TransposeSMatrix(M,T);
FastTransposeSMatrix(M,T);
PrintM(T);
return OK;
}2,行逻辑连接的顺序表
上面我们讨论的是稀疏矩阵的转置,现在我们讨论稀疏矩阵的相乘,相加,相减。如果预先知道不是稀疏矩阵,则用二维数组相乘法就可以了。如果是,则我们用来存储矩阵的结构称之为行逻辑连接的顺序表,就是加入一个行表来记录稀疏矩阵中每行的非零元素在三元组表中的起始位置。
在M.data和N.data中找到相应的各对元素进行相乘即可。此时矩阵的存储结构是
在此,我们引入rpos[row]用来指示矩阵N的第row行中第一个非零元在N.data中的序号,则rpos[row+1]-1指示矩阵的第row行中最后一个非零元在N.data中的序号。而最后一行中最后一个非零元在N.data的位置就是N.tu了。
如上图中,N的rpos值为:
带行逻辑链接的顺序表实现代码:
我们知道稀疏矩阵的三元组存储方式的实现很简单,每个元素有三个域分别是i,
j,
e。代表了该非零元的行号、列号以及值。那么在十字链表的存储方式下,首先这三个域是肯定少不了的,不然在进行很多操作的时候都要自己使用计数器,很麻
烦。而十字链表的形式大家可以理解成每一行是一个链表,而每一列又是一个链表。如图所示:
通过上面的图我们可以知道,每个结点不止要存放i, j, e。还要存放它横向的下一个结点的地址以及纵向的下一个结点的地址。形成一个类似十字形的链表的结构。那么每个结点的结构体定义也就呼之欲出了
1 typedef struct OLNode {
2 int i, j; //行号与列号
3 ElemType e; //值
4 struct OLNode *right, *down; //指针域
5 }OLNode, *OList;这样我们对结点的插入与删除就要修改两个指针域。为了方便我们对结点的操作,我们要创建头指针或者头结点。至于到底是选择头指针呢还是头结点,请继续看下去..
我们想下要怎么创建头指针或者头结点,我们可以创建OLNode结构的结点形成一段连续的地址空间来指向某一行或者某一列中的结点(这是我最初的想法)
或者我们创建指针数组,数组元素中存放的地址就是某一行或者某一列的第一个结点的地址。来分析下两种方法
第一种方法会浪费大量的空间,而因为指针变量的空间都是4个字节,所以相对来说第二种节省空间。
毫无疑问我们选择第二种,也就是创建头指针。那么第二种我们用什么来实现?是数组还是动态内存分配?如果用数组我们要预先定义行和列的最大值,显然
这不是一个好主意,而动态内存分配的方法我们可以在用户输入了行数与列数之后分配相应的一段地址连续的空间。更为灵活,所以我们选择动态内存分配。
现在结构体已经定义好了,我们来想想下面应该干什么。首先需要用户输入稀疏矩阵的行数与列数以及非零元的个数。那么就需要定义一个CrossList的结构体变量来存储这些值。
当我们创建好了M就需要用户输入了,那么就要对用户的输入进行检查,看是否符合要求,首先mu, nu, tu都不能小于0,并且mu, nu不能等于0(我们这里假设行号与列号都是从1开始的,所以不能等于0),tu的值必须在0与mu * nu之间。
创建完以后必须初始化,因为我们后面的插入就其中一个判断条件就是它们的值为NULL,也就是该行或者该列中没有结点
而每创建一个结点我们都要修改它的两个指针域以及链表头数组。那么我们可以分开两次来修改,第一次修改行的指针域,第二次修改列的指针域。
1、当这一行中没有结点的时候,那么我们直接插入
2、当这一行中有结点的时候我们插入到正确的位置
逐个来分析:
怎么判定一行中有没有结点? 记得我们前面对Rhead的初始化吗? 所有的元素的值都为NULL,所以我们的判断条件就是 NULL==M->Rhead[i].
现在我们来解决第二个问题。
怎么去找到要插入的正确位置。当行中有结点的时候我们无非就是插入到某个结点之前或者之后。那么我们再回到前面,在我们定义Rhead的时候就说
过,某一行的表头指针指向的就是该行中第一个结点的地址。我们假设该行中已经有了一个结点我们称它为A结点,如果要插在A结点之前那么A结点的列号必定是
大于我们输入的结点(我们称它为P结点)的列号的。我们的插入操作就要修改头指针与p结点的right域。就像链表中的插入。那么当该行中没有结点的时候
我们怎么去插入?同样是修改头指针让它指向我们的P结点,同样要修改P结点的right域。看,我们可以利用if语句来实现这两种条件的判断。那么就有了
下面的代码!
于A的列号,那么我们只要找到第一个大于比P的列号大的结点B,然后插入到B结点之前!如果现有的结点没有一个结点列号是大于P结点的列号的,那么我们就
应该插入到最后一个结点之后!所以我们首先要寻找符合条件的位置进行插入

相关文章推荐
- Android数据的三种存储方式:SharedPreferences、SQLite、Content Provider
- DAS、SAN和NAS三种存储方式介绍
- Hive metastore三种存储方式
- Hive metastore三种存储方式
- 技术解析:DAS、SAN和NAS三种存储方式
- NAS DAS SAN三种存储方式的比较
- Android中数据存储的三种方式--基础
- 企业数据存储的三种方式 DAS、NAS和SAN
- Android数据存储的三种方式-SharedPrefrences,File,SQLite
- DB2的三种存储过程的递归方式
- java调用存储过程的三种方式(包含通过hibernate调用)
- NAS DAS SAN三种存储方式的比较
- hive中metastore三种存储方式
- iOS边练边学--应用数据存储的常用方式(plist,Preference,NSKeyedArchiver)其中的三种
- 存储信息的三种方式:Application,Session,Cookie区别
- YUV的三种存储方式
- unity中三种数据存储方式ScriptableObject,Json,Xml和Dictionary的序列化
- 存储入门:主机与ISCSI设备之间三种连接方式
- Hive metastore三种存储方式
- 总结JavaScript三种数据存储方式之间的区别