Hadoop HA QJM 与RM的自动容灾 以及hbase与Hadoop HA的 配置ha后hive修改
2017-10-31 11:30
549 查看





------------------------------------------------------------------------------------------------------------------------------------






初始化编辑日志如果上锁就把in_lock给删掉

RM的自动容灾-----------------------------------------------------------------------------------------

4000
【yarn-site.xml】

在两台主机分别启动:yarn-daemon.sh start Resourcemanager
hbase与hadoop HA的集成:
之后要想运行hbase的MR,还要修改【hbase-site.xml】


在这之前要把xcall rm -rf /home/ubuntu/zk/version-2删掉([zoo.cfg]的dataDir)
修改【hbase-site.xml】


$s100>zkCli.sh -server s101:2181
hbase Hmaster HA----------------
只需要在想要启动的节点上运行:$>hbase-daemon.sh start master
修改hive:hdfs名称变成逻辑名之后,以前集群下创建的表就不能用了,

基本上改了之后也不好使,查看hdfs dfs -lsr /
删除原来的hive数据库,重新创建一个
如果没有/user/hive目录,需要删除临时目录重新初始化元数据库:
schematool -initSchema -dbType mysql
------------------------------------------------------------------------------------------------------------------------------------
近日,在搭建Hadoop HA QJM集群的时候,出现一个问题,如本文标题。
网上有很多HA的博文,其实比较好的博文就是官方文档,讲的已经非常详细。所以,HA的搭建这里不再赘述。
本文就想给出一篇org.apache.hadoop.ipc.Client: Retrying connect to server错误的解决的方法。
因为在搜索引擎中输入了错误问题,没有找到一篇解决问题的。这里写一篇备忘,也可以给出现同样问题的朋友一个提示。
一、问题描述
HA按照规划配置好,启动后,NameNode不能正常启动。刚启动的时候 jps 看到了NameNode,但是隔了一两分钟,再看NameNode就不见了。
但是测试之后,发现下面2种情况:
1)先启动JournalNode,再启动Hdfs,NameNode可以启动并可以正常运行
2)使用start-dfs.sh启动,众多服务都启动了,隔两分钟NameNode会退出,再次hadoop-daemon.sh start namenode单独启动可以成功稳定运行NameNode。
再看NameNode的日志,不要嫌日志长,其实出错的蛛丝马迹都包含其中了,如下:
2016-03-09 10:50:27,123 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node1/192.168.56.201
STARTUP_MSG: args = []
STARTUP_MSG: version = 2.5.1
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2014-10-20T05:53Z
STARTUP_MSG: java = 1.7.0_09
************************************************************/
2016-03-09 10:50:27,132 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2016-03-09 10:50:27,138 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: createNameNode []
2016-03-09 10:50:27,465 INFO org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2016-03-09 10:50:27,623 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2016-03-09 10:50:27,623 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NameNode metrics system started
2016-03-09 10:50:27,625 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: fs.defaultFS is hdfs://hadoopha
2016-03-09 10:50:27,626 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: Clients are to use hadoopha to access this namenode/service.
2016-03-09 10:50:28,048 INFO org.apache.hadoop.hdfs.DFSUtil: Starting web server as: ${dfs.web.authentication.kerberos.principal}
2016-03-09 10:50:28,048 INFO org.apache.hadoop.hdfs.DFSUtil: Starting Web-server for hdfs at: http://node1:50070
2016-03-09 10:50:28,121 INFO org.mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
2016-03-09 10:50:28,128 INFO org.apache.hadoop.http.HttpRequestLog: Http request log for http.requests.namenode is not defined
2016-03-09 10:50:28,145 INFO org.apache.hadoop.http.HttpServer2: Added global filter 'safety' (class=org.apache.hadoop.http.HttpServer2$QuotingInputFilter)
2016-03-09 10:50:28,149 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context hdfs
2016-03-09 10:50:28,149 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context static
2016-03-09 10:50:28,149 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context logs
2016-03-09 10:50:28,209 INFO org.apache.hadoop.http.HttpServer2: Added filter 'org.apache.hadoop.hdfs.web.AuthFilter' (class=org.apache.hadoop.hdfs.web.AuthFilter)
2016-03-09 10:50:28,211 INFO org.apache.hadoop.http.HttpServer2: addJerseyResourcePackage: packageName=org.apache.hadoop.hdfs.server.namenode.web.resources;org.apache.hadoop.hdfs.web.resources, pathSpec=/webhdfs/v1/*
2016-03-09 10:50:28,268 INFO org.apache.hadoop.http.HttpServer2: Jetty bound to port 50070
2016-03-09 10:50:28,269 INFO org.mortbay.log: jetty-6.1.26
2016-03-09 10:50:28,580 WARN org.apache.hadoop.security.authentication.server.AuthenticationFilter: 'signature.secret' configuration not set, using a random value as secret
2016-03-09 10:50:28,648 INFO org.mortbay.log: Started HttpServer2$SelectChannelConnectorWithSafeStartup@node1:50070
2016-03-09 10:50:28,687 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Only one image storage directory (dfs.namenode.name.dir) configured. Beware of data loss due to lack of redundant storage directories!
