【七】机器学习之路——训练集、测试集及如何划分
2017-10-31 21:02
323 查看
上一个博客讲了一个简单的例子,根据手头的房子大小和房价的数据来拟合房子大小和房价的关系曲线,当然这是一个非常简单的一元一次方程,y=ax+b。但是最后咱们还少了一样东西,不知道细心的同学有没有发现,那就是咱们拟合曲线的准确度到底有多少呢?怎么来检测咱们拟合曲线到底有多完美呢?用什么来验证咱们的准确度呢?
带着一肚子疑问,咱们就先来介绍一下数据拟合中的训练集,测试集,验证集。字比较多,但都很容易懂,耐心看下去会收获不少哦。
训练集(Training Set):帮助我们训练模型,简单的说就是通过训练集的数据让我们确定拟合曲线的参数。
验证集(Validation Set):用来做模型选择(model selection),即做模型的最终优化及确定的,用来辅助我们的模型的构建,可选;
测试集(Test Set): 为了测试已经训练好的模型的精确度。当然,test set这并不能保证模型的正确性,他只是说相似的数据用此模型会得出相似的结果。因为我们在训练模型的时候,参数全是根据现有训练集里的数据进行修正、拟合,有可能会出现过拟合的情况,即这个参数仅对训练集里的数据拟合比较准确,这个时候再有一个数据需要利用模型预测结果,准确率可能就会很差。
但实际应用中,一般只将数据集分成两类,即训练集Training set 和测试集Test set,大多数文章并不涉及验证集Validation set。如果后面碰到有这样的问题,我会再跟大家讲解。
细心的小伙伴可能会发现,我们上个房价预测的例子里,将所有的数据用做训练集,而并没有测试集来测试模型的准确度,因为数据是我编的哈哈,太少了,还没涉及到测试模型的问题。别着急,一步一步来,我先介绍一下sklearn里是怎么将手头已有的数据分为训练集和测试集的。
训练集和测试集的划分方法
以下讲解摘自周志华老师的《机器学习》一书。同时大家可以先参考馍馍momo博主的如何划分训练集和测试集的介绍,讲的比较简单、精炼。
- 留出法(Hold-out)
留出法的意思是直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个集合作为测试集T,即D=S∪T,S∩T=∅。在S上训练出模型后,用T来评估其误差。
需要注意的是,训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入的额外的偏差而对最终结果产生影响。例如在分类任务中,至少要保持样本的类别比例相似。从”采样”的角度来看待数据集的划分过程,则保留类别比例的采样方式通常称为“分层采样”。例如从1000个数据里,分层采样获得70%样本的训练集S和30%样本的测试集T,若D包含500个正例,500个反例,则分层采样得到的S应包含350个正例,350个反例,T应包含150个正例,150个反例;若S、T中样本比例差别很大,则最终拟合的误差将会变大。
一般,在用留出法划分集合的时候,会通过若干次随机划分、重复实验评估后取平均值作为留出法的评估结果,减少误差。
留出法还有一个问题就是,到底我们训练集和测试集应该按照什么比例来划分呢?70% ?60% ? 50% ???,如果我们训练集的比例比较大,可能会导致训练出的模型更接近于用D训练出的模型,同时T较小,评价结果又不够准确;若T的比例比较大,则有可能导致评估的模型与之前有较大的差别,从而降低了评估的保真性。这个问题没有完美的解决方案,常见的做法是将大约2/3~4/5的样本用于训练。
- 交叉验证法(Cross Validation)
”交叉验证法”先将数据集D划分为k个大小相似的互斥子集,即D=D1∪D2∪...∪Dk,Di∩Dj=∅(i≠j)。每个子集都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的子集作为测试集;这样就可以获得k组训练/测试集,从而可以进行k次训练和测试,最终返回的是k个测试结果的均值。