2016-03-09 10:50:28,741 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: fsLock is fair:true
2016-03-09 10:50:28,802 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
2016-03-09 10:50:28,802 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2016-03-09 10:50:28,805 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2016-03-09 10:50:28,807 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: The block deletion will start around 2016 Mar 09 10:50:28
2016-03-09 10:50:28,810 INFO org.apache.hadoop.util.GSet: Computing capacity for map BlocksMap
2016-03-09 10:50:28,810 INFO org.apache.hadoop.util.GSet: VM type = 64-bit
2016-03-09 10:50:28,813 INFO org.apache.hadoop.util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
2016-03-09 10:50:28,813 INFO org.apache.hadoop.util.GSet: capacity = 2^21 = 2097152 entries
2016-03-09 10:50:28,852 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: dfs.block.access.token.enable=false
2016-03-09 10:50:28,852 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: defaultReplication = 3
2016-03-09 10:50:28,852 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: maxReplication = 512
2016-03-09 10:50:28,852 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: minReplication = 1
2016-03-09 10:50:28,853 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: maxReplicationStreams = 2
2016-03-09 10:50:28,853 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
2016-03-09 10:50:28,853 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: replicationRecheckInterval = 3000
2016-03-09 10:50:28,853 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: encryptDataTransfer = false
2016-03-09 10:50:28,853 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: maxNumBlocksToLog = 1000
2016-03-09 10:50:28,859 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
2016-03-09 10:50:28,859 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: supergroup = supergroup
2016-03-09 10:50:28,859 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: isPermissionEnabled = true
2016-03-09 10:50:28,865 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Determined nameservice ID: hadoopha
2016-03-09 10:50:28,865 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: HA Enabled: true
2016-03-09 10:50:28,866 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Append Enabled: true
2016-03-09 10:50:29,120 INFO org.apache.hadoop.util.GSet: Computing capacity for map INodeMap
2016-03-09 10:50:29,120 INFO org.apache.hadoop.util.GSet: VM type = 64-bit
2016-03-09 10:50:29,120 INFO org.apache.hadoop.util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
2016-03-09 10:50:29,120 INFO org.apache.hadoop.util.GSet: capacity = 2^20 = 1048576 entries
2016-03-09 10:50:29,174 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: Caching file names occuring more than 10 times
2016-03-09 10:50:29,186 INFO org.apache.hadoop.util.GSet: Computing capacity for map cachedBlocks
2016-03-09 10:50:29,186 INFO org.apache.hadoop.util.GSet: VM type = 64-bit
2016-03-09 10:50:29,186 INFO org.apache.hadoop.util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
2016-03-09 10:50:29,186 INFO org.apache.hadoop.util.GSet: capacity = 2^18 = 262144 entries
2016-03-09 10:50:29,188 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2016-03-09 10:50:29,188 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
2016-03-09 10:50:29,188 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
2016-03-09 10:50:29,190 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Retry cache on namenode is enabled
2016-03-09 10:50:29,190 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2016-03-09 10:50:29,194 INFO org.apache.hadoop.util.GSet: Computing capacity for map NameNodeRetryCache
2016-03-09 10:50:29,194 INFO org.apache.hadoop.util.GSet: VM type = 64-bit
2016-03-09 10:50:29,194 INFO org.apache.hadoop.util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
2016-03-09 10:50:29,194 INFO org.apache.hadoop.util.GSet: capacity = 2^15 = 32768 entries
2016-03-09 10:50:29,199 INFO org.apache.hadoop.hdfs.server.namenode.NNConf: ACLs enabled? false
2016-03-09 10:50:29,199 INFO org.apache.hadoop.hdfs.server.namenode.NNConf: XAttrs enabled? true
2016-03-09 10:50:29,199 INFO org.apache.hadoop.hdfs.server.namenode.NNConf: Maximum size of an xattr: 16384
2016-03-09 10:50:29,208 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /home/hadoop/hadoop/tmp/dfs/name/in_use.lock acquired by nodename 4394@node1
2016-03-09 10:50:29,610 WARN org.apache.hadoop.security.ssl.FileBasedKeyStoresFactory: The property 'ssl.client.truststore.location' has not been set, no TrustStore will be loaded
2016-03-09 10:50:31,053 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node2/192.168.56.202:8485. Already tried 0 time(s); retry policy is
RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2016-03-09 10:50:31,054 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node3/192.168.56.203:8485. Already tried 0 time(s); retry policy is
RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2016-03-09 10:50:31,054 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node4/192.168.56.204:8485. Already tried 0 time(s); retry policy is
RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2016-03-09 10:50:32,055 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node2/192.168.56.202:8485. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
此处省去重复的N行
2016-03-09 10:50:35,807 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 6001 ms (timeout=20000 ms) for a response for selectInputStreams. No responses yet.
此处省去重复的N行
2016-03-09 10:50:39,812 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 10006 ms (timeout=20000 ms) for a response for selectInputStreams. No responses yet.
2016-03-09 10:50:40,065 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node3/192.168.56.203:8485. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
2016-03-09 10:50:40,065 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node4/192.168.56.204:8485. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
2016-03-09 10:50:40,065 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node2/192.168.56.202:8485. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
2016-03-09 10:50:40,069 WARN org.apache.hadoop.hdfs.server.namenode.FSEditLog: Unable to determine input streams from QJM to [192.168.56.202:8485, 192.168.56.203:8485, 192.168.56.204:8485]. Skipping.
org.apache.hadoop.hdfs.qjournal.client.QuorumException: Got too many exceptions to achieve quorum size 2/3. 3 exceptions thrown:
192.168.56.202:8485: Call From node1/192.168.56.201 to node2:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
192.168.56.203:8485: Call From node1/192.168.56.201 to node3:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
192.168.56.204:8485: Call From node1/192.168.56.201 to node4:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at org.apache.hadoop.hdfs.qjournal.client.QuorumException.create(QuorumException.java:81)
at org.apache.hadoop.hdfs.qjournal.client.QuorumCall.rethrowException(QuorumCall.java:223)
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:142)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.selectInputStreams(QuorumJournalManager.java:471)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.selectInputStreams(JournalSet.java:260)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1430)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1450)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSImage(FSImage.java:636)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:279)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:955)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:700)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:529)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:585)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:751)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:735)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1407)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1473)
2016-03-09 10:50:40,071 INFO org.apache.hadoop.hdfs.server.namenode.FSImage: No edit log streams selected.
2016-03-09 10:50:40,116 INFO org.apache.hadoop.hdfs.server.namenode.FSImageFormatPBINode: Loading 1 INodes.
2016-03-09 10:50:40,174 INFO org.apache.hadoop.hdfs.server.namenode.FSImageFormatProtobuf: Loaded FSImage in 0 seconds.
2016-03-09 10:50:40,174 INFO org.apache.hadoop.hdfs.server.namenode.FSImage: Loaded image for txid 0 from /home/hadoop/hadoop/tmp/dfs/name/current/fsimage_0000000000000000000
2016-03-09 10:50:40,184 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Need to save fs image? false (staleImage=true, haEnabled=true, isRollingUpgrade=false)
2016-03-09 10:50:40,185 INFO org.apache.hadoop.hdfs.server.namenode.NameCache: initialized with 0 entries 0 lookups
2016-03-09 10:50:40,185 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Finished loading FSImage in 10986 msecs
2016-03-09 10:50:40,408 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: RPC server is binding to node1:8020
2016-03-09 10:50:40,414 INFO org.apache.hadoop.ipc.CallQueueManager: Using callQueue class java.util.concurrent.LinkedBlockingQueue
2016-03-09 10:50:40,429 INFO org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 8020
2016-03-09 10:50:40,461 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Registered FSNamesystemState MBean
2016-03-09 10:50:40,474 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Number of blocks under construction: 0
2016-03-09 10:50:40,474 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Number of blocks under construction: 0
2016-03-09 10:50:40,475 INFO org.apache.hadoop.hdfs.StateChange: STATE* Leaving safe mode after 11 secs
2016-03-09 10:50:40,475 INFO org.apache.hadoop.hdfs.StateChange: STATE* Network topology has 0 racks and 0 datanodes
2016-03-09 10:50:40,475 INFO org.apache.hadoop.hdfs.StateChange: STATE* UnderReplicatedBlocks has 0 blocks
2016-03-09 10:50:40,536 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2016-03-09 10:50:40,539 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 8020: starting
2016-03-09 10:50:40,542 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: NameNode RPC up at: node1/192.168.56.201:8020
2016-03-09 10:50:40,542 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Starting services required for standby state
2016-03-09 10:50:40,545 INFO org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer: Will roll logs on active node at node5/192.168.56.205:8020 every 120 seconds.
2016-03-09 10:50:40,550 INFO org.apache.hadoop.hdfs.server.namenode.ha.StandbyCheckpointer: Starting standby checkpoint thread...
Checkpointing active NN at http://node5:50070
Serving checkpoints at http://node1:50070
2016-03-09 10:50:41,551 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node2/192.168.56.202:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
此处省去重复的N行
2016-03-09 10:50:50,557 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 10007 ms (timeout=20000 ms) for a response for selectInputStreams. No responses yet.
2016-03-09 10:50:50,561 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node3/192.168.56.203:8485. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
2016-03-09 10:50:50,626 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node4/192.168.56.204:8485. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
2016-03-09 10:50:50,676 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node2/192.168.56.202:8485. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
2016-03-09 10:50:50,677 WARN org.apache.hadoop.hdfs.server.namenode.FSEditLog: Unable to determine input streams from QJM to [192.168.56.202:8485, 192.168.56.203:8485, 192.168.56.204:8485]. Skipping.
org.apache.hadoop.hdfs.qjournal.client.QuorumException: Got too many exceptions to achieve quorum size 2/3. 3 exceptions thrown:
192.168.56.202:8485: Call From node1/192.168.56.201 to node2:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
192.168.56.203:8485: Call From node1/192.168.56.201 to node3:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
192.168.56.204:8485: Call From node1/192.168.56.201 to node4:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at org.apache.hadoop.hdfs.qjournal.client.QuorumException.create(QuorumException.java:81)
at org.apache.hadoop.hdfs.qjournal.client.QuorumCall.rethrowException(QuorumCall.java:223)
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:142)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.selectInputStreams(QuorumJournalManager.java:471)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.selectInputStreams(JournalSet.java:260)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1430)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1450)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer.doTailEdits(EditLogTailer.java:212)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.doWork(EditLogTailer.java:324)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.access$200(EditLogTailer.java:282)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread$1.run(EditLogTailer.java:299)
at org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:411)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.run(EditLogTailer.java:295)
2016-03-09 10:50:50,677 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Stopping services started for standby state
2016-03-09 10:50:50,678 WARN org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer: Edit log tailer interrupted
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.doWork(EditLogTailer.java:337)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.access$200(EditLogTailer.java:282)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread$1.run(EditLogTailer.java:299)
at org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:411)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.run(EditLogTailer.java:295)
2016-03-09 10:50:50,682 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Starting services required for active state
2016-03-09 10:50:50,684 WARN org.apache.hadoop.security.ssl.FileBasedKeyStoresFactory: The property 'ssl.client.truststore.location' has not been set, no TrustStore will be loaded
2016-03-09 10:50:50,690 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Starting recovery process for unclosed journal segments...