显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为了强调这一点,通常把交叉验证法称为”k折交叉验证”(k-fold cross validation),k通常取10—10折交叉验证。
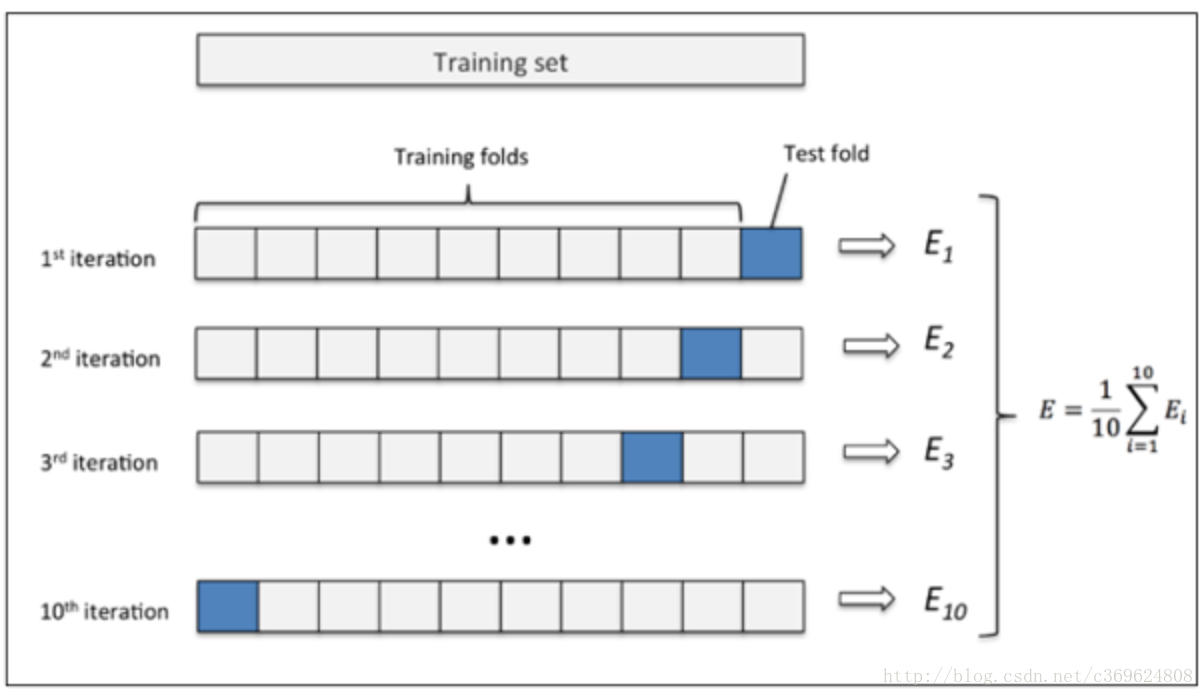
交叉验证的好处就是从有限的数据中尽可能挖掘多的信息,从各种角度去学习我们现有的有限的数据,避免出现局部的极值。在这个过程中无论是训练样本还是测试样本都得到了尽可能多的学习。(By 知乎 张戎 交叉验证简介)
交叉验证法的缺点就是,当数据集比较大时,训练模型的开销较大。
- 自助法(BootStrapping)
我们当然想用手头所有的数据来训练模型了,这样才能更好的拟合,留出法和交叉验证法都将保留了部分数据用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。
自助法是一个比较好的解决方案。给定m个样本的数据集D,我们对它进行采样产生数据集D′,每次随机从D中挑选一个样本,将其拷贝到D′,这个过程执行m次后,我们就得到了包含m个样本的数据集D′。显然,D中有部分样本会在D′中多次出现。做个简单的估计,样本在m次采样中始终不被采到的概率是(1−1m)m,取极限为
limx→∞(1−1m)m=1e≈0.368
即通过自助采样,初始数据集D中约有36.8%的样本未出现在采样集D′里。于是 ,实际评估的模型与期望评估的模型都是使用m个样本,而我们仍有数据总量约1/3的没在训练集出现过的样本用于测试。
自助法在数据集较小、难以有效划分训练/测试集时比较有用。然而自助法产生的测试集改变了初始数据集的分布,这会引入误差,因此在数据集比较大时,采用留出法和交叉验证法较好。
带着一肚子疑问,咱们就先来介绍一下数据拟合中的训练集,测试集,验证集。字比较多,但都很容易懂,耐心看下去会收获不少哦。
训练集(Training Set):帮助我们训练模型,简单的说就是通过训练集的数据让我们确定拟合曲线的参数。
验证集(Validation Set):用来做模型选择(model selection),即做模型的最终优化及确定的,用来辅助我们的模型的构建,可选;
测试集(Test Set): 为了测试已经训练好的模型的精确度。当然,test set这并不能保证模型的正确性,他只是说相似的数据用此模型会得出相似的结果。因为我们在训练模型的时候,参数全是根据现有训练集里的数据进行修正、拟合,有可能会出现过拟合的情况,即这个参数仅对训练集里的数据拟合比较准确,这个时候再有一个数据需要利用模型预测结果,准确率可能就会很差。
但实际应用中,一般只将数据集分成两类,即训练集Training set 和测试集Test set,大多数文章并不涉及验证集Validation set。如果后面碰到有这样的问题,我会再跟大家讲解。
细心的小伙伴可能会发现,我们上个房价预测的例子里,将所有的数据用做训练集,而并没有测试集来测试模型的准确度,因为数据是我编的哈哈,太少了,还没涉及到测试模型的问题。别着急,一步一步来,我先介绍一下sklearn里是怎么将手头已有的数据分为训练集和测试集的。
训练集和测试集的划分方法
以下讲解摘自周志华老师的《机器学习》一书。同时大家可以先参考馍馍momo博主的如何划分训练集和测试集的介绍,讲的比较简单、精炼。
- 留出法(Hold-out)
留出法的意思是直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个集合作为测试集T,即D=S∪T,S∩T=∅。在S上训练出模型后,用T来评估其误差。
需要注意的是,训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入的额外的偏差而对最终结果产生影响。例如在分类任务中,至少要保持样本的类别比例相似。从”采样”的角度来看待数据集的划分过程,则保留类别比例的采样方式通常称为“分层采样”。例如从1000个数据里,分层采样获得70%样本的训练集S和30%样本的测试集T,若D包含500个正例,500个反例,则分层采样得到的S应包含350个正例,350个反例,T应包含150个正例,150个反例;若S、T中样本比例差别很大,则最终拟合的误差将会变大。