2016-03-09 10:50:51,698 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node3/192.168.56.203:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000
MILLISECONDS)
此处省去重复的N行
2016-03-09 10:51:00,715 FATAL org.apache.hadoop.hdfs.server.namenode.FSEditLog: Error: recoverUnfinalizedSegments failed for required journal (JournalAndStream(mgr=QJM to [192.168.56.202:8485, 192.168.56.203:8485, 192.168.56.204:8485],
stream=null))
org.apache.hadoop.hdfs.qjournal.client.QuorumException: Got too many exceptions to achieve quorum size 2/3. 3 exceptions thrown:
192.168.56.203:8485: Call From node1/192.168.56.201 to node3:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
192.168.56.202:8485: Call From node1/192.168.56.201 to node2:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
192.168.56.204:8485: Call From node1/192.168.56.201 to node4:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at org.apache.hadoop.hdfs.qjournal.client.QuorumException.create(QuorumException.java:81)
at org.apache.hadoop.hdfs.qjournal.client.QuorumCall.rethrowException(QuorumCall.java:223)
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:142)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.createNewUniqueEpoch(QuorumJournalManager.java:182)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.recoverUnfinalizedSegments(QuorumJournalManager.java:436)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$7.apply(JournalSet.java:590)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.mapJournalsAndReportErrors(JournalSet.java:359)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.recoverUnfinalizedSegments(JournalSet.java:587)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.recoverUnclosedStreams(FSEditLog.java:1361)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startActiveServices(FSNamesystem.java:1068)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.startActiveServices(NameNode.java:1624)
at org.apache.hadoop.hdfs.server.namenode.ha.ActiveState.enterState(ActiveState.java:61)
at org.apache.hadoop.hdfs.server.namenode.ha.HAState.setStateInternal(HAState.java:63)
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.setState(StandbyState.java:49)
at org.apache.hadoop.hdfs.server.namenode.NameNode.transitionToActive(NameNode.java:1502)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.transitionToActive(NameNodeRpcServer.java:1197)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.transitionToActive(HAServiceProtocolServerSideTranslatorPB.java:107)
at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4460)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007)
2016-03-09 10:51:00,717 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1
2016-03-09 10:51:00,718 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node1/192.168.56.201
************************************************************/
二、问题分析
看着日志很长,来分析一下,注意看日志中使用颜色突出的部分。
可以肯定NameNode不能正常运行,不是配置错了,而是不能连接上JournalNode、
查看JournalNode的日志没有问题,那么问题就在JournalNode的客户端NameNode。
2016-03-09 10:50:31,053 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: node2/192.168.56.202:8485. Already tried 0 time(s); retry policy is
RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
来分析上句的日志:
NameNode作为JournalNode的客户端发起连接请求,但是失败了,然后NameNode又向其他节点依次发起了请求都失败了,直至到了最大重试次数。
通过实验知道,先启动JournalNode或者再次启动NameNode就可以了,说明JournalNode并没有准备好,而NameNode已经用完了所有重试次数。
三、解决办法
修改core-site.xml中的ipc参数
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish
a server connection.
</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for
before retrying to establish a server connection.
</description>
</property>
Namenode向JournalNode发起的ipc连接请求的重试间隔时间和重试次数,我的虚拟机集群实验大约需要2分钟,NameNode即可连接上JournalNode。连接后很稳定。
注意:仅对于这种由于服务没有启动完成造成连接超时的问题,都可以调整core-site.xml中的ipc参数来解决。如果目标服务本身没有启动成功,这边调整ipc参数是无效的。
一.Hdfs HA
NN DN ZK JN ZKFCs100 1 1 1
s101 1 1 1 1 1
s102 1 1 1
s103 1 1
1. 免密钥(四台相互免密钥)
ssh-keygen -trsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id s100
ssh-copy-id s101
ssh-copy-id s102
ssh-copy-id s103
2. 安装jdk
[/etc/environment]
JAVA_HOME=jdk
Path=”$Path:jdk/bin”
3. 安装hadoop
Hadoop安装包上传 解压 配置环境变量
4. 修改配置slaves
[/hadoop-2.7.0/etc/hadoop/slaves]
s101
s102
s103
发送到其他三台主机上面
5.安装zookeeper集群
1.在s100上面上传zk压缩包
>cp /mnt/hgfs/BigData/第九天/zookeeper-3.4.10.tar.gz/data/
解压
>cd /data
>tar -xzvf zookeeper-3.4.10.tar.gz
2.发送到其他节点
>xsync /data/zookeeper-3.4.10
3.配置环境
[/etc/environment]
ZOOKEEPER_HOME=/data/zookeeper-3.4.10
Path=”$Path:/data/zookeeper-3.4.10/bin”
4.重启
>sudo reboot
5.测试
>zk
6. 修改配置文件
>cd/data/zookeeper-3.4.10/conf
>cp zoo_sample.cfg zoo.cfg
>sudo nano zoo.cfg
dataDir=/home/neworigin/zookeeper
server.1=s100:2888:3888
server.2=s101:2888:3888
server.3=s102:2888:3888
server.X=host:port1:port2 的意思, X 表示当前 host 所运行的服务的zookeeper 服务的 id(在接下来填写 myid 时需要用到), port1 表示
zookeeper 中的 follower 连接到 leader 的端口号, port2 表示 leadership 时所用的端口号。
7.发送配置文件
>xsync zoo.cfg
8. 创建文件夹
>xcall mkdir -p /home/neworigin/zookeeper
>cd /home/neworigin/zookeeper
[s100]
>echo 1 > myid
[s101]
echo 2 > myid
[s102]
echo 3 > myid
文件内容为 zoo.cfg中 master 所对应的 server.X。
9. 启动集群(s100、s101、s102一起启动zk,尽量避免启动时间差距大)
>zkServer.sh start
>xcall jps查看进程
------------s100-----------------
3862 QuorumPeerMain
4351 Jps
------------s101-----------------
3650 QuorumPeerMain
3980 Jps
------------s102-----------------
3961 Jps
3791 QuorumPeerMain
------------s103-----------------
3883 Jps
[查看状态 leader or follower]
>zkServer.sh status
[暂停]
>zkServer.sh stop
10. 一台服务器上 都要删除之前Hadoop的目录 /home/neworigin/hadoop,重新创建
>xcall rm -rf /h ome/neworigin/hadoop
>xcall mkdir -p /home/neworigin/hadoop
11. 修改hadoop配置
[/data/hadoop-2.7.0/etc/hadoop/hdfs-site.xml]
<property> -----》配置nameservice
<name>dfs.nameservices</name>
<value>neworigin</value>
</property>
<property>
<name>dfs.ha.namenodes.neworigin</name>
<value>nn1,nn2</value>
</property>
<property> -----》RPC请求地址
<name>dfs.namenode.rpc-address.neworigin.nn1</name>
<value>s100:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.neworigin.nn2</name>
<value>s101:9000</value>
</property>
<property> -----》指定http地址
<name>dfs.namenode.http-address.neworigin.nn1</name>
<value>s100:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.neworigin.nn2</name>
<value>s101:50070</value>
</property>
<property> -------》配置JN集群
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://s101:8485;s102:8485;s103:8485/neworigin</value>
</property>
<property> -------》配置代理故障迁移
<name>dfs.client.failover.proxy.provider.neworigin</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property> ------》免密钥私钥文件
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/neworigin/.ssh/id_dsa</value>(如果是第二种免密钥方法用/root/.ssh/id_rsa)
</property>
<property> ------》JN中edits存放目录(格式化是会帮助自动创建)
<name>dfs.journalnode.edits.dir</name>
<value>/home/neworigin/journal/data</value>
</property>
<property> -----》启动高可用的故障迁移,不写默认false
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
[core-site.xml]
<property>
<name>fs.defaultFS</name>
<value>hdfs://neworigin</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/neworigin/hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>s100:2181,s101:2181,s102:2181</value>
</property>
(1) dfs.nameservices
HDFS 命名服务的逻辑名称,可用户自己定义,比如 mycluster,注意,该名称将被基于 HDFS 的系统使用,比如 Hbase 等,此外,需要你想启用 HDFS Federation,可以通过该参数指定多个逻辑名称,并用“,”分割。
(2) dfs.ha.namenodes.[$nameservice ID]:
某个命名服务下包含的NameNode 列表,可为每个 NameNode 指定一个自定义的 ID 名称,比如命名服务 nn 下有两个 NameNode,分别命名为 nn1 和 nn2
(3)dfs.namenode.rpc-address.[$nameservice ID].[$name node ID]
为每个 NameNode 设置 RPC 地址
(4) dfs.namenode.http-address.[$nameservice ID].[$name node ID]
为每个 NameNode 设置对外的 HTTP 地址
(5) dfs.namenode.shared.edits.dir
设置一组journalNode 的 URI 地址,active NameNode 将 edit log 写入这些JournalNode,而 standby NameNode 读取这些 edit log,并作用在内存中的目录树中,该属性值应符合以下格式:
[qjournal://host1:port1;host2:port2;host3:port3/journalId]
其中,journalId 是该命名空间的唯一 ID。
(6) dfs.client.failover.proxy.provider.[$nameservice ID]
设置客户端与 activeNameNode 进行交互的 Java 实现类,DFS 客户端通过该类寻找当前的 active NameNode。该类可由用户自己实现,默认实现为 ConfiguredFailoverProxyProvider。
(7) dfs.ha.fencing.methods