一般,在用留出法划分集合的时候,会通过若干次随机划分、重复实验评估后取平均值作为留出法的评估结果,减少误差。
留出法还有一个问题就是,到底我们训练集和测试集应该按照什么比例来划分呢?70% ?60% ? 50% ???,如果我们训练集的比例比较大,可能会导致训练出的模型更接近于用D训练出的模型,同时T较小,评价结果又不够准确;若T的比例比较大,则有可能导致评估的模型与之前有较大的差别,从而降低了评估的保真性。这个问题没有完美的解决方案,常见的做法是将大约2/3~4/5的样本用于训练。
- 交叉验证法(Cross Validation)
”交叉验证法”先将数据集D划分为k个大小相似的互斥子集,即D=D1∪D2∪...∪Dk,Di∩Dj=∅(i≠j)。每个子集都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的子集作为测试集;这样就可以获得k组训练/测试集,从而可以进行k次训练和测试,最终返回的是k个测试结果的均值。
显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为了强调这一点,通常把交叉验证法称为”k折交叉验证”(k-fold cross validation),k通常取10—10折交叉验证。
交叉验证的好处就是从有限的数据中尽可能挖掘多的信息,从各种角度去学习我们现有的有限的数据,避免出现局部的极值。在这个过程中无论是训练样本还是测试样本都得到了尽可能多的学习。(By 知乎 张戎 交叉验证简介)
交叉验证法的缺点就是,当数据集比较大时,训练模型的开销较大。
- 自助法(BootStrapping)
我们当然想用手头所有的数据来训练模型了,这样才能更好的拟合,留出法和交叉验证法都将保留了部分数据用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。
自助法是一个比较好的解决方案。给定m个样本的数据集D,我们对它进行采样产生数据集D′,每次随机从D中挑选一个样本,将其拷贝到D′,这个过程执行m次后,我们就得到了包含m个样本的数据集D′。显然,D中有部分样本会在D′中多次出现。做个简单的估计,样本在m次采样中始终不被采到的概率是(1−1m)m,取极限为
limx→∞(1−1m)m=1e≈0.368
即通过自助采样,初始数据集D中约有36.8%的样本未出现在采样集D′里。于是 ,实际评估的模型与期望评估的模型都是使用m个样本,而我们仍有数据总量约1/3的没在训练集出现过的样本用于测试。
自助法在数据集较小、难以有效划分训练/测试集时比较有用。然而自助法产生的测试集改变了初始数据集的分布,这会引入误差,因此在数据集比较大时,采用留出法和交叉验证法较好。

相关文章推荐
- 机器学习中训练集、验证集(开发集)、测试集如何划分
- Sklearn-train_test_split随机划分训练集和测试集
- sklearn:随机划分训练集和测试集
- python 划分数据集为训练集和测试集
- Matlab划分测试集和训练集
- 如何分训练集和测试集,如何算召回率和准确率?
- 划分训练集和测试集和验证集
- Sklearn-train_test_split随机划分训练集和测试集
- r语言中怎么划分训练集和测试集
- Sklearn-train_test_split随机划分训练集和测试集
- 【cl】预处理&划分测试集、训练集
- Sklearn-train_test_split随机划分训练集和测试集
- 使用Java随机划分数据集为训练集和测试集
- 机器学习中,如何利用训练集&测试集来判断 方差(varience)& 偏差(bias)
- 【论文相关】如何构建训练集和测试集
- Python数据预处理—训练集和测试集数据划分
- Sklearn-train_test_split随机划分训练集和测试集
- [机器学习]划分训练集和测试集的方法
- 为什么要划分训练集、验证集、测试集?
- python 将数据随机分为训练集和测试集