主备架构解决单点故障问题时,必须要认真解决的是脑裂问题,即出现两个 master 同时对外提供服务,导致系统处于不一致状态,可能导致数据丢失等潜在问题。在 HDFS HA 中,JournalNode 只允许一个 NameNode 写数据,不会出现两个 active NameNode 的问题, 但是,当主备切换时,之前的 active NameNode 可能仍在处理客户端的 RPC 请求,为此, 需要增加隔离机制(fencing)将之前的 active NameNode 杀死。
HDFS 允许用户配置多个隔离机制,当发生主备切换时,将顺次执行这些隔离机制,直到一个返回成功。Hadoop 2.0 内部打包了两种类型的隔离机制,分别是 shell 和 sshfence。
1) sshfence
sshfence 通过 ssh 登录到前一个 active NameNode 并将其杀死。为了让该机制成功执行,
需配置免密码 ssh 登陆,这可通过参数 dfs.ha.fencing.ssh.private-key-files 设置一个私钥文件。
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
你可以配置一个 ssh 用户和端口号,并设置一个超时时间,一旦 ssh 超过该时间,则认为执 行失败。
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[username][:port]])</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
2) shell
执行任意一个 shell 命令隔离旧的 active NameNode,配置方法如下:
<property>
<name>dfs.ha.fencing.methods</name>
[html] view plain copy
<value>shell(/path/to/my/script.sh arg1 arg2 ...)</value>
</property>
注意,Hadoop 中所有参数将以环境变量的形似提供给该 shell,但所有的“.”被替换成了“_”, 比如“dfs.namenode.rpc-address.ns1.nn1”变为“dfs_namenode_rpc-address”
(8) fs.defaultFS
设置缺省的目录前缀,需在core-site.xml 中设置,比如命名服务的 ID 为 mycluster(参数 dfs.nameservices 指定的),则配置如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://nn</value>
</property>
(9) dfs.journalnode.edits.dir
JournalNode 所在节点上的一个目录,用于存放 editlog 和其他状态信息。该参数只能设置一个目录,你可以对磁盘做 RIAD 提高数据可靠性。
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journal/node/local/data</value>
</property>
12.三台JN 上启动JN集群服务(s101、s102、s103)
>hadoop-daemon.shstart journalnode
>xcalljps
------------s100-----------------
4363 Jps
3421 QuorumPeerMain
------------s101-----------------
4034 JournalNode
4227 Jps
3118 QuorumPeerMain
------------s102-----------------
3105 QuorumPeerMain
4210 Jps
4015 JournalNode
------------s103-----------------
3392 JournalNode
3592 Jps
11.找一台NN 执行格式化----->前提是jouralnode启动无问题,保证/opt/hadoop目录为空
S100:
>hdfsnamenode -format
此时可以进入JN集群查看edits文件,如果有就说明NN将edits交由JN管理
启动当前NN:
>hadoop-daemon.shstart namenode
>jps
12. 在没有格式化的NN上 执行同步命令
s101:
hdfsnamenode -bootstrapStandby(同步已经格式化的nameNode)
13. 格式ZK-----保证zk集群已经启动起来
s100:
>hdfs zkfc-formatZK
14. 启动集群
s100:
>start-dfs.sh
>jps
15. 测试
s100:50070------>s100:8020(active)
s101:50070------>s101:8020(standby)
停止s100:hadoop-daemon.sh stop namenode
查看状态
>hdfs haadmin-getServiceState nn1
>hdfs haadmin-getServiceState nn2
状态转换
>hdfs haadmin-transitionToActive nn1
>hdfs haadmin-transitionToStandby nn2
s100:50070(页面加载失败)
s101:50070------>s101:8020(active)
s100再启动
s100:50070------->node01:8020(standby)
16.错误分析:
两台namenode都是standby:查看zkfc的日志
cd /data/hadoop-2.7.0/logs
17.连接缓冲区:zkCli.sh
查看:ls/hadoop-ha
查看节点:get/hadoop-ha/neworigin---------->neworigin为nameservice
取消连接:quit
二.Hdfs HA MR
NN DN ZK JN ZKFC RS NMs100 1 1 1
s101 1 1 1 1 1 1
s102 1 1 1 1 1
s103 1 1 1 1
停止以上集群:
s100:
>stop-dfs.sh
>jps
配置s100:
[mapred-site.xml]
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
[yarn-site.xml]
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
Yarn rm高可用:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>s102</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>s103</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>s100:2181,s101:2181,s102:2181</value>
</property>
同步所有配置:
s100 :
> xsync /data/hadoop-2.7.0/etc/hadoop/
注意:slaves是dateNode的配置,又是nodeManager的配置。
s100:
>start-all.sh
s102和s103:
>yarn-daemon.sh start resourcemanager(单独启动resourcemanager)
s103:
netstat -npl | grep java(查看端口)
测试:s102:8088
s103:8088
(一台standBy状态的rm自动跳到active状态的rm)
{再开启:一:s100、s101、s102一起启动zk
zkServer.sh start}
二: s100:start-all.sh
三:s102和s103:
yarn-daemon.sh startresourcemanager(单独启动resourcemanager)}
8890
1.集群规划:
主机名 IP 安装的软件
运行的进程
drguo1 192.168.80.149 jdk、hadoop
NameNode、DFSZKFailoverController(zkfc)、ResourceManager
drguo2 192.168.80.150 jdk、hadoop
NameNode、DFSZKFailoverController(zkfc)、ResourceManager
drguo3 192.168.80.151 jdk、hadoop、zookeeper
DataNode、NodeManager、JournalNode、QuorumPeerMain
drguo4 192.168.80.152 jdk、hadoop、zookeeper
DataNode、NodeManager、JournalNode、QuorumPeerMain
drguo5 192.168.80.153 jdk、hadoop、zookeeper
DataNode、NodeManager、JournalNode、QuorumPeerMain
排的好好的,显示出来就乱了!!!

2.前期准备:
准备五台机器,修改静态IP、主机名、主机名与IP的映射,关闭防火墙,安装JDK并配置环境变量(不会请看这http://blog.csdn.net/dr_guo/article/details/50886667),创建用户:用户组,SSH免密码登录SSH免密码登录(报错请看这http://blog.csdn.net/dr_guo/article/details/50967442)。
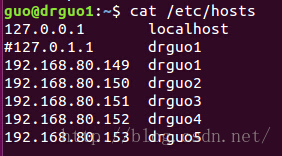
注意:要把127.0.1.1那一行注释掉,要不然会出现jps显示有datanode,但网页显示live nodes为0;
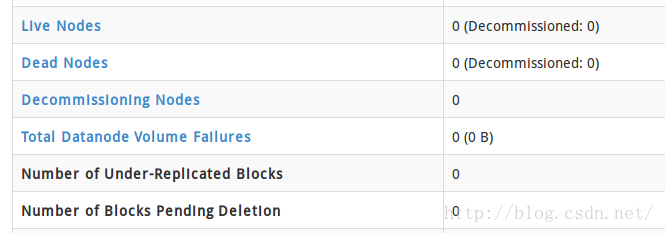
注释之后就正常了,好像有人没注释也正常,我也不知道为什么0.0
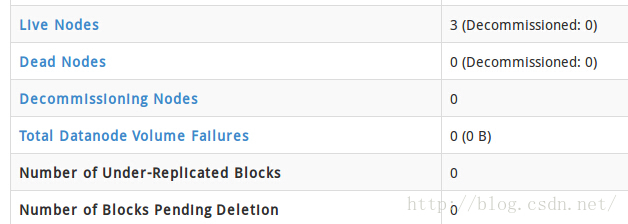
3.搭建zookeeper集群(drguo3/drguo4/drguo5)
见:ZooKeeper完全分布式集群搭建
4.正式开始搭建Hadoop HA集群
去官网下最新的Hadoop(http://apache.opencas.org/hadoop/common/stable/),目前最新的是2.7.2,下载完之后把它放到/opt/Hadoop下
[plain] view
plain copy
guo@guo:~/下载$ mv ./hadoop-2.7.2.tar.gz /opt/Hadoop/
mv: 无法创建普通文件"/opt/Hadoop/hadoop-2.7.2.tar.gz": 权限不够
guo@guo:~/下载$ su root
密码:
root@guo:/home/guo/下载# mv ./hadoop-2.7.2.tar.gz /opt/Hadoop/
解压
[plain] view
plain copy
guo@guo:/opt/Hadoop$ sudo tar -zxf hadoop-2.7.2.tar.gz
[sudo] guo 的密码:
解压jdk的时候我用的是tar -zxvf,其中的v呢就是看一下解压的过程,不想看你可以不写。
修改opt目录所有者(用户:用户组)直接把opt目录的所有者/组换成了guo。具体情况在ZooKeeper完全分布式集群搭建说过。
[plain] view
plain copy
root@guo:/opt/Hadoop# chown -R guo:guo /opt
设置环境变量
[plain] view
plain copy
guo@guo:/opt/Hadoop$ sudo gedit /etc/profile
在最后加上(这样设置在执行bin/sbin目录下的脚本时就不用进入该目录用了)
[plain] view
plain copy
#hadoop
export HADOOP_HOME=/opt/Hadoop/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
然后更新配置
[plain] view
plain copy
guo@guo:/opt/Hadoop$ source /etc/profile
修改/opt/Hadoop/hadoop-2.7.2/etc/hadoop下的hadoop-env.sh
[plain] view
plain copy
guo@guo:/opt/Hadoop$ cd hadoop-2.7.2
guo@guo:/opt/Hadoop/hadoop-2.7.2$ cd etc/hadoop/
guo@guo:/opt/Hadoop/hadoop-2.7.2/etc/hadoop$ sudo gedit ./hadoop-env.sh
进入文件后
[plain] view
plain copy
export JAVA_HOME=${JAVA_HOME}#将这个改成JDK路径,如下
export JAVA_HOME=/opt/Java/jdk1.8.0_73
然后更新文件配置
[plain] view
plain copy
guo@guo:/opt/Hadoop/hadoop-2.7.2/etc/hadoop$ source ./hadoop-env.sh
前面配置和单机模式一样,我就直接复制了。
注意:汉语注释是给你看的,复制粘贴的时候都删了!!!
修改core-site.xml
[html] view
plain copy
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/Hadoop/hadoop-2.7.2/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>drguo3:2181,drguo4:2181,drguo5:2181</value>
</property>
</configuration>
修改hdfs-site.xml
[html] view
plain copy
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>drguo1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>drguo1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>drguo2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>drguo2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://drguo3:8485;drguo4:8485;drguo5:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/Hadoop/hadoop-2.7.2/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/guo/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
先将mapred-site.xml.template改名为mapred-site.xml然后修改mapred-site.xml
[html] view
plain copy
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
[html] view
plain copy
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>drguo1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>drguo2</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>drguo3:2181,drguo4:2181,drguo5:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves
[html] view
plain copy
drguo3
drguo4
drguo5
把Hadoop整个目录拷贝到drguo2/3/4/5,拷之前把share下doc删了(文档不用拷),这样会快点。
5.启动zookeeper集群(分别在drguo3、drguo4、drguo5上启动zookeeper)
[plain] view
plain copy
guo@drguo3:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
guo@drguo3:~$ jps
2005 Jps
1994 QuorumPeerMain
guo@drguo3:~$ ssh drguo4
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Fri Mar 25 14:04:43 2016 from 192.168.80.151
guo@drguo4:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
guo@drguo4:~$ jps
1977 Jps
1966 QuorumPeerMain
guo@drguo4:~$ exit
注销
Connection to drguo4 closed.
guo@drguo3:~$ ssh drguo5
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Fri Mar 25 14:04:56 2016 from 192.168.80.151
guo@drguo5:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
guo@drguo5:~$ jps
2041 Jps
2030 QuorumPeerMain
guo@drguo5:~$ exit
注销
Connection to drguo5 closed.
guo@drguo3:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: leader
6.启动journalnode(分别在drguo3、drguo4、drguo5上启动journalnode)注意只有第一次需要这么启动,之后启动hdfs会包含journalnode。
[plain] view
plain copy
guo@drguo3:~$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/Hadoop/hadoop-2.7.2/logs/hadoop-guo-journalnode-drguo3.out
guo@drguo3:~$ jps
2052 Jps
2020 JournalNode
1963 QuorumPeerMain
guo@drguo3:~$ ssh drguo4
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Fri Mar 25 00:09:08 2016 from 192.168.80.149
guo@drguo4:~$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/Hadoop/hadoop-2.7.2/logs/hadoop-guo-journalnode-drguo4.out
guo@drguo4:~$ jps
2103 Jps
2071 JournalNode
1928 QuorumPeerMain
guo@drguo4:~$ exit
注销
Connection to drguo4 closed.
guo@drguo3:~$ ssh drguo5
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Thu Mar 24 23:52:17 2016 from 192.168.80.152
guo@drguo5:~$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/Hadoop/hadoop-2.7.2/logs/hadoop-guo-journalnode-drguo5.out
guo@drguo5:~$ jps
2276 JournalNode
2308 Jps
1959 QuorumPeerMain
guo@drguo5:~$ exit
注销
Connection to drguo5 closed.
在drguo4/5启动时发现了问题,没有journalnode,查看日志发现是因为汉语注释造成的,drguo4/5全删了问题解决。drguo4/5的拼音输入法也不能用,我很蛋疼。。镜像都是复制的,咋还变异了呢。
7.格式化HDFS(在drguo1上执行)
[plain] view
plain copy
guo@drguo1:/opt$ hdfs namenode -format
这回又出问题了,还是汉语注释闹得,drguo1/2/3也全删了,问题解决。
注意:格式化之后需要把tmp目录拷给drguo2(不然drguo2的namenode起不来)
[plain] view
plain copy
guo@drguo1:/opt/Hadoop/hadoop-2.7.2$ scp -r tmp/ drguo2:/opt/Hadoop/hadoop-2.7.2/
8.格式化ZKFC(在drguo1上执行)
[plain] view
plain copy
guo@drguo1:/opt$ hdfs zkfc -formatZK
9.启动HDFS(在drguo1上执行)
[plain] view
plain copy
guo@drguo1:/opt$ start-dfs.sh
10.启动YARN(在drguo1上执行)
[plain] view
plain copy
guo@drguo1:/opt$ start-yarn.sh
PS:
1.drguo2的resourcemanager需要手动单独启动:
yarn-daemon.sh start resourcemanager
2.namenode、datanode也可以单独启动:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
3.NN 由standby转化成active
hdfs haadmin -transitionToActive nn1 --forcemanual
大功告成!!!
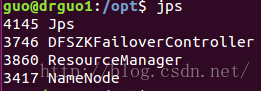
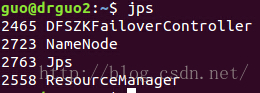
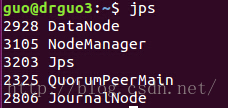
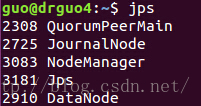
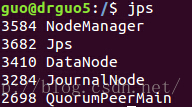
是不是和之前规划的一样0.0

相关文章推荐
- Centos 6.5 下hadoop2.5.2的HA集群原理讲解以及详细配置(自动切换)
- Hive安装配置以及整合HBase和hadoop
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
- Hadoop2.3、 Hbase0.98、 Hive0.13架构中Hive的安装部署配置以及数据测试
- 大数据之linux环境下jdk hadoop以及hbase,hive等配置
- 修改端口Tomcat配置https协议、以及http协议自动REDIRECT到HTTPS-java教程
- hadoop2.2.0(单节点)下Sqoop-1.4.6安装与配置(数据读取涉及hadoop、hbase和hive)
- Hadoop+Hbase+Spark集群配置—Hadoop HA安装
- cm-5.13下配置hbase客户端,hive客户端,hadoop客户端,spark客户端
- Centos 6.5 下hadoop2.5.2的HA集群原理讲解以及详细配置(手动切换)
- 在Hadoop2.2的HA环境下配置Hbase0.96
- hadoop+hive+hbase的整合开发(配置加测试)
- Hadoop 2.7.2 HA 自动切换高可用集群配置详解
- hadoop中配置Hbase和Hive(oracle)错误
- 配置hadoop,hive,hbase
- hadoop做HA后,hbase修改
- 关于几种压缩算法以及hadoop和hbase中的压缩配置说明[转]
- hadoop入门之与hive及hbase集成配置
- hadoop-spark-hive-hbase配置相关说明
- hadoop+hive+zookeeper+hbase全分布式环境配